A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 11
Volume 11
Issue 11
IEEE/CAA Journal of Automatica Sinica
| Citation: | M. Yang, G. Liu, Z. Zhou, and J. Wang, “Probabilistic automata-based method for enhancing performance of deep reinforcement learning systems,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 11, pp. 2327–2339, Nov. 2024. doi: 10.1109/JAS.2024.124818

|
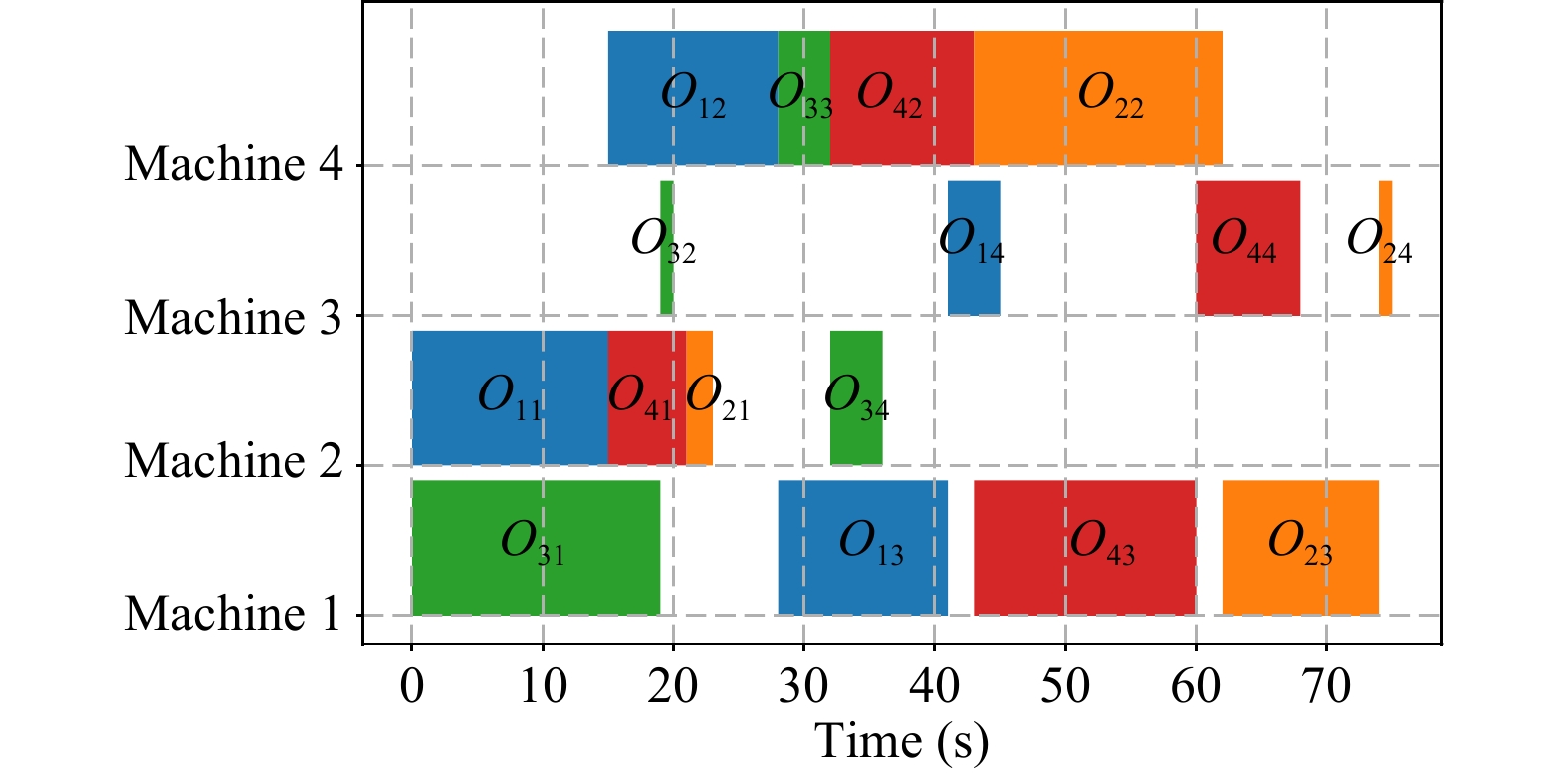
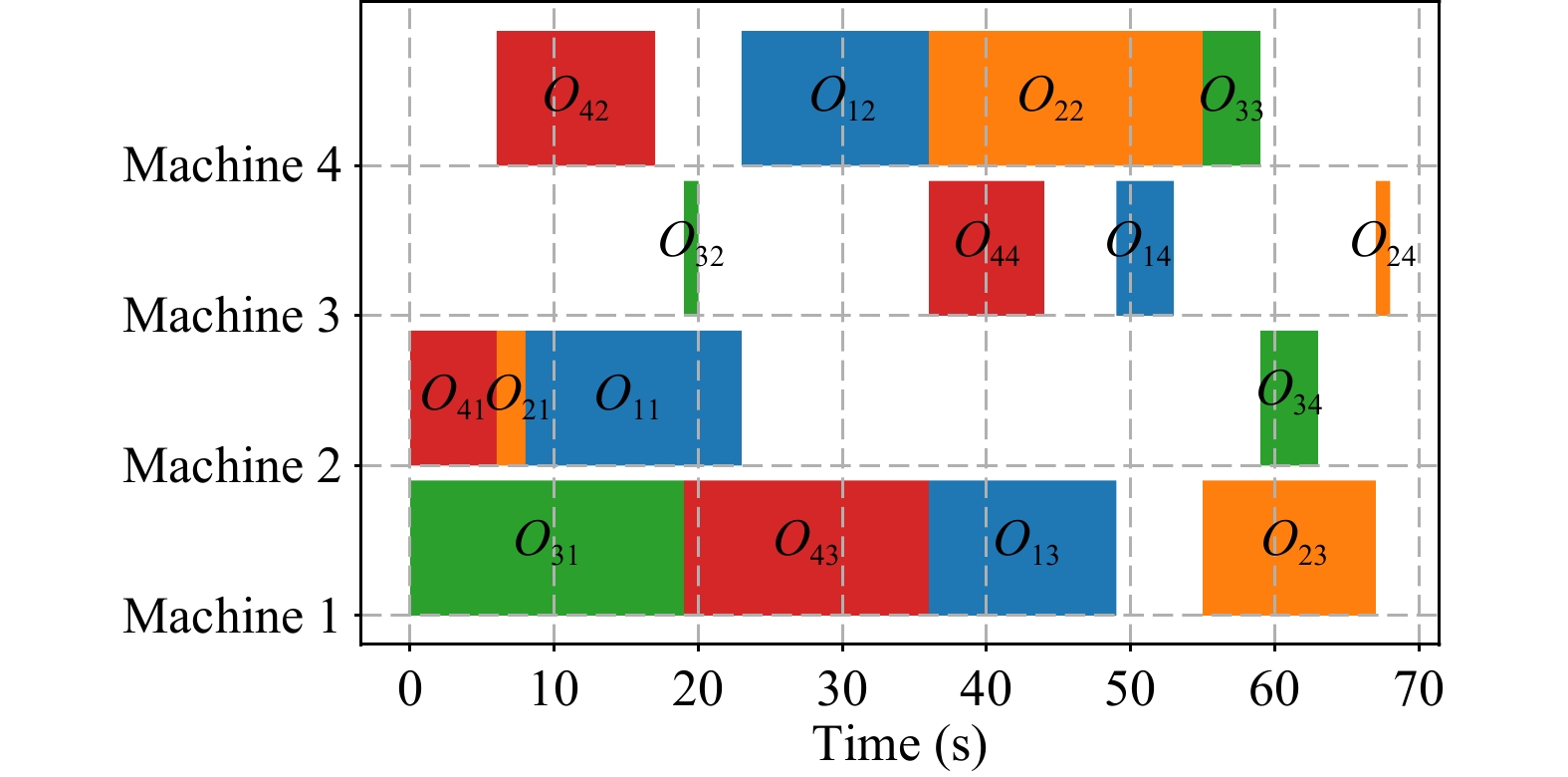
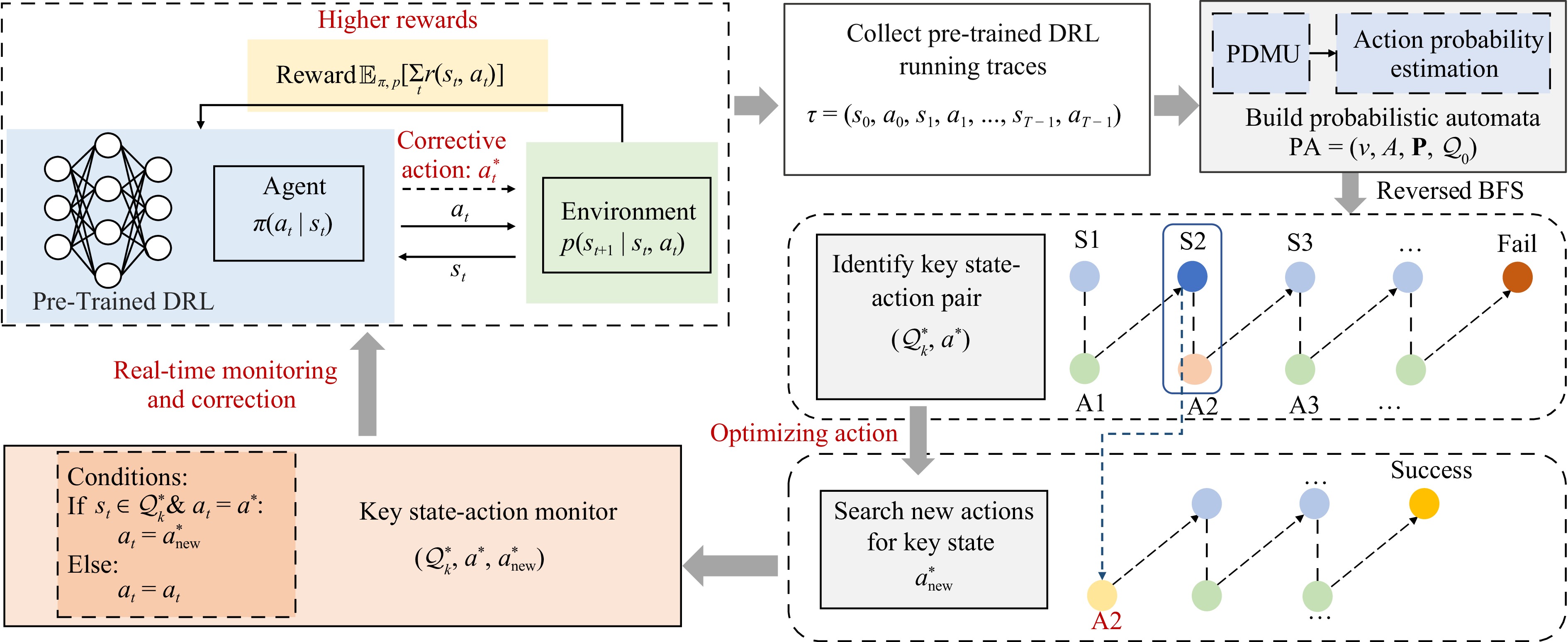
Deep reinforcement learning (DRL) has demonstrated significant potential in industrial manufacturing domains such as workshop scheduling and energy system management. However, due to the model’s inherent uncertainty, rigorous validation is requisite for its application in real-world tasks. Specific tests may reveal inadequacies in the performance of pre-trained DRL models, while the “black-box” nature of DRL poses a challenge for testing model behavior. We propose a novel performance improvement framework based on probabilistic automata, which aims to proactively identify and correct critical vulnerabilities of DRL systems, so that the performance of DRL models in real tasks can be improved with minimal model modifications. First, a probabilistic automaton is constructed from the historical trajectory of the DRL system by abstracting the state to generate probabilistic decision-making units (PDMUs), and a reverse breadth-first search (BFS) method is used to identify the key PDMU-action pairs that have the greatest impact on adverse outcomes. This process relies only on the state-action sequence and final result of each trajectory. Then, under the key PDMU, we search for the new action that has the greatest impact on favorable results. Finally, the key PDMU, undesirable action and new action are encapsulated as monitors to guide the DRL system to obtain more favorable results through real-time monitoring and correction mechanisms. Evaluations in two standard reinforcement learning environments and three actual job scheduling scenarios confirmed the effectiveness of the method, providing certain guarantees for the deployment of DRL models in real-world applications.

| [1] |
Z. Zhou, G. Liu, and Y. Tang, “Multi-agent reinforcement learning: Methods, applications, visionary prospects, and challenges,” arXiv preprint arXiv: 2305.10091, 2023.
|
| [2] |
Z. Zhou, G. Liu, and M. Zhou, “A robust mean-field actor-critic reinforcement learning against adversarial perturbations on agent states,” IEEE Trans. Neural Netw. Learn. Syst., 2023. DOI: 10.1109/TNNLS.2023.3278715.
|
| [3] |
J. Gu, J. Wang, X. Guo, G. Liu, S. Qin, and Z. Bi, “A metaverse-based teaching building evacuation training system with deep reinforcement learning,” IEEE Trans. Syst. Man Cybern. Syst., vol. 53, no. 4, pp. 2209–2219, Apr. 2023. doi: 10.1109/TSMC.2022.3231299
|
| [4] |
E. K. Elsayed, A. K. Elsayed, and K. A. Eldahshan, “Deep reinforcement learning-based job shop scheduling of smart manufacturing,” Comput. Mater. Contin., vol. 73, no. 3, pp. 5103–5120, Jul. 2022.
|
| [5] |
C. Zhang, W. Song, Z. Cao, J. Zhang, P. S. Tan, and X. Chi, “Learning to dispatch for job shop scheduling via deep reinforcement learning,” in Proc. 34th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2020, pp. 1621–1632.
|
| [6] |
C. W. de Puiseau, J. Peters, C. Dörpelkus, H. Tercan, and T. Meisen, “Schlably: A python framework for deep reinforcement learning based scheduling experiments,” SoftwareX, vol. 22, p. 101383, May 2023. doi: 10.1016/j.softx.2023.101383
|
| [7] |
X. Xu, Y. Lu, B. Vogel-Heuser, and L. Wang, “Industry 4.0 and Industry 5.0—Inception, conception and perception,” J. Manuf. Syst., vol. 61, pp. 530–535, Oct. 2021. doi: 10.1016/j.jmsy.2021.10.006
|
| [8] |
A. del Real Torres, D. S. Andreiana, A. Ojeda Roldan, A. Hernández Bustos, and L. E. Acevedo Galicia, “A review of deep reinforcement learning approaches for smart manufacturing in Industry 4.0 and 5.0 framework,” Appl. Sci., vol. 12, no. 23, p. 12377, Dec. 2022. doi: 10.3390/app122312377
|
| [9] |
T.-C. T. Chen, “Explainable artificial intelligence (XAI) in manufacturing,” in Explainable Artificial Intelligence (XAI) in Manufacturing: Methodology, Tools, and Applications, T.-C. T. Chen, Ed. Cham, Germany: Springer, 2023, pp. 1–11.
|
| [10] |
K. Pei, Y. Cao, J. Yang, and S. Jana, “DeepXplore: Automated whitebox testing of deep learning systems,” in Proc. 26th Symp. Operating Systems Principles, Shanghai, China, 2017, pp. 1–18.
|
| [11] |
J. M. Zhang, M. Harman, L. Ma, and Y. Liu, “Machine learning testing: Survey, landscapes and horizons,” IEEE Trans. Software Eng., vol. 48, no. 1, pp. 1–36, Jan. 2020.
|
| [12] |
P. Jin, Y. Wang, and M. Zhang, “Efficient LTL model checking of deep reinforcement learning systems using policy extraction,” in Proc. 34th Int. Conf. Software Engineering and Knowledge Engineering, 2022, pp. 357–362.
|
| [13] |
P. Jin, J. Tian, D. Zhi, X. Wen, and M. Zhang, “TRAINIFY: A CEGAR-driven training and verification framework for safe deep reinforcement learning,” in Proc. 34th Int. Conf. Computer Aided Verification, Haifa, Israel, 2022, pp. 193–218.
|
| [14] |
Y. Lu, W. Sun, and M. Sun, “Towards mutation testing of reinforcement learning systems,” J. Syst. Archit., vol. 131, p. 102701, Oct. 2022. doi: 10.1016/j.sysarc.2022.102701
|
| [15] |
W. Guo, X. Wu, U. Khan, and X. Xing, “EDGE: Explaining deep reinforcement learning policies,” in Proc. 35th Conf. Neural Infor. Processing Syst., 2021, pp. 12222–12236.
|
| [16] |
M. Yang, G. Liu, Z. Zhou, and J. Wang, “Partially observable mean field multi-agent reinforcement learning based on graph attention network for UAV swarms,” Drones, vol. 7, no. 7, p. 476, Jul. 2023. doi: 10.3390/drones7070476
|
| [17] |
H. Shi, G. Liu, K. Zhang, Z. Zhou, and J. Wang, “MARL Sim2real transfer: Merging physical reality with digital virtuality in metaverse,” IEEE Trans. Syst. Man Cybern. Syst., vol. 53, no. 4, pp. 2107–2117, Apr. 2023. doi: 10.1109/TSMC.2022.3229213
|
| [18] |
J. Xue, Z. Liu, G. Liu, Z. Zhou, K. Zhang, Y. Tang, and J. Wang, “Robust wind-resistant hovering control of quadrotor UAVs using deep reinforcement learning,” IEEE Trans. Intell. Veh., 2023. DOI: 10.1109/TIV.2023.3324687.
|
| [19] |
Y. Liu, A. Halev, and X. Liu, “Policy learning with constraints in model-free reinforcement learning: A survey,” in Proc. 30th Int. Joint Conf. Artificial Intelligence, Montreal, Canada, 2021, pp. 4508–4515.
|
| [20] |
W. Chen, D. Subramanian, and S. Paternain, “Probabilistic constraint for safety-critical reinforcement learning,” IEEE Trans. Autom. Control, 2024. DOI: 10.1109/TAC.2024.3379246.
|
| [21] |
Y. Yang, Y. Jiang, Y. Liu, J. Chen, and S. E. Li, “Model-free safe reinforcement learning through neural barrier certificate,” IEEE Rob. Autom. Lett., vol. 8, no. 3, pp. 1295–1302, Mar. 2023. doi: 10.1109/LRA.2023.3238656
|
| [22] |
W. Zhao, T. He, and C. Liu, “Probabilistic safeguard for reinforcement learning using safety index guided Gaussian process models,” in Proc. 5th Annu. Learning for Dynamics and Control Conf., Philadelphia, USA, 2023, pp. 783–796.
|
| [23] |
S. Chen, G. Liu, Z. Zhou, K. Zhang, and J. Wang, “Robust multi-agent reinforcement learning method based on adversarial domain randomization for real-world dual-UAV cooperation,” IEEE Trans. Intell. Veh., vol. 9, no. 1, pp. 1615–1627, Jan. 2024. doi: 10.1109/TIV.2023.3307134
|
| [24] |
F. Tambon, V. Majdinasab, A. Nikanjam, F. Khomh, and G. Antoniol, “Mutation testing of deep reinforcement learning based on real faults,” in Proc. IEEE Conf. Software Testing, Verification and Validation, Dublin, Ireland, 2023, pp. 188–198.
|
| [25] |
Z. Li, X. Wu, D. Zhu, M. Cheng, S. Chen, F. Zhang, X. Xie, L. Ma, and J. Zhao, “Generative model-based testing on decision-making policies,” in Proc. 38th IEEE/ACM Int. Conf. Automated Software Engineering, Luxembourg, Luxembourg, 2023, pp. 243–254.
|
| [26] |
J. Morán, A. Bertolino, C. De La Riva, and J. Tuya, “Fault localization for reinforcement learning,” in Proc. IEEE Int. Conf. Artificial Intelligence Testing, Athens, Greece, 2023, pp. 49–50.
|
| [27] |
M. Tappler, F. C. Córdoba, B. K. Aichernig, and B. Könighofer, “Search-based testing of reinforcement learning,” in Proc. 31st Int. Joint Conf. Artificial Intelligence, Vienna, Austria, 2022, pp. 503–510.
|
| [28] |
M. Tappler, A. Pferscher, B. K. Aichernig, and B. Könighofer, “Learning and repair of deep reinforcement learning policies from fuzz-testing data,” in Proc. 46th IEEE/ACM Int. Conf. Software Engineering, Lisbon, Portugal, 2024, pp. 6.
|
| [29] |
S. Gu, L. Yang, Y. Du, G. Chen, F. Walter, J. Wang, and A. Knoll, “A review of safe reinforcement learning: Methods, theory and applications,” arXiv preprint arXiv: 2205.10330, 2024.
|
| [30] |
A. Atrey, K. Clary, and D. D. Jensen, “Exploratory not explanatory: Counterfactual analysis of saliency maps for deep reinforcement learning,” in Proc. 8th Int. Conf. Learning Representations, Addis Ababa, Ethiopia, 2020.
|
| [31] |
Y. Qing, S. Liu, J. Song, H. Wang, and M. Song, “A survey on explainable reinforcement learning: Concepts, algorithms, challenges,” arXiv preprint arXiv: 2211.06665, 2023.
|
| [32] |
M. Finkelstein, L. Liu, N. L. Schlot, Y. Kolumbus, D. C. Parkes, J. S. Rosenschein, and S. Keren, “Explainable reinforcement learning via model transforms,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2024, pp. 34039–34051.
|
| [33] |
P. Sequeira and M. Gervasio, “Interestingness elements for explainable reinforcement learning: Understanding agents’ capabilities and limitations,” Artif. Intell., vol. 288, p. 103367, Nov. 2020. doi: 10.1016/j.artint.2020.103367
|
| [34] |
B. Delahaye, J. P. Katoen, K. G. Larsen, A. Legay, M. L. Pedersen, F. Sher, and A. Wçasowski, “Abstract probabilistic automata,” in Proc. 12th Int. Conf. Verification, Model Checking, and Abstract Interpretation, Austin, USA, 2011, pp. 324–339.
|
| [35] |
A. Sokolova and E. P. De Vink, “Probabilistic automata: System types, parallel composition and comparison,” Validation of Stochastic Systems: A Guide to Current Research, C. Baier, B. R. Haverkort, H. Hermanns, J. P. Katoen, and M. Siegle, Eds. Berlin, Germany: Springer, 2004, pp. 1–43.
|
| [36] |
P. El Mqirmi, F. Belardinelli, and B. G. León, “An abstraction-based method to check multi-agent deep reinforcement-learning behaviors,” in Proc. 20th Int. Conf. Autonomous Agents and MultiAgent Systems, 2021, pp. 474–482.
|
| [37] |
E. Bacci and D. Parker, “Probabilistic guarantees for safe deep reinforcement learning,” in Proc. 18th Int. Conf. Formal Modeling and Analysis of Timed Systems, Vienna, Austria, 2020, pp. 231–248.
|
| [38] |
R. Haupt, “A survey of priority rule-based scheduling,” Oper. Res. Spekt., vol. 11, no. 1, pp. 3–16, Mar. 1989. doi: 10.1007/BF01721162
|
| [39] |
B.-A. Han and J.-J. Yang, “Research on adaptive job shop scheduling problems based on dueling double DQN,” IEEE Access, vol. 8, pp. 186474–186495, Jan. 2020. doi: 10.1109/ACCESS.2020.3029868
|
| [40] |
R. Chen, W. Li, and H. Yang, “A deep reinforcement learning framework based on an attention mechanism and disjunctive graph embedding for the job-shop scheduling problem,” IEEE Trans. Ind. Inf., vol. 19, no. 2, pp. 1322–1331, Feb. 2023. doi: 10.1109/TII.2022.3167380
|
| [41] |
B. Cunha, A. M. Madureira, B. Fonseca, and D. Coelho, “Deep reinforcement learning as a job shop scheduling solver: A literature review,” in Proc. 18th Int. Conf. Hybrid Intelligent Systems, Porto, Portugal, 2020, pp. 350–359.
|
| [42] |
A. M. Ali and L. Tirel, “Action masked deep reinforcement learning for controlling industrial assembly lines,” in Proc. IEEE World AI IoT Congr., Seattle, USA, 2023, pp. 797–803.
|
| [43] |
A. Narayanan, E. Pournaras, and P. H. J. Nardelli, “Collective learning for energy-centric flexible job shop scheduling,” in Proc. IEEE 32nd Int. Symp. Industrial Electronics, Helsinki, Finland, 2023, pp. 1–6.
|
| [44] |
J. A. Arjona-Medina, M. Gillhofer, M. Widrich, T. Unterthiner, J. Brandstetter, and S. Hochreiter, “RUDDER: Return decomposition for delayed rewards,” in Proc. 33rd Conf. Neural Infor. Processing Syst., Vancouver, Canada, 2019, pp. 13544–13555.
|
| [45] |
A. A. Ismail, M. Gunady, L. Pessoa, H. Corrada Bravo, and S. Feizi, “Input-cell attention reduces vanishing saliency of recurrent neural networks,” in Proc. 33rd Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2019, pp. 10813–10823.
|
| [46] |
D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint arXiv: 1409.0473, 2016.
|
| [47] |
T. Lei, R. Barzilay, and T. Jaakkola, “Rationalizing neural predictions,” in Proc. Conf. Empirical Methods in Natural Language Processing, Austin, Texas, 2016, pp. 107–117.
|
| [48] |
J. Adebayo, J. Gilmer, M. Muelly, I. Goodfellow, M. Hardt, and B. Kim, “Sanity checks for saliency maps,” in Proc. 32nd Int. Conf. Neural Infor. Processing Syst., Red Hook, USA, 2018, 9525–9536.
|
| [49] |
G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “OpenAI gym,” arXiv preprint arXiv: 1606.01540, 2016.
|
| [50] |
E. D. Taillard, “Benchmarks for basic scheduling problems,” Eur. J. Oper. Res., vol. 64, no. 2, pp. 278–285, Jan. 1993. doi: 10.1016/0377-2217(93)90182-M
|
| [51] |
J. Moos, K. Hansel, H. Abdulsamad, S. Stark, D. Clever, and J. Peters, “Robust reinforcement learning: A review of foundations and recent advances,” Mach. Learn. Knowl. Extr., vol. 4, no. 1, pp. 276–315, Mar. 2022. doi: 10.3390/make4010013
|
| [52] |
Z. Zhou and G. Liu, “Robustness testing for multi-agent reinforcement learning: State perturbations on critical agents,” in Proc. 26th European Conf. Artificial Intelligence, 2023, vol. 372, pp. 3131–3139.
|
| [53] |
W. Guo, G. Liu, Z. Zhou, L. Wang, and J. Wang, “Enhancing the robustness of QMIX against state-adversarial attacks,” Neurocomputing, vol. 572, p. 127191, Mar. 2024. doi: 10.1016/j.neucom.2023.127191
|
Figures(7) / Tables(6)






 DownLoad:
DownLoad: