A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 10
Issue 12
Volume 10
Issue 12
IEEE/CAA Journal of Automatica Sinica
| Citation: | H. Y. Ding, Y. Z. Tang, Q. Wu, B. Wang, C. L. Chen, and Z. Wang, “Magnetic field-based reward shaping for goal-conditioned reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 12, pp. 2233–2247, Dec. 2023. doi: 10.1109/JAS.2023.123477

|
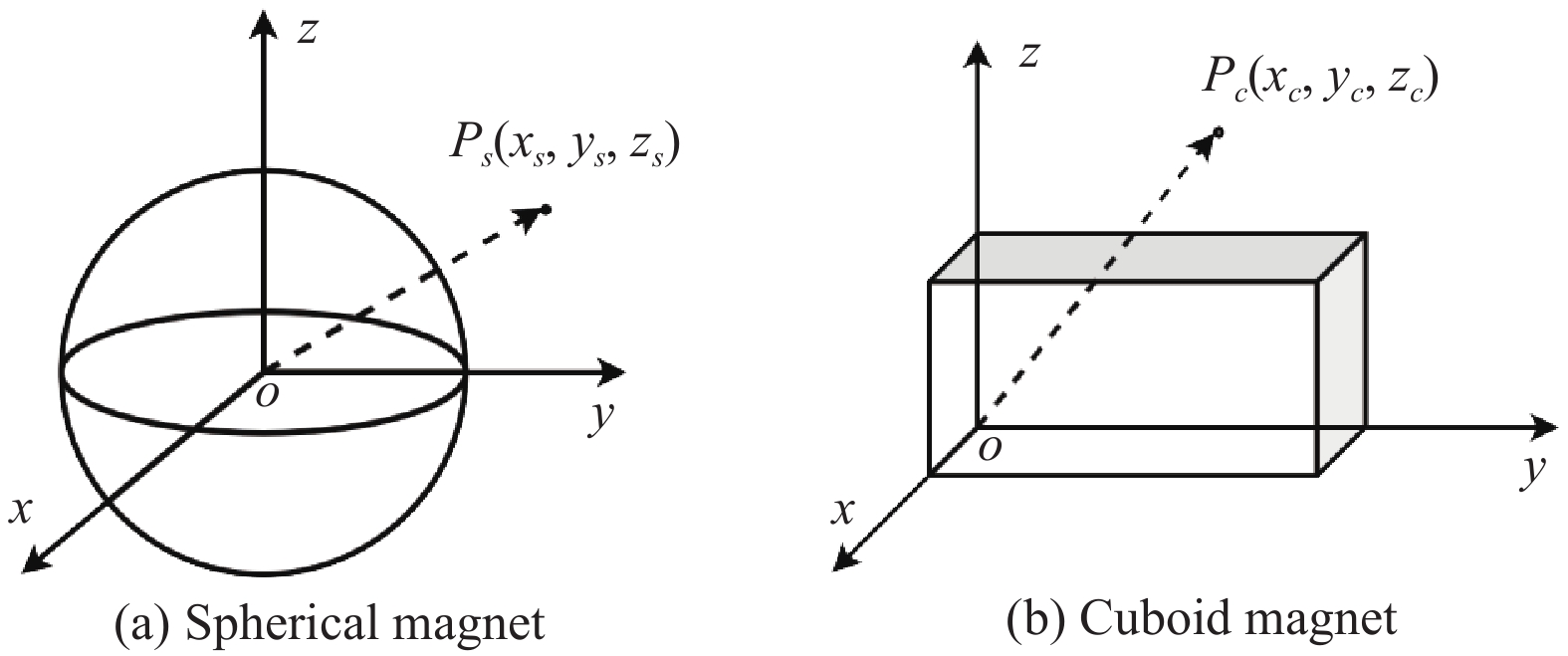
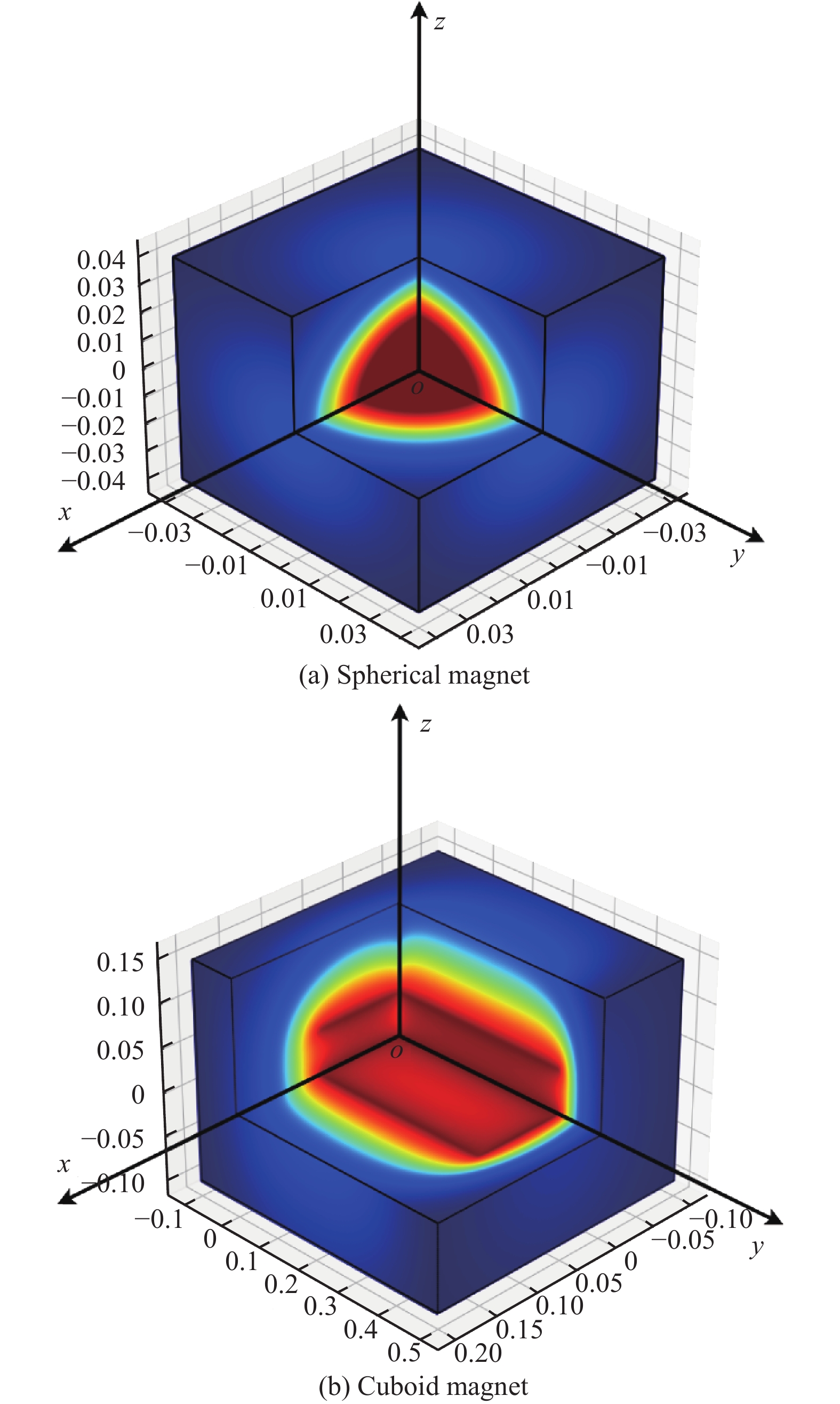
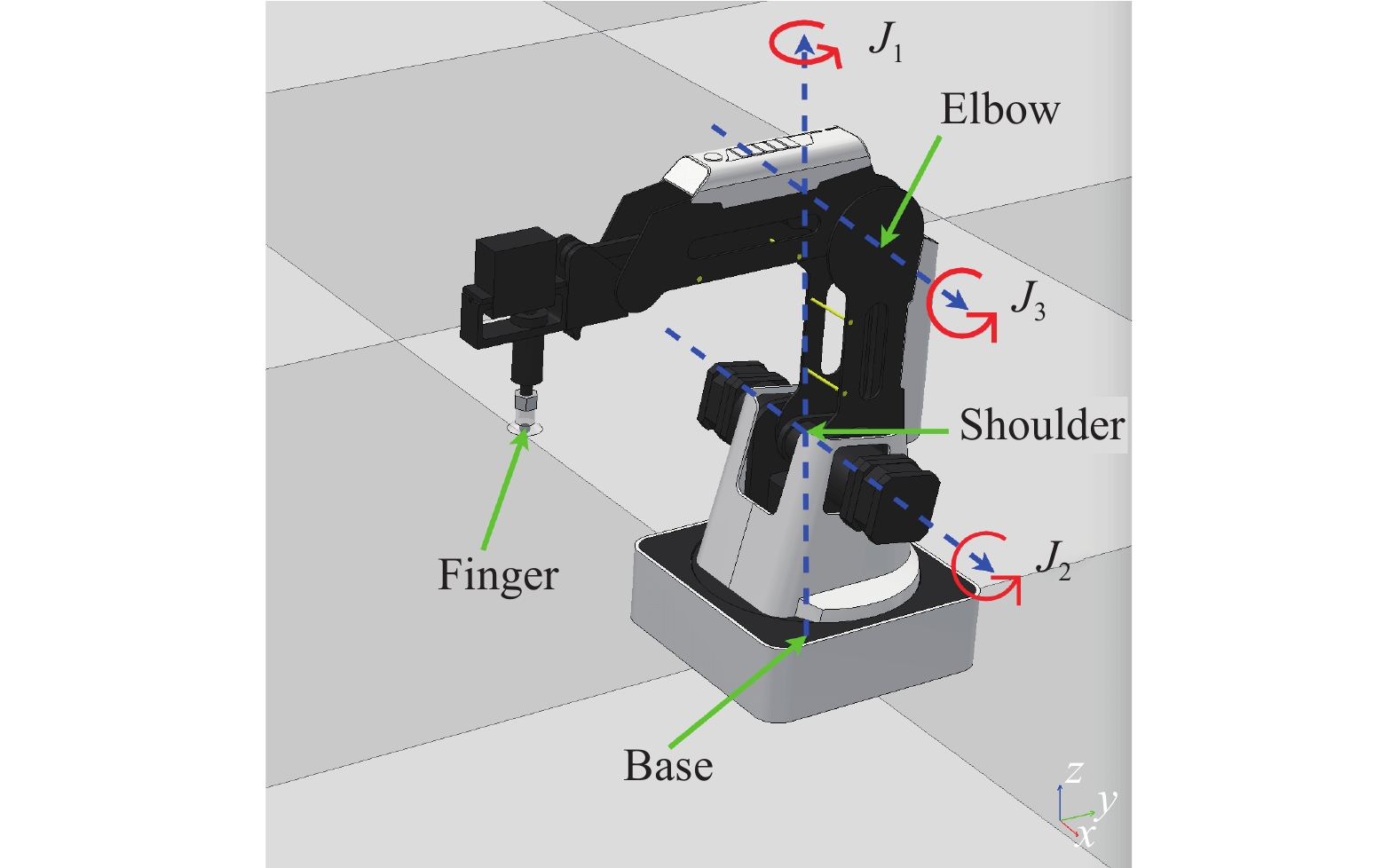
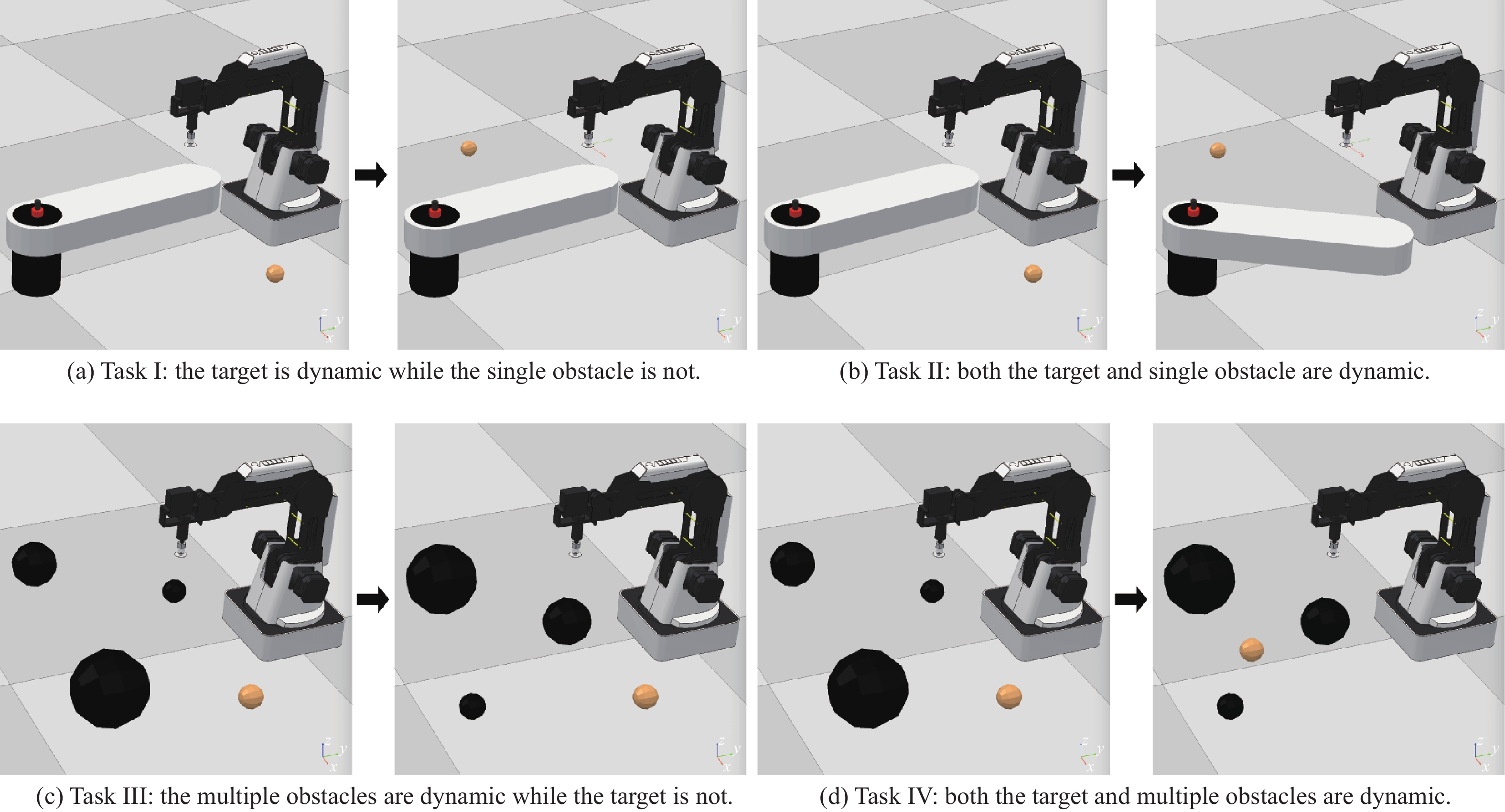
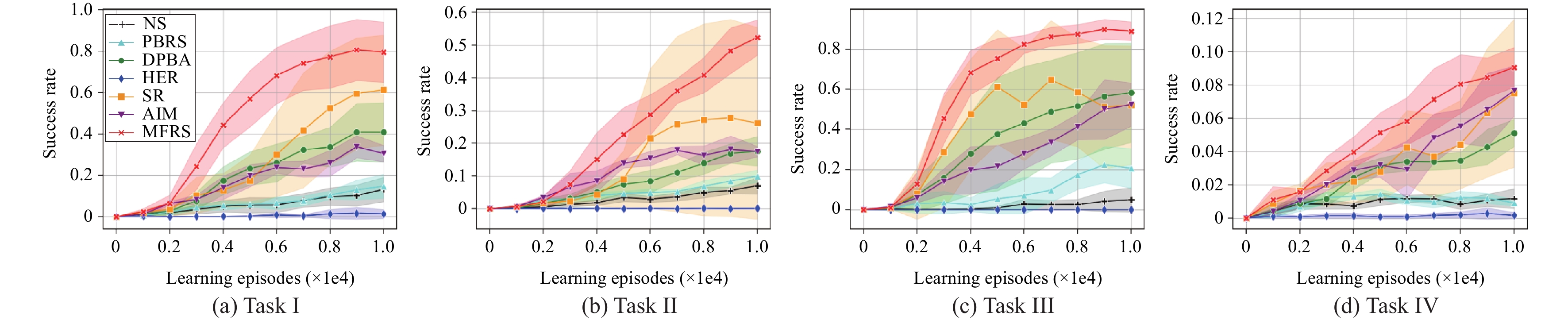
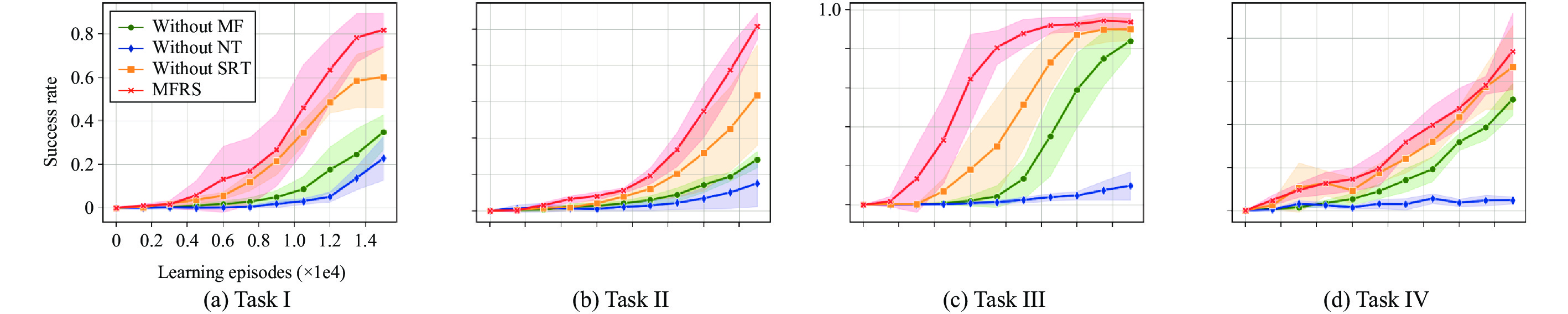
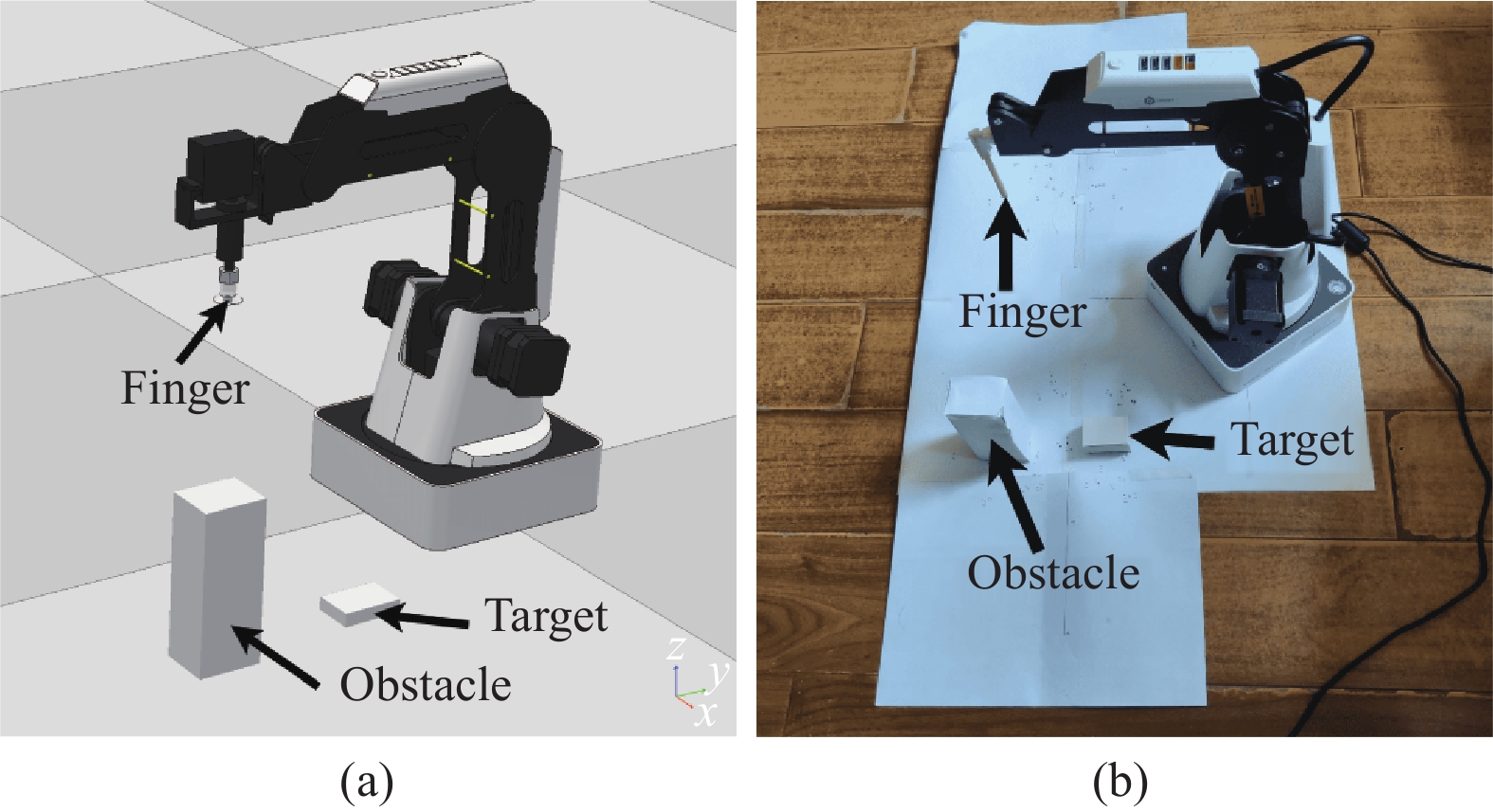
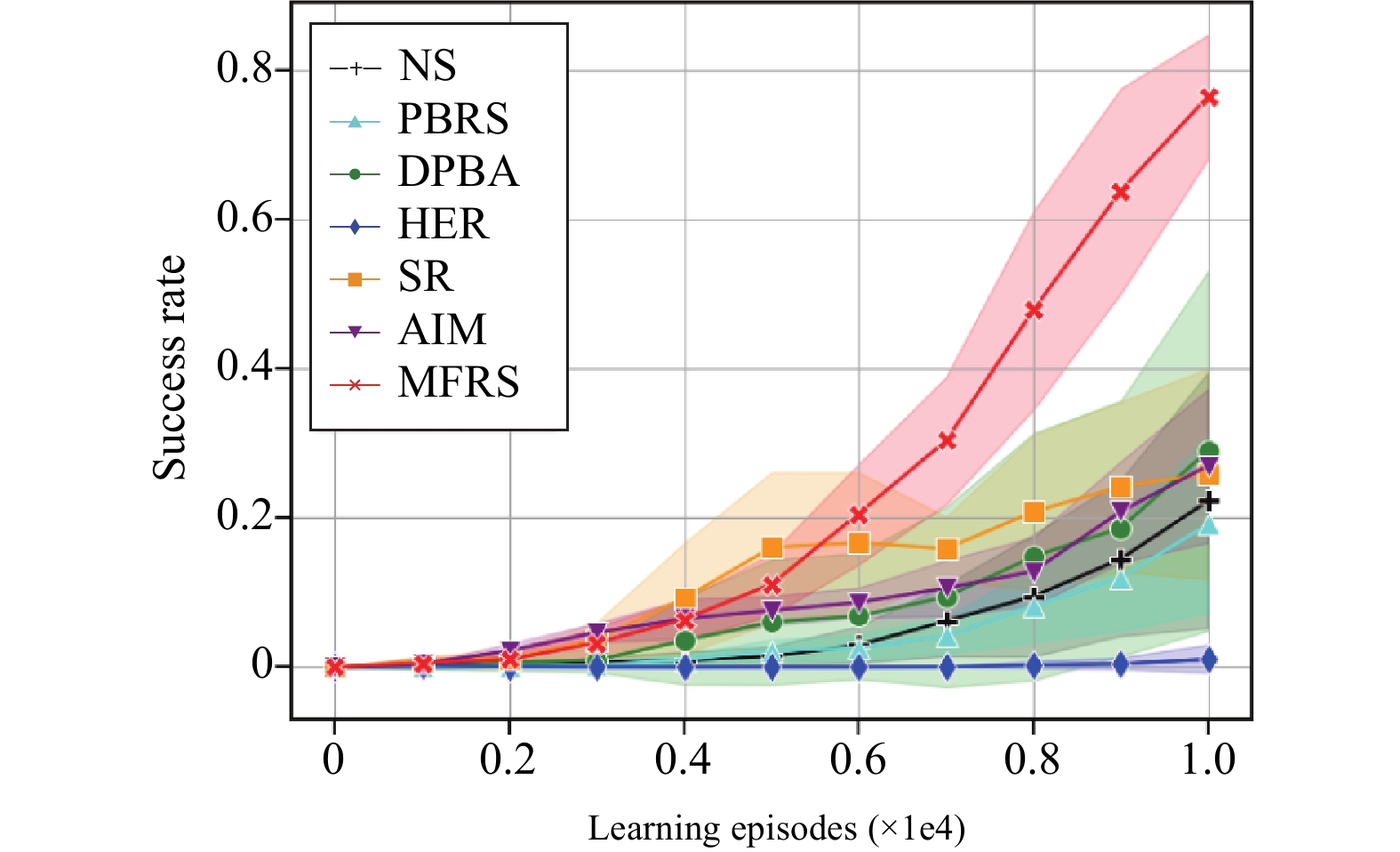
Goal-conditioned reinforcement learning (RL) is an interesting extension of the traditional RL framework, where the dynamic environment and reward sparsity can cause conventional learning algorithms to fail. Reward shaping is a practical approach to improving sample efficiency by embedding human domain knowledge into the learning process. Existing reward shaping methods for goal-conditioned RL are typically built on distance metrics with a linear and isotropic distribution, which may fail to provide sufficient information about the ever-changing environment with high complexity. This paper proposes a novel magnetic field-based reward shaping (MFRS) method for goal-conditioned RL tasks with dynamic target and obstacles. Inspired by the physical properties of magnets, we consider the target and obstacles as permanent magnets and establish the reward function according to the intensity values of the magnetic field generated by these magnets. The nonlinear and anisotropic distribution of the magnetic field intensity can provide more accessible and conducive information about the optimization landscape, thus introducing a more sophisticated magnetic reward compared to the distance-based setting. Further, we transform our magnetic reward to the form of potential-based reward shaping by learning a secondary potential function concurrently to ensure the optimal policy invariance of our method. Experiments results in both simulated and real-world robotic manipulation tasks demonstrate that MFRS outperforms relevant existing methods and effectively improves the sample efficiency of RL algorithms in goal-conditioned tasks with various dynamics of the target and obstacles.

| [1] |
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. 2nd ed. Cambridge, MA, USA: MIT press, 2018.
|
| [2] |
R. Bellman, “Dynamic programming,” Science, vol. 153, no. 3731, pp. 34–37, 1966. doi: 10.1126/science.153.3731.34
|
| [3] |
G. Tesauro and G. Galperin, “On-line policy improvement using monte-carlo search,” in Proc. Adv. Neural Inf. Proces. Syst., 1996.
|
| [4] |
C. J. Watkins and P. Dayan, “Q-learning,” Mach. Learn., vol. 8, no. 3, pp. 279–292, 1992.
|
| [5] |
Z. Wang, C. Chen, H.-X. Li, D. Dong, and T.-J. Tarn, “Incremental reinforcement learning with prioritized sweeping for dynamic environments,” IEEE/ASME Trans. Mechatronics, vol. 24, no. 2, pp. 621–632, 2019. doi: 10.1109/TMECH.2019.2899365
|
| [6] |
C. Chen, D. Dong, H.-X. Li, J. Chu, and T.-J. Tarn, “Fidelity-based probabilistic Q-learning for control of quantum systems,” IEEE Trans. Neural Netw. Learn. Syst., vol. 25, no. 5, pp. 920–933, 2013.
|
| [7] |
B. Luo, D. Liu, T. Huang, and D. Wang, “Model-free optimal tracking control via critic-only Q-learning,” IEEE Trans. Neural Netw. Learn. Syst., vol. 27, no. 10, pp. 2134–2144, 2016. doi: 10.1109/TNNLS.2016.2585520
|
| [8] |
Z. Zhang, D. Zhao, J. Gao, D. Wang, and Y. Dai, “FMRQ—A multiagent reinforcement learning algorithm for fully cooperative tasks,” IEEE Trans. Cybern., vol. 47, no. 6, pp. 1367–1379, 2016.
|
| [9] |
Y. Zhu, D. Zhao, and X. Li, “Iterative adaptive dynamic programming for solving unknown nonlinear zero-sum game based on online data,” IEEE Trans. Neural Netw. Learn. Syst., vol. 28, no. 3, pp. 714–725, 2016.
|
| [10] |
X. Xu, D. Hu, and X. Lu, “Kernel-based least squares policy iteration for reinforcement learning,” IEEE Trans. Neural Netw., vol. 18, no. 4, pp. 973–992, 2007. doi: 10.1109/TNN.2007.899161
|
| [11] |
Y. Zheng, Z. Meng, J. Hao, Z. Zhang, T. Yang, and C. Fan, “A Bayesian policy reuse approach against non-stationary agents,” in Proc. Adv. Neural Inf. Proces. Syst., 2018.
|
| [12] |
Y. Yu, S.-Y. Chen, Q. Da, and Z.-H. Zhou, “Reusable reinforcement learning via shallow trails,” IEEE Trans. Neural Netw. Learn. Syst., vol. 29, no. 6, pp. 2204–2215, 2018. doi: 10.1109/TNNLS.2018.2803729
|
| [13] |
Z. Wang, C. Chen, and D. Dong, “A Dirichlet process mixture of robust task models for scalable lifelong reinforcement learning,” IEEE Trans. Cybern., 2022. DOI: 10.1109/TCYB.2022.3170485
|
| [14] |
V. Mnih, K. Kavukcuoglu, D. Silver, et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015. doi: 10.1038/nature14236
|
| [15] |
O. Vinyals, I. Babuschkin, W. M. Czarnecki, et al., “Grandmaster level in StarCraft II using multi-agent reinforcement learning,” Nature, vol. 575, no. 7782, pp. 350–354, 2019. doi: 10.1038/s41586-019-1724-z
|
| [16] |
J. Pan, X. Wang, Y. Cheng, and Q. Yu, “Multisource transfer double DQN based on actor learning,” IEEE Trans. Neural Netw. Learn. Syst., vol. 29, no. 6, pp. 2227–2238, 2018. doi: 10.1109/TNNLS.2018.2806087
|
| [17] |
D. Silver, J. Schrittwieser, K. Simonyan, et al., “Mastering the game of Go without human knowledge,” Nature, vol. 550, no. 7676, pp. 354–359, 2017. doi: 10.1038/nature24270
|
| [18] |
Y. Duan, X. Chen, R. Houthooft, J. Schulman, and P. Abbeel, “Benchmarking deep reinforcement learning for continuous control,” in Proc. Int. Conf. Mach. Learn., 2016, pp. 1329–1338.
|
| [19] |
Z. Wang, C. Chen, and D. Dong, “Lifelong incremental reinforcement learning with online Bayesian inference,” IEEE Trans. Neural Netw. Learn. Syst., vol. 33, no. 8, pp. 4003–4016, 2022. doi: 10.1109/TNNLS.2021.3055499
|
| [20] |
D. Li, D. Zhao, Q. Zhang, and Y. Chen, “Reinforcement learning and deep learning based lateral control for autonomous driving [application notes],” IEEE Comput. Intell. Mag., vol. 14, no. 2, pp. 83–98, 2019. doi: 10.1109/MCI.2019.2901089
|
| [21] |
L. P. Kaelbling, “Learning to achieve goals,” in Proc. Int. Joint Conf. Artif. Intell., vol. 2, 1993, pp. 1094–8.
|
| [22] |
T. Schaul, D. Horgan, K. Gregor, and D. Silver, “Universal value function approximators,” in Proc. Int. Conf. Mach. Learn., 2015, pp. 1312–1320.
|
| [23] |
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, O. Pieter Abbeel, and W. Zaremba, “Hindsight experience replay,” in Proc. Adv. Neural Inf. Proces. Syst., 2017.
|
| [24] |
O. Marom and B. Rosman, “Belief reward shaping in reinforcement learning,” in Proc. AAAI Conf. Artif. Intell., vol. 32, no. 1, 2018.
|
| [25] |
M. Dann, F. Zambetta, and J. Thangarajah, “Deriving subgoals autonomously to accelerate learning in sparse reward domains,” in Proc. AAAI Conf. Artif. Intell., 2019, pp. 881–889.
|
| [26] |
A. Y. Ng, D. Harada, and S. Russell, “Policy invariance under reward transformations: Theory and application to reward shaping,” in Proc. Int. Conf. Mach. Learn., vol. 99, 1999, pp. 278–287.
|
| [27] |
E. Wiewiora, G. W. Cottrell, and C. Elkan, “Principled methods for advising reinforcement learning agents,” in Proc. Int. Conf. Mach. Learn., 2003, pp. 792–799.
|
| [28] |
S. M. Devlin and D. Kudenko, “Dynamic potential-based reward shaping,” in Proc. Int. Conf. Auton. Agents Multiagent Syst., 2012, pp. 433–440.
|
| [29] |
A. Harutyunyan, S. Devlin, P. Vrancx, and A. Nowé, “Expressing arbitrary reward functions as potential-based advice,” in Proc. AAAI Conf. Artif. Intell., vol. 29, no. 1, 2015.
|
| [30] |
A. Trott, S. Zheng, C. Xiong, and R. Socher, “Keeping your distance: Solving sparse reward tasks using self-balancing shaped rewards,” in Proc. Adv. Neural Inf. Proces. Syst., 2019.
|
| [31] |
D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller, “Deterministic policy gradient algorithms,” in Proc. Int. Conf. Mach. Learn., 2014, pp. 387–395.
|
| [32] |
N. Heess, G. Wayne, D. Silver, T. Lillicrap, T. Erez, and Y. Tassa, “Learning continuous control policies by stochastic value gradients,” in Proc. Adv. Neural Inf. Proces. Syst., 2015.
|
| [33] |
V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in Proc. Int. Conf. Mach. Learn., 2016, pp. 1928–1937.
|
| [34] |
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” in Proc. Int. Conf. Mach. Learn., 2018, pp. 1587–1596.
|
| [35] |
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in Proc. Int. Conf. Mach. Learn., 2018, pp. 1861–1870.
|
| [36] |
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Mach. Learn., vol. 8, no. 3, pp. 229–256, 1992.
|
| [37] |
M. Liu, M. Zhu, and W. Zhang, “Goal-conditioned reinforcement learning: Problems and solutions,” arXiv preprint arXiv: 2201.08299, 2022.
|
| [38] |
Y. Wu, G. Tucker, and O. Nachum, “The laplacian in RL: Learning representations with efficient approximations,” arXiv preprint arXiv: 1810.04586, 2018.
|
| [39] |
D. Ghosh, A. Gupta, and S. Levine, “Learning actionable representations with goal-conditioned policies,” arXiv preprint arXiv: 1811.07819, 2018.
|
| [40] |
D. Warde-Farley, T. Van de Wiele, T. Kulkarni, C. Ionescu, S. Hansen, and V. Mnih, “Unsupervised control through non-parametric discriminative rewards,” arXiv preprint arXiv: 1811.11359, 2018.
|
| [41] |
K. Hartikainen, X. Geng, T. Haarnoja, and S. Levine, “Dynamical distance learning for semi-supervised and unsupervised skill discovery,” arXiv preprint arXiv: 1907.08225, 2019.
|
| [42] |
I. Durugkar, M. Tec, S. Niekum, and P. Stone, “Adversarial intrinsic motivation for reinforcement learning,” in Proc. Adv. Neural Inf. Proces. Syst., 2021.
|
| [43] |
J. Wu, Z. Huang, W. Huang, and C. Lv, “Prioritized experience-based reinforcement learning with human guidance for autonomous driving,” IEEE Trans. Neural Netw. Learn. Syst., 2022. DOI: 10.1109/TNNLS.2022.3177685
|
| [44] |
J. Wu, Z. Huang, Z. Hu, and C. Lv, “Toward human-in-the-loop AI: Enhancing deep reinforcement learning via real-time human guidance for autonomous driving,” Eng., 2022. DOI: 10.1016/j.eng.2022.05.017
|
| [45] |
W. Bai, Q. Zhou, T. Li, and H. Li, “Adaptive reinforcement learning neural network control for uncertain nonlinear system with input saturation,” IEEE Trans. Cybern., vol. 50, no. 8, pp. 3433–3443, 2019.
|
| [46] |
W. Bai, T. Li, Y. Long, and C. P. Chen, “Event-triggered multigradient recursive reinforcement learning tracking control for multiagent systems,” IEEE Trans. Neural Netw. Learn. Syst., vol. 34, no. 1, pp. 366–379, 2021.
|
| [47] |
Y. Ding, C. Florensa, P. Abbeel, and M. Phielipp, “Goal-conditioned imitation learning,” in Proc. Adv. Neural Inf. Proces. Syst., 2019.
|
| [48] |
Y. Zhang, P. Abbeel, and L. Pinto, “Automatic curriculum learning through value disagreement,” in Proc. Adv. Neural Inf. Proces. Syst., 2020, pp. 7648–7659.
|
| [49] |
R. McCarthy and S. J. Redmond, “Imaginary hindsight experience replay: Curious model-based learning for sparse reward tasks,” arXiv preprint arXiv: 2110.02414, 2021.
|
| [50] |
M. Fang, T. Zhou, Y. Du, L. Han, and Z. Zhang, “Curriculum-guided hindsight experience replay,” in Proc. Adv. Neural Inf. Proces. Syst., 2019.
|
| [51] |
S. Pitis, H. Chan, S. Zhao, B. Stadie, and J. Ba, “Maximum entropy gain exploration for long horizon multi-goal reinforcement learning,” in Proc. Int. Conf. Mach. Learn., 2020, pp. 7750–7761.
|
| [52] |
Y. Kuang, A. I. Weinberg, G. Vogiatzis, and D. R. Faria, “Goal density-based hindsight experience prioritization for multi-goal robot manipulation reinforcement learning,” in Proc. IEEE Int. Conf. Robot Human Interactive Commun., 2020, pp. 432–437.
|
| [53] |
R. W. Pryor, Multiphysics Modeling Using COMSOL®: A First Principles Approach. Jones & Bartlett Publishers, 2009.
|
| [54] |
R. E. Deakin, “3-D coordinate transformations,” Surveying Land Inf. Syst., vol. 58, no. 4, pp. 223–234, 1998.
|
| [55] |
H. B. Suay, T. Brys, M. E. Taylor, and S. Chernova, “Learning from demonstration for shaping through inverse reinforcement learning.” in Proc. Int. Conf. Auton. Agents Multiagent Syst., 2016, pp. 429–437.
|
| [56] |
G. A. Rummery and M. Niranjan, On-line Q-learning Using Connectionist Systems. Cambridge, UK: University of Cambridge, Department of Engineering, 1994, vol. 37.
|
| [57] |
E. Rohmer, S. P. Singh, and M. Freese, “V-REP: A versatile and scalable robot simulation framework,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst., 2013, pp. 1321–1326.
|
| [58] |
M. Plappert, M. Andrychowicz, A. Ray, et al., “Multi-goal reinforcement learning: Challenging robotics environments and request for research,” arXiv preprint arXiv: 1802.09464, 2018.
|
| [59] |
G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “OpenAI Gym,” arXiv preprint arXiv: 1606.01540, 2016.
|
| [60] |
M. R. Islam, M. A. Rahaman, M. Assad-uz Zaman, and M. Habibur, “Cartesian trajectory based control of dobot robot,” in Proc. Int. Conf. Ind. Eng. Operations Manage., 2019.
|
| [61] |
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprint arXiv: 1509.02971, 2015.
|
| [62] |
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv: 1412.6980, 2014.
|

Figures(9) / Tables(2)






 DownLoad:
DownLoad: