A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 10
Issue 3
Volume 10
Issue 3
IEEE/CAA Journal of Automatica Sinica
| Citation: | Q. H. Miao, Y. S. Lv, M. Huang, X. Wang, and F.-Y. Wang, “Parallel learning: Overview and perspective for computational learning across Syn2Real and Sim2Real,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 3, pp. 603–631, Mar. 2023. doi: 10.1109/JAS.2023.123375

|

| [1] |
S. I. Nikolenko, Synthetic Data for Deep Learning. Cham, Germany: Springer, 2021.
|
| [2] |
C. Shorten and T. M. Khoshgoftaar, “A survey on image data augmentation for deep learning,” J. Big Data, vol. 6, no. 1, p. 60, Jul. 2019. doi: 10.1186/s40537-019-0197-0
|
| [3] |
A. Tsirikoglou, G. Eilertsen, and J. Unger, “A survey of image synthesis methods for visual machine learning,” Comput. Graphics Forum, vol. 39, no. 6, pp. 426–451, Sept. 2020. doi: 10.1111/cgf.14047
|
| [4] |
W. S. Zhao, J. P. Queralta, and T. Westerlund, “Sim-to-real transfer in deep reinforcement learning for robotics: A survey,” in Proc. IEEE Symp. Series on Computational Intelligence, Canberra, Australia, 2020, pp. 737-744.
|
| [5] |
F. Muratore, F. Ramos, G. Turk, W. H. Yu, M. Gienger, and J. Peters, “Robot learning from randomized simulations: A review,” Front. Robot. AI, vol. 9, p. 799893, Apr. 2021.
|
| [6] |
F.-Y. Wang, “Artificial societies, computational experiments, and parallel systems: A discussion on computational theory of complex social-economic systems,” Complex Syst. Complexity Sci., vol. 1, no. 4, pp. 25–35, Oct. 2004.
|
| [7] |
F.-Y. Wang, “Parallel system methods for management and control of complex systems,” Control Decis., vol. 19, no. 5, pp. 485–489, May 2004.
|
| [8] |
F.-Y. Wang, “Computational theory and method on complex system,” China Basic Sci., vol. 6, no. 5, pp. 3–10, May 2004.
|
| [9] |
F.-Y. Wang, X. Wang, L. X. Li, and L. Li, “Steps toward parallel intelligence,” IEEE/CAA J. Autom. Sinica, vol. 3, no. 4, pp. 345–348, Oct. 2016. doi: 10.1109/JAS.2016.7510067
|
| [10] |
F.-Y. Wang, “Toward a paradigm shift in social computing: The ACP approach,” IEEE Intell. Syst., vol. 22, no. 5, pp. 65–67, Sept.−Oct. 2007. doi: 10.1109/MIS.2007.4338496
|
| [11] |
Y. S. Lv, Y. Y. Chen, L. Li, and F.-Y. Wang, “Generative adversarial networks for parallel transportation systems,” IEEE Intell. Transp. Syst. Mag., vol. 10, no. 3, pp. 4–10, Jun. 2018. doi: 10.1109/MITS.2018.2842249
|
| [12] |
Y. S. Lv, Y. Y. Chen, J. C. Jin, Z. J. Li, P. J. Ye, and F. H. Zhu, “Parallel transportation: Virtual-real interaction for intelligent traffic management and control,” Chin. J. Intell. Sci. Technol., vol. 1, no. 1, pp. 21–33, Mar. 2019.
|
| [13] |
L. Li, X. Wang, K. F. Wang, Y. L. Lin, J. M. Xin, L. Chen, L. H. Xu, B. Tian, Y. F. Ai, J. Wang, D. P. Cao, Y. H. Liu, C. H. Wang, N. N. Zheng, and F.-Y. Wang, “Parallel testing of vehicle intelligence via virtual-real interaction,” Sci. Robot., vol. 4, no. 28, p. eaaw4106, Mar. 2019. doi: 10.1126/scirobotics.aaw4106
|
| [14] |
Y. Y. Chen, Y. S. Lv, and F.-Y. Wang, “Traffic flow imputation using parallel data and generative adversarial networks,” IEEE Trans. Intell. Transp. Syst., vol. 21, no. 4, pp. 1624–1630, Apr. 2020. doi: 10.1109/TITS.2019.2910295
|
| [15] |
L. Li, Y. L. Lin, N. N. Zheng, and F.-Y. Wang, “Parallel learning: A perspective and a framework,” IEEE/CAA J. Autom. Sinica, vol. 4, no. 3, pp. 389–395, Jan. 2017. doi: 10.1109/JAS.2017.7510493
|
| [16] |
M. Grieves, “PLM—Beyond lean manufacturing,” Manuf. Eng., vol. 130, no. 3, p. 23, Mar. 2003.
|
| [17] |
M. Shafto, M. Conroy, R. Doyle, E. Glaessgen, C. Kemp, J. LeMoigne, and L. Wang, “Modeling, simulation, information technology and processing roadmap,” in Proc. Nat. Aeronautics and Space Administration, 2010.
|
| [18] |
F. Piltan and J. M. Kim, “Bearing anomaly recognition using an intelligent digital twin integrated with machine learning,” Appl. Sci., vol. 11, no. 10, p. 4602, May 2021. doi: 10.3390/app11104602
|
| [19] |
Y. Y. Dai, K. Zhang, S. Maharjan, and Y. Zhang, “Deep reinforcement learning for stochastic computation offloading in digital twin networks,” IEEE Trans. Industr. Inform., vol. 17, no. 7, pp. 4968–4977, Jul. 2021. doi: 10.1109/TII.2020.3016320
|
| [20] |
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with CLIP latents,” arXiv preprint arXiv: 2204.06125, 2022.
|
| [21] |
T. DeVries and G. W. Taylor, “Improved regularization of convolutional neural networks with cutout,” arXiv preprint arXiv: 1708.04552, 2017.
|
| [22] |
Z. Zhong, L. Zheng, G. L. Kang, S. Z. Li, and Y. Yang, “Random erasing data augmentation,” Proc. AAAI Conf. Artif. Intell., vol. 34, no. 7, pp. 13001–13008, Apr. 2020.
|
| [23] |
J. L. Han, P. F. Fang, W. H. Li, J. Hong, M. A. Armin, I. Reid, L. Petersson, and H. D. Li, “You only cut once: Boosting data augmentation with a single cut,” in Proc. 39th Int. Conf. Machine Learning, Baltimore, USA, 2022, pp. 8196–8212.
|
| [24] |
E. D. Cubuk, B. Zoph, D. Mané, V. Vasudevan, and Q. V. Le, “AutoAugment: Learning augmentation strategies from data,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 113–123.
|
| [25] |
D. Ho, E. Liang, I. Stoica, P. Abbeel, and X. Chen, “Population based augmentation: Efficient learning of augmentation policy schedules,” in Proc. 36th Int. Conf. Machine Learning, Long Beach, USA, 2019, pp. 2731–2741.
|
| [26] |
Y. G. Li, G. S. Hu, Y. T. Wang, T. Hospedales, N. M. Robertson, and Y. X. Yang, “Differentiable automatic data augmentation,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 580–595.
|
| [27] |
A. Fawzi, H. Samulowitz, D. Turaga, and P. Frossard, “Adaptive data augmentation for image classification,” in Proc. IEEE Int. Conf. Image Processing, Phoenix, USA, 2016, pp. 3688–3692.
|
| [28] |
S. Tripathi, S. Chandra, A. Agrawal, A. Tyagi, J. M. Rehg, and V. Chari, “Learning to generate synthetic data via compositing,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 461–470.
|
| [29] |
T. Tran, T. Pham, G. Carneiro, L. Palmer, and I. Reid, “A Bayesian data augmentation approach for learning deep models,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 2794–2803.
|
| [30] |
Y. G. Yan, M. K. Tan, Y. W. Xu, J. Z. Cao, M. Ng, H. Q. Min, and Q. Y. Wu, “Oversampling for imbalanced data via optimal transport,” Proc. AAAI Conf. Artif. Intell., vol. 33, no. 1, pp. 5605–5612, Jul. 2019.
|
| [31] |
Y. He, F. D. Lin, X. Yuan, and N. F. Tzeng, “Interpretable minority synthesis for imbalanced classification,” in Proc. 30th Int. Joint Conf. Artificial Intelligence, Montreal, Canada, 2021, pp. 2542–2548.
|
| [32] |
E. Cheung, T. K. Wong, A. Bera, X. G. Wang, and D. Manocha, “LCrowdV: Generating labeled videos for simulation-based crowd behavior learning,” in Proc. European Conf. Computer Vision, Amsterdam, the Netherlands, 2016, pp. 709–727.
|
| [33] |
W. W. Zhang, K. F. Wang, Y. T. Liu, Y. Lu, and F.-Y. Wang, “A parallel vision approach to scene-specific pedestrian detection,” Neurocomputing, vol. 394, pp. 114–126, Jun. 2020. doi: 10.1016/j.neucom.2019.03.095
|
| [34] |
H. Hattori, N. Lee, V. N. Boddeti, F. Beainy, K. M. Kitani, and T. Kanade, “Synthesizing a scene-specific pedestrian detector and pose estimator for static video surveillance,” Int. J. Comput. Vis., vol. 126, no. 9, pp. 1027–1044, Sept. 2018. doi: 10.1007/s11263-018-1077-3
|
| [35] |
D. Dwibedi, I. Misra, and M. Hebert, “Cut, paste and learn: Surprisingly easy synthesis for instance detection,” in Proc. IEEE Int. Conf. Computer Vision, Venice, Italy, 2017, pp. 1310–1319.
|
| [36] |
N. Dvornik, J. Mairal, and C. Schmid, “Modeling visual context is key to augmenting object detection datasets,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 375–391.
|
| [37] |
S. Wu, S. H. Lin, W. H. Wu, M. Azzam, and H. S. Wong, “Semi-supervised pedestrian instance synthesis and detection with mutual reinforcement,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 5056–5065.
|
| [38] |
L. L. Liu, M. Muelly, J. Deng, T. Pfister, and L. J. Li, “Generative modeling for small-data object detection,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea, 2019, pp. 6072–6080.
|
| [39] |
E. Martinson, B. Furlong, and A. Gillies, “Training rare object detection in satellite imagery with synthetic GAN images,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition Workshops, Nashville, USA, 2021, pp. 2763–2770.
|
| [40] |
P. L. Huang, J. W. Han, D. Cheng, and D. W. Zhang, “Robust region feature synthesizer for zero-shot object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 7612–7621.
|
| [41] |
X. C. Peng, B. C. Sun, K. Ali, and K. Saenko, “Learning deep object detectors from 3D models,” in Proc. IEEE Int. Conf. Computer Vision, Santiago, Chile, 2015, pp. 1278–1286.
|
| [42] |
H. Hattori, V. N. Boddeti, K. Kitani, and T. Kanade, “Learning scene-specific pedestrian detectors without real data,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Boston, USA, 2015, pp. 3819–3827.
|
| [43] |
K. Wang, B. Babenko, and S. Belongie, “End-to-end scene text recognition,” in Proc. Int. Conf. Computer Vision, Barcelona, Spain, 2011, pp. 1457–1464.
|
| [44] |
A. Gupta, A. Vedaldi, and A. Zisserman, “Synthetic data for text localisation in natural images,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 2315–2324.
|
| [45] |
F. N. Zhan, S. J. Lu, and C. H. Xue, “Verisimilar image synthesis for accurate detection and recognition of texts in scenes,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 257–273.
|
| [46] |
S. B. Long and C. Yao, “UnrealText: Synthesizing realistic scene text images from the unreal world,” arXiv preprint arXiv: 2003.10608, 2020.
|
| [47] |
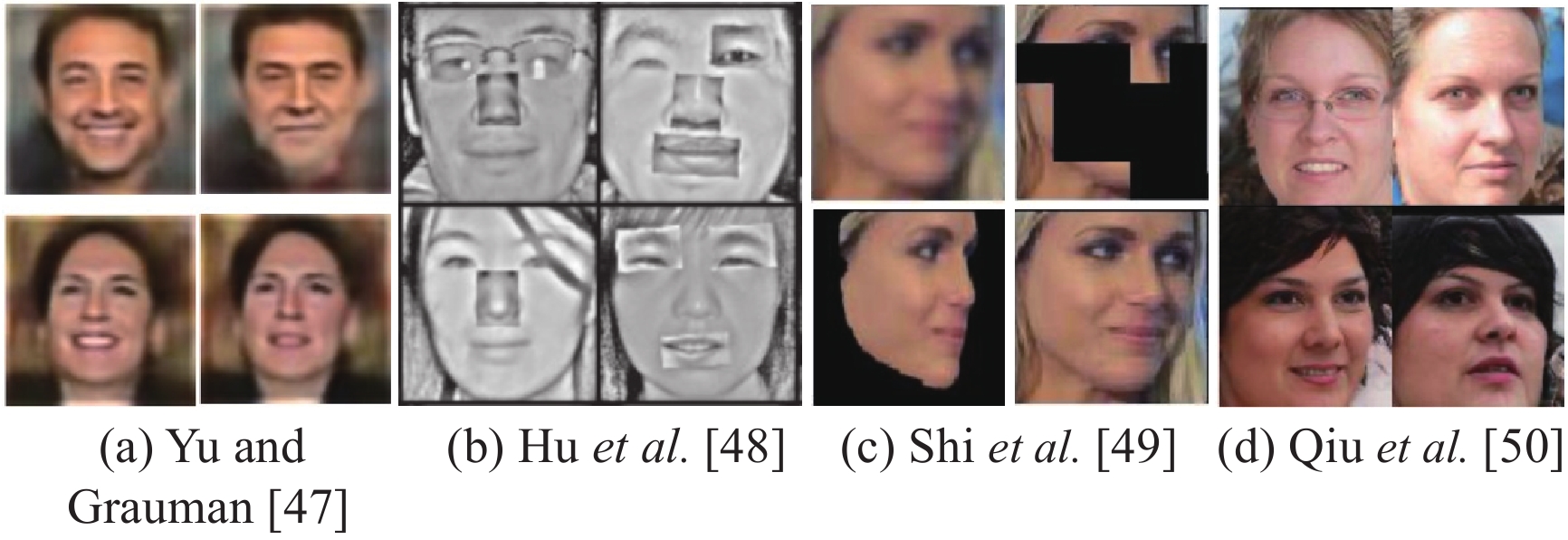
A. Yu and K. Grauman, “Semantic jitter: Dense supervision for visual comparisons via synthetic images,” in Proc. IEEE Int. Conf. Computer Vision, Venice, Italy, 2017, pp. 5571–5580.
|
| [48] |
G. S. Hu, X. J. Peng, Y. X. Yang, T. M. Hospedales, and J. Verbeek, “Frankenstein: Learning deep face representations using small data,” IEEE Trans. Image Process., vol. 27, no. 1, pp. 293–303, Jan. 2018. doi: 10.1109/TIP.2017.2756450
|
| [49] |
Y. C. Shi, X. Yu, K. Sohn, M. Chandraker, and A. K. Jain, “Towards universal representation learning for deep face recognition,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition , Seattle, USA, 2020, pp. 6816–6825.
|
| [50] |
H. B. Qiu, B. S. Yu, D. H. Gong, Z. F. Li, W. Liu, and D. C. Tao, “SynFace: Face recognition with synthetic data,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 10860–10870.
|
| [51] |
Z. H. Zhai, P. J. Yang, X. F. Zhang, M. J. Huang, H. J. Cheng, X. J. Yan, C. M. Wang, and S. L. Pu, “Demodalizing face recognition with synthetic samples,” Proc. AAAI Conf. Artif. Intell., vol. 35, no. 4, pp. 3278–3286, May 2021.
|
| [52] |
G. Rogez and C. Schmid, “MoCap-guided data augmentation for 3D pose estimation in the wild,” in Proc. 30th Int. Conf. Neural Information Processing Systems, Barcelona, Spain, 2016, pp. 3116–3124.
|
| [53] |
W. Z. Chen, H. Wang, Y. Y. Li, H. Su, Z. H. Wang, C. H. Tu, D. Lischinski, D. Cohen-Or, and B. Q. Chen, “Synthesizing training images for boosting human 3D pose estimation,” in Proc. 4th Int. Conf. 3D Vision, Stanford, USA, 2016, pp. 479–488.
|
| [54] |
D. Mehta, O. Sotnychenko, F. Mueller, W. P. Xu, S. Sridhar, G. Pons-Moll, and C. Theobalt, “Single-shot multi-person 3D pose estimation from monocular RGB,” in Proc. Int. Conf. 3D Vision, Verona, Italy, 2018, pp. 120–130.
|
| [55] |
D. T. Hoffmann, D. Tzionas, M. J. Black, and S. Y. Tang, “Learning to train with synthetic humans,” in Proc. 41st German Conf. Pattern Recognition, Dortmund, Germany, 2019, pp. 609–623.
|
| [56] |
S. C. Li, L. Ke, K. Pratama, Y. W. Tai, C. K. Tang, and K. T. Cheng, “Cascaded deep monocular 3D human pose estimation with evolutionary training data,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 6172–6182.
|
| [57] |
K. H. Gong, J. F. Zhang, and J. S. Feng, “PoseAug: A differentiable pose augmentation framework for 3D human pose estimation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 8571–8580.
|
| [58] |
J. A. Chen, D. Tam, C. Raffel, M. Bansal, and D. Y. Yang, “An empirical survey of data augmentation for limited data learning in NLP,” arXiv preprint arXiv: 2106.07499, 2021.
|
| [59] |
S. Y. Feng, V. Gangal, J. Wei, S. Chandar, S. Vosoughi, T. Mitamura, and E. Hovy, “A survey of data augmentation approaches for NLP,” in Proc. Findings of the Association for Computational Linguistics, 2021, pp. 968–988.
|
| [60] |
B. H. Li, Y. T. Hou, and W. X. Che, “Data augmentation approaches in natural language processing: A survey,” AI Open, vol. 3, pp. 71–90, Nov. 2022. doi: 10.1016/j.aiopen.2022.03.001
|
| [61] |
A. Tjandra, S. Sakti, and S. Nakamura, “Listening while speaking: Speech chain by deep learning,” in Proc. IEEE Automatic Speech Recognition and Understanding Workshop, Okinawa, Japan, 2017, pp. 301–308.
|
| [62] |
P. B. Denes and E. N. Pinson, The Speech Chain: The Physics and Biology of Spoken Language. Waveland Press, Inc., 2nd edition, Jul. 2015.
|
| [63] |
A. Tjandra, S. Sakti, and S. Nakamura, “End-to-end feedback loss in speech chain framework via straight-through estimator,” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, Brighton, UK, 2019, pp. 6281–6285.
|
| [64] |
A. Tjandra, S. Sakti, and S. Nakamura, “Transformer VQ-VAE for unsupervised unit discovery and speech synthesis: ZeroSpeech 2020 Challenge,” in Proc. Interspeech, 2020, pp. 4851–4855.
|
| [65] |
T. Hayashi, S. Watanabe, Y. Zhang, T. Toda, T. Hori, R. Astudillo, and K. Takeda, “Back-translation-style data augmentation for end-to-end ASR,” in Proc. IEEE Spoken Language Technology Workshop, Athens, Greece, 2018, pp. 426–433.
|
| [66] |
N. Rossenbach, A. Zeyer, R. Schlüter, and H. Ney, “Generating synthetic audio data for attention-based speech recognition systems,” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, Barcelona, Spain, 2020, pp. 7069–7073.
|
| [67] |
X. R. Zheng, Y. L. Liu, D. Gunceler, and D. Willett, “Using synthetic audio to improve the recognition of out-of-vocabulary words in end-to-end asr systems,” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, Toronto, Canada, 2021, pp. 5674–5678.
|
| [68] |
T. Y. Hu, M. Armandpour, A. Shrivastava, J. H. R. Chang, H. Koppula, and O. Tuzel, “SYNT++: Utilizing imperfect synthetic data to improve speech recognition,” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, Singapore, Singapore, 2022, pp. 7682–7686.
|
| [69] |
T. Hori, R. Astudillo, T. Hayashi, Y. Zhang, S. Watanabe, and J. Le Roux, “Cycle-consistency training for end-to-end speech recognition,” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, Brighton, UK, 2019, pp. 6271–6275.
|
| [70] |
G. Wang, A. Rosenberg, Z. H. Chen, Y. Zhang, B. Ramabhadran, Y. H. Wu, and P. Moreno, “Improving speech recognition using consistent predictions on synthesized speech,” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, Barcelona, Spain, 2020, pp. 7029–7033.
|
| [71] |
Z. H. Chen, A. Rosenberg, Y. Zhang, G. Wang, B. Ramabhadran, and P. J. Moreno, “Improving speech recognition using GAN-based speech synthesis and contrastive unspoken text selection,” in Proc. Interspeech, 2020, pp. 556–560.
|
| [72] |
C. P. Du and K. Yu, “Speaker augmentation for low resource speech recognition,” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, Barcelona, Spain, 2020, pp. 7719–7723.
|
| [73] |
A. Fazel, W. Yang, Y. L. Liu, R. Barra-Chicote, Y. X. Meng, R. Maas, and J. Droppo, “SynthASR: Unlocking synthetic data for speech recognition,” in Proc. Interspeech, 2021, pp. 896–900.
|
| [74] |
Y. Cheng, L. Jiang, and W. Macherey, “Robust neural machine translation with doubly adversarial inputs,” in Proc. 57th Annu. Meeting of the Association for Computational Linguistics, Florence, Italy, 2019, pp. 4324–4333.
|
| [75] |
Y. Cheng, L. Jiang, W. Macherey, and J. Eisenstein, “AdvAug: Robust adversarial augmentation for neural machine translation,” in Proc. 58th Annu. Meeting of the Association for Computational Linguistics, 2020, pp. 5961–5970.
|
| [76] |
D. He, Y. C. Xia, T. Qin, L. W. Wang, N. H. Yu, T. Y. Liu, and W. Y. Ma, “Dual learning for machine translation,” in Proc. 30th Int. Conf. Neural Information Processing Systems, Barcelona, Spain, 2016, pp. 820–828.
|
| [77] |
Y. C. Xia, T. Qin, W. Chen, J. Bian, N. H. Yu, and T. Y. Liu, “Dual supervised learning,” in Proc. 34th Int. Conf. Machine Learning, Sydney, Australia, 2017, pp. 3789–3798.
|
| [78] |
Y. J. Wang, Y. C. Xia, L. Zhao, J. Bian, T. Qin, G. Q. Liu, and T. Y. Liu, “Dual transfer learning for neural machine translation with marginal distribution regularization,” in Proc. AAAI Conf. Artif. Intell., vol. 32, no. 1, Apr. 2018.
|
| [79] |
Z. R. Zhang, S. J. Liu, M. Li, M. Zhou, and E. H. Chen, “Joint training for neural machine translation models with monolingual data,” in Proc. AAAI Conf. Artif. Intell., vol. 32, no. 1, 2018.
|
| [80] |
G. Lample, A. Conneau, L. Denoyer, and M. Ranzato, “Unsupervised machine translation using monolingual corpora only,” in Proc. 6th Int. Conf. Learning Representations, Vancouver, Canada, 2018, pp. 14.
|
| [81] |
X. Niu, M. Denkowski, and M. Carpuat, “Bi-directional neural machine translation with synthetic parallel data,” in Proc. 2nd Workshop Neural Machine Translation and Generation, Melbourne, Australia, 2018, pp. 84–91.
|
| [82] |
Y. R. Wang, Y. C. Xia, T. Y. He, F. Tian, T. Qin, C. X. Zhai, and T. Y. Liu, “Multi-agent dual learning,” in Proc. 7th Int. Conf. Learning Representations, New Orleans, USA, 2019.
|
| [83] |
B. Ahmadnia and B. J. Dorr, “Augmenting neural machine translation through round-trip training approach,” Open Comput. Sci., vol. 9, no. 1, pp. 268–278, Oct. 2019. doi: 10.1515/comp-2019-0019
|
| [84] |
Z. X. Zheng, H. Zhou, S. J. Huang, L. Li, X. Y. Dai, and J. J. Chen, “Mirror-generative neural machine translation,” in Proc. 8th Int. Conf. Learning Representations, Addis Ababa, Ethiopia, 2020, p. 16.
|
| [85] |
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Vancouver, Canada, 2017, pp. 23–30.
|
| [86] |
L. Pinto, M. Andrychowicz, P. Welinder, W. Zaremba, and P. Abbeel, “Asymmetric actor critic for image-based robot learning,” in Proc. Robotics: Science and Systems XIV, Pittsburgh, USA, 2018.
|
| [87] |
F. Golemo, A. A. Taïga, A. C. Courville, and P. Y. Oudeyer, “Sim-to-real transfer with neural-augmented robot simulation,” in Proc. 2nd Annu. Conf. Robot Learning, Zürich, Switzerland, 2018, pp. 817–828.
|
| [88] |
F. Sadeghi, A. Toshev, E. Jang, and S. Levine, “Sim2Real viewpoint invariant visual servoing by recurrent control,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 4691–4699.
|
| [89] |
M. Y. Yan, I. Frosio, S. Tyree, and J. Kautz, “Sim-to-real transfer of accurate grasping with eye-in-hand observations and continuous control,” arXiv preprint arXiv: 1712.03303, 2017.
|
| [90] |
K. Bousmalis, A. Irpan, P. Wohlhart, Y. F. Bai, M. Kelcey, M. Kalakrishnan, L. Downs, J. Ibarz, P. Pastor, K. Konolige, S. Levine, and V. Vanhoucke, “Using simulation and domain adaptation to improve efficiency of deep robotic grasping,” in Proc. IEEE Int. Conf. Robotics and Autom., Brisbane, Australia, 2018, pp. 4243–4250.
|
| [91] |
S. James, P. Wohlhart, M. Kalakrishnan, D. Kalashnikov, A. Irpan, J. Ibarz, S. Levine, R. Hadsell, and K. Bousmalis, “Sim-to-real via sim-to-sim: Data-efficient robotic grasping via randomized-to-canonical adaptation networks,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 12619-12629.
|
| [92] |
C. M. Kim, M. Danielczuk, I. Huang, and K. Goldberg, “IPC-GraspSim: Reducing the Sim2Real gap for parallel-jaw grasping with the incremental potential contact model,” in Proc. Int. Conf. Robotics and Autom., Philadelphia, USA, 2022, pp. 6180–6187.
|
| [93] |
Y. Chebotar, A. Handa, V. Makoviychuk, M. Macklin, J. Issac, N. Ratliff, and D. Fox, “Closing the sim-to-real loop: Adapting simulation randomization with real world experience,” in Proc. Int. Conf. Robotics and Autom., Montreal, Canada, 2019, pp. 8973–8979.
|
| [94] |
Y. Q. Du, O. Watkins, T. Darrell, P. Abbeel, and D. Pathak, “Auto-tuned sim-to-real transfer,” in Proc. IEEE Int. Conf. Robotics and Autom., Xi’an, China, 2021, pp. 1290–1296.
|
| [95] |
J. Matas, S. James, and A. J. Davison, “Sim-to-real reinforcement learning for deformable object manipulation,” in Proc. 2nd Annu. Conf. Robot Learning, Zürich, Switzerland, 2018, pp. 734–743.
|
| [96] |
R. Jeong, Y. Aytar, D. Khosid, Y. X. Zhou, J. Kay, T. Lampe, K. Bousmalis, and F. Nori, “Self-supervised sim-to-real adaptation for visual robotic manipulation,” in Proc. IEEE Int. Conf. Robotics and Autom., Paris, France, 2019, pp. 2718–2724.
|
| [97] |
P. Chang and T. Padif, “Sim2Real2Sim: Bridging the gap between simulation and real-world in flexible object manipulation,” in Proc. 4th IEEE Int. Conf. Robotic Computing, Taichung, China, 2020, pp. 56–62.
|
| [98] |
A. Allevato, E. S. Short, M. Pryor, and A. Thomaz, “TuneNet: One-shot residual tuning for system identification and sim-to-real robot task transfer,” in Proc. 3rd Annu. Conf. Robot Learning, Osaka, Japan, 2019, pp. 445–455.
|
| [99] |
O. M. Andrychowicz, B. Baker, M. Chociej, R. Józefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. L. Weng, and W. Zaremba, “Learning dexterous in-hand manipulation,” Int. J. Robot. Res., vol. 39, no. 1, pp. 3–20, Jan. 2020. doi: 10.1177/0278364919887447
|
| [100] |
T. Power and D. Berenson, “Keep it simple: Data-efficient learning for controlling complex systems with simple models,” IEEE Robot. Autom. Lett., vol. 6, no. 2, pp. 1184–1191, Apr. 2021. doi: 10.1109/LRA.2021.3056368
|
| [101] |
S. Scherzinger, A. Roennau, and R. Dillmann, “Contact skill imitation learning for robot-independent assembly programming,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Macau, China, 2019, pp. 4309–4316.
|
| [102] |
OpenAI, I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, J. Schneider, N. Tezak, J. Tworek, P. Welinder, L. L. Weng, Q. M. Yuan, W. Zaremba, and L. Zhang, “Solving Rubik’s cube with a robot hand,” arXiv preprint arXiv: 1910.07113, 2019.
|
| [103] |
A. D. Allevato, E. S. Short, M. Pryor, and A. L. Thomaz, “Iterative residual tuning for system identification and sim-to-real robot learning,” Auton. Robot., vol. 44, no. 7, pp. 1167–1182, Sept. 2020. doi: 10.1007/s10514-020-09925-w
|
| [104] |
E. Heiden, C. E. Denniston, D. Millard, F. Ramos, and G. S. Sukhatme, “Probabilistic inference of simulation parameters via parallel differentiable simulation,” in Proc. Int. Conf. Robotics and Autom., Philadelphia, USA, pp. 3638–3645, 2022.
|
| [105] |
M. Breyer, F. Furrer, T. Novkovic, R. Siegwart, and J. Nieto, “Flexible robotic grasping with sim-to-real transfer based reinforcement learning,” arXiv preprint arXiv: 1803.04996, 2018.
|
| [106] |
S. DI Castro Shashua, S. Mannor, and D. Di Castro, “Sim and real: Better together,” in Proc. 35th Conf. Neural Information Processing Systems, 2021, pp. 6868–6880.
|
| [107] |
A. Farchy, S. Barrett, P. MacAlpine, and P. Stone, “Humanoid robots learning to walk faster: From the real world to simulation and back,” in Proc. Int. Conf. Autonomous Agents and Multi-Agent Systems, Saint Paul, USA, 2013, pp. 39–46.
|
| [108] |
J. P. Hanna and P. Stone, “Grounded action transformation for robot learning in simulation,” in Proc. 31st AAAI Conf. Artificial Intelligence, San Francisco, USA, 2017, pp. 4931–4932.
|
| [109] |
J. Tan, T. N. Zhang, E. Coumans, A. Iscen, Y. F. Bai, D. Hafner, S. Bohez, and V. Vanhoucke, “Sim-to-real: Learning agile locomotion for quadruped robots,” arXiv preprint arXiv: 1804.10332, 2018.
|
| [110] |
W. H. Yu, J. Tan, Y. F. Bai, E. Coumans, and S. Ha, “Learning fast adaptation with meta strategy optimization,” IEEE Robot. Autom. Lett., vol. 5, no. 2, pp. 2950–2957, Apr. 2020. doi: 10.1109/LRA.2020.2974685
|
| [111] |
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V. Tsounis, V. Koltun, and M. Hutter, “Learning agile and dynamic motor skills for legged robots,” Sci. Robot., vol. 4, no. 26, p. eaau5872, Jan. 2019. doi: 10.1126/scirobotics.aau5872
|
| [112] |
J. Lee, J. Hwangbo, L. Wellhausen, V. Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,” Sci. Robot., vol. 5, no. 47, p. eabc5986, Oct. 2020. doi: 10.1126/scirobotics.abc5986
|
| [113] |
Z. W. Hong, Y. M. Chen, S. Y. Su, T. Y. Shann, Y. H. Chang, H. K. Yang, B. H. L. Ho, C. C. Tu, Y. C. Chang, T. C. Hsiao, H. W. Hsiao, S. P. Lai, and C. Y. Lee, “Virtual-to-real: Learning to control in visual semantic segmentation,” arXiv preprint arXiv: 1802.00285, 2018.
|
| [114] |
J. W. Zhang, L. Tai, P. Yun, Y. F. Xiong, M. Liu, J. Boedecker, and W. Burgard, “VR-goggles for robots: Real-to-sim domain adaptation for visual control,” IEEE Robot. Autom. Lett., vol. 4, no. 2, pp. 1148–1155, Apr. 2019. doi: 10.1109/LRA.2019.2894216
|
| [115] |
A. Mitriakov, P. Papadakis, J. Kerdreux, and S. Garlatti, “Reinforcement learning based, staircase negotiation learning: Simulation and transfer to reality for articulated tracked robots,” IEEE Robot. Autom. Mag., vol. 28, no. 4, pp. 10–20, Dec. 2021. doi: 10.1109/MRA.2021.3114105
|
| [116] |
A. Kadian, J. Truong, A. Gokaslan, A. Clegg, E. Wijmans, S. Lee, M. Savva, S. Chernova, and D. Batra, “Sim2Real predictivity: Does evaluation in simulation predict real-world performance?” IEEE Robot. Autom. Lett., vol. 5, no. 4, pp. 6670–6677, Oct. 2020. doi: 10.1109/LRA.2020.3013848
|
| [117] |
J. Truong, S. Chernova, and D. Batra, “Bi-directional domain adaptation for Sim2Real transfer of embodied navigation agents,” IEEE Robot. Autom. Lett., vol. 6, no. 2, pp. 2634–2641, Apr. 2021. doi: 10.1109/LRA.2021.3062303
|
| [118] |
Z. W. Hong, Y. M. Chen, H. K. Yang, S. Y. S, T. Y. Shann, Y. H. Chang, B. H. L. Ho, C. C. Tu, T. C. Hsiao, H. W. Hsiao, S. P. Lai, Y. C. Chang, and C. Y. Lee, “Virtual-to-real: Learning to control in visual semantic segmentation,” in Proc. 27th Int. Joint Conf. Artificial Intelligence, Stockholm, Sweden, 2018, pp. 4912–4920.
|
| [119] |
F. Sadeghi and S. Levine, “CAD2RL: Real single-image flight without a single real image,” in Proc. Robotics: Science and Systems XⅢ, Cambridge, USA, 2017.
|
| [120] |
T. Du, J. Hughes, S. Wah, W. Matusik, and D. Rus, “Underwater soft robot modeling and control with differentiable simulation,” IEEE Robot. Autom. Lett., vol. 6, no. 2, pp. 4994–5001, Jul. 2021.
|
| [121] |
J. Collins, R. Brown, J. Leitner, and D. Howard, “Follow the gradient: Crossing the reality gap using differentiable physics (RealityGrad),” arXiv preprint arXiv: 2109.04674, 2021.
|
| [122] |
D. Vázquez, A. M. López, J. Marín, D. Ponsa, and D. Gerónimo, “Virtual and real world adaptation for pedestrian detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 4, pp. 797–809, Apr. 2014. doi: 10.1109/TPAMI.2013.163
|
| [123] |
S. R. Richter, V. Vineet, S. Roth, and V. Koltun, “Playing for data: Ground truth from computer games,” in Proc. 14th European Conf. Computer Vision, Amsterdam, the Netherlands, 2016, pp. 102–118.
|
| [124] |
D. F. Liu, Y. Q. Wang, K. E. Ho, Z. W. Chu, and E. Matson, “Virtual world bridges the real challenge: Automated data generation for autonomous driving,” in Proc. IEEE Intelligent Vehicles Symp., Paris, France, 2019, pp. 159–164.
|
| [125] |
G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez, “The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 3234–3243.
|
| [126] |
F. S. Saleh, M. S. Aliakbarian, M. Salzmann, L. Petersson, and J. M. Alvarez, “Effective use of synthetic data for urban scene semantic segmentation,” in Proc. 15th European Conf. Computer Vision, 2018, pp. 86–103.
|
| [127] |
Y. L. Tian, X. Li, K. F. Wang, and F. Y. Wang, “Training and testing object detectors with virtual images,” IEEE/CAA J. Autom. Sinica, vol. 5, no. 2, pp. 539–546, Mar. 2018. doi: 10.1109/JAS.2017.7510841
|
| [128] |
X. Li, K. F. Wang, Y. L. Tian, L. Yan, F. Deng, and F. Y. Wang, “The ParallelEye dataset: A large collection of virtual images for traffic vision research,” IEEE Trans. Intell. Transp. Syst., vol. 20, no. 6, pp. 2072–2084, Jun. 2019. doi: 10.1109/TITS.2018.2857566
|
| [129] |
H. Abu Alhaija, S. K. Mustikovela, L. Mescheder, A. Geiger, and C. Rother, “Augmented reality meets computer vision: Efficient data generation for urban driving scenes,” Int. J. Comput. Vis., vol. 126, no. 9, pp. 961–972, Sept. 2018. doi: 10.1007/s11263-018-1070-x
|
| [130] |
L. Z. Zhang, T. Wen, J. Min, J. C. Wang, D. Han, and J. B. Shi, “Learning object placement by inpainting for compositional data augmentation,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 566–581.
|
| [131] |
Y. Chen, F. Rong, S. Duggal, S. L. Wang, X. C. Yan, S. Manivasagam, S. J. Xue, E. Yumer, and R. Urtasun, “GeoSim: Realistic video simulation via geometry-aware composition for self-driving,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 7230–7240.
|
| [132] |
X. L. Zhang, N. Tseng, A. Syed, R. Bhasin, and N. Jaipuria, “SIMBAR: Single image-based scene relighting for effective data augmentation for automated driving vision tasks,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 3718–3728.
|
| [133] |
A. Kar, A. Prakash, M. Y. Liu, E. Cameracci, J. Yuan, M. Rusiniak, D. Acuna, A. Torralba, and S. Fidler, “Meta-sim: Learning to generate synthetic datasets,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 4550–4559.
|
| [134] |
J. Devaranjan, A. Kar, and S. Fidler, “Meta-sim2: Unsupervised learning of scene structure for synthetic data generation,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 715–733.
|
| [135] |
A. Kishore, T. E. Choe, J. Kwon, M. Park, P. F. Hao, and A. Mittel, “Synthetic data generation using imitation training,” in Proc. IEEE/CVF Int. Conf. Computer Vision Workshops, Montreal, Canada, 2021, pp. 3071–3079.
|
| [136] |
Y. H. Chen, W. Li, C. Sakaridis, D. X. Dai, and L. Van Gool, “Domain adaptive faster R-CNN for object detection in the wild,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 3339–3348.
|
| [137] |
H. Zhang, G. Y. Luo, Y. L. Tian, K. F. Wang, H. B. He, and F. Y. Wang, “A virtual-real interaction approach to object instance segmentation in traffic scenes,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 2, pp. 863–875, Feb. 2021. doi: 10.1109/TITS.2019.2961145
|
| [138] |
X. Ouyang, Y. Cheng, Y. F. Jiang, C. L. Li, and P. Zhou, “Pedestrian-synthesis-GAN: Generating pedestrian data in real scene and beyond,” arXiv preprint arXiv: 1804.02047, 2018.
|
| [139] |
Z. Q. Zheng, Y. Wu, X. R. Han, and J. B. Shi, “ForkGAN: Seeing into the rainy night,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 155–170.
|
| [140] |
A. Vobecký, D. Hurych, M. Uřičář, P. Pérez, and J. Sivic, “Artificial dummies for urban dataset augmentation,” in Proc. AAAI Conf. Artif. Intell., vol. 35, no. 3, pp. 2692–2700, May 2021.
|
| [141] |
A. El Sallab, I. Sobh, M. Zahran, and M. Shawky, “Unsupervised neural sensor models for synthetic LiDAR data augmentation,” arXiv preprint arXiv: 1911.10575, 2019.
|
| [142] |
J. Fang, D. F. Zhou, F. L. Yan, T. T. Zhao, F. H. Zhang, Y. Ma, L. Wang, and R. G. Yang, “Augmented LiDAR simulator for autonomous driving,” IEEE Robot. Autom. Lett., vol. 5, no. 2, pp. 1931–1938, Apr. 2020. doi: 10.1109/LRA.2020.2969927
|
| [143] |
A. Lehner, S. Gasperini, A. Marcos-Ramiro, M. Schmidt, M. A. N. Mahani, N. Navab, B. Busam, and F. Tombari, “3D-VField: Adversarial augmentation of point clouds for domain generalization in 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 17274–17283.
|
| [144] |
M. Hahner, C. Sakaridis, M. Bijelic, F. Heide, F. Yu, D. X. Dai, and L. Van Gool, “LiDAR snowfall simulation for robust 3D object detection,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 16343–16353.
|
| [145] |
J. MarÍn, D. Vázquez, D. Gerónimo, and A. M. López, “Learning appearance in virtual scenarios for pedestrian detection,” in Proc. IEEE Computer Society Conf. Computer Vision and Pattern Recognition, San Francisco, USA, 2010, pp. 137–144.
|
| [146] |
A. Gaidon, Q. Wang, Y. Cabon, and E. Vig, “VirtualWorlds as proxy for multi-object tracking analysis,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 4340–4349.
|
| [147] |
X. Li, K. F. Wang, Y. L. Tian, L. Yan, F. Deng, and F. Y. Wang, “The paralleleye dataset: A large collection of virtual images for traffic vision research,” IEEE Trans. Intell. Transp. Syst., vol. 20, no. 6, pp. 2072–2084, Jun. 2084.
|
| [148] |
A. Savkin, T. Lapotre, K. Strauss, U. Akbar, and F. Tombari, “Adversarial appearance learning in augmented cityscapes for pedestrian recognition in autonomous driving,” in Proc. IEEE Int. Conf. Robotics and Autom., Paris, France, 2020, pp. 3305–3311.
|
| [149] |
K. Strauss, A. Savkin, and F. Tombari, “Attention-based adversarial appearance learning of augmented pedestrians,” arXiv preprint arXiv: 2107.02673, 2021.
|
| [150] |
R. Zhi, Z. J. Guo, W. Q. Zhang, B. F. Wang, V. Kaiser, J. Wiederer, and F. B. Flohr, “Pose-guided person image synthesis for data augmentation in pedestrian detection,” in Proc. IEEE Intelligent Vehicles Symp., Nagoya, Japan, 2021, pp. 1493–1500.
|
| [151] |
S. Manivasagam, S. L. Wang, K. Wong, W. Y. Zeng, M. Sazanovich, S. H. Tan, B. Yang, W. C. Ma, and R. Urtasun, “LiDARsim: Realistic LiDAR simulation by leveraging the real world,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 11164–11173.
|
| [152] |
X. L. Pan, Y. R. You, Z. Y. Wang, and C. W. Lu, “Virtual to real reinforcement learning for autonomous driving,” in Proc. British Machine Vision Conf., London, UK, 2017.
|
| [153] |
L. N. Yang, X. D. Liang, T. R. Wang, and E. Xing, “Real-to-virtual domain unification for end-to-end autonomous driving,” in Proc. 15th European Conf. Computer Vision, 2018, pp. 553–570.
|
| [154] |
Z. H. Yin, C. R. Li, L. T. Sun, M. Tomizuka, and W. Zhan, “Iterative imitation policy improvement for interactive autonomous driving,” arXiv preprint arXiv: 2109.01288, 2021.
|
| [155] |
J. Y. Zhou, R. Wang, X. Liu, Y. F. Jiang, S. Jiang, J. M. Tao, J. H. Miao, and S. Y. Song, “Exploring imitation learning for autonomous driving with feedback synthesizer and differentiable rasterization,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Prague, Czech Republic, 2021, pp. 1450–1457.
|
| [156] |
M. Bansal, A. Krizhevsky, and A. S. Ogale, “ChauffeurNet: Learning to drive by imitating the best and synthesizing the worst,” in Proc. Robotics: Science and Systems XV, Freiburg im Breisgau, Germany, 2019.
|
| [157] |
O. Scheel, L. Bergamini, M. Wołczyk, B. Osiński, and P. Ondruska, “Urban driver: Learning to drive from real-world demonstrations using policy gradients,” in Proc. 5th Conf. Robot Learning, London, UK, 2021, pp. 718–728.
|
| [158] |
A. Amini, I. Gilitschenski, J. Phillips, J. Moseyko, R. Banerjee, S. Karaman, and D. Rus, “Learning robust control policies for end-to-end autonomous driving from data-driven simulation,” IEEE Robot. Autom. Lett., vol. 5, no. 2, pp. 1143–1150, Apr. 2020. doi: 10.1109/LRA.2020.2966414
|
| [159] |
A. Amini, T. H. Wang, I. Gilitschenski, W. Schwarting, Z. J. Liu, S. Han, S. Karaman, and D. Rus, “VISTA 2.0: An open, data-driven simulator for multimodal sensing and policy learning for autonomous vehicles,” in Proc. Int. Conf. Robotics and Autom., Philadelphia, USA, 2022, pp. 2419–2426.
|
| [160] |
B. Osiński, A. Jakubowski, P. Zięcina, P. Miłoś, C. Galias, S. Homoceanu, and H. Michalewski, “Simulation-based reinforcement learning for real-world autonomous driving,” in Proc. IEEE Int. Conf. Robotics and Autom., Paris, France, 2020, pp. 6411–6418.
|
| [161] |
T. H. Wang, A. Amini, W. Schwarting, I. Gilitschenski, S. Karaman, and D. Rus, “Learning interactive driving policies via data-driven simulation,” in Proc. Int. Conf. Robotics and Autom., Philadelphia, USA, 2022, pp. 7745–7752.
|
| [162] |
W. Yuan, M. Yang, C. X. Wang, and B. Wang, “VRDriving: A virtual-to-real autonomous driving framework based on adversarial learning,” IEEE Trans. Cogn. Dev. Syst., vol. 13, no. 4, pp. 912–921, Dec. 2021. doi: 10.1109/TCDS.2020.3006621
|
| [163] |
A. El Sallab, I. Sobh, M. Zahran, and N. Essam, “LiDAR Sensor modeling and Data augmentation with GANs for Autonomous driving,” arXiv preprint arXiv: 1905.07290, 2019.
|
| [164] |
R. P. Saputra, N. Rakicevic, and P. Kormushev, “Sim-to-real learning for casualty detection from ground projected point cloud data,” in Proc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems, Macau, China, 2019, pp. 3918–3925.
|
| [165] |
R. Mitchell, J. Fletcher, J. Panerati, and A. Prorok, “Multi-vehicle mixed reality reinforcement learning for autonomous multi-lane driving,” in Proc. 19th Int. Conf. Autonomous Agents and Multiagent Systems, Auckland, New Zealand, 2020, pp. 1928–1930.
|
| [166] |
A. Stocco, B. Pulfer, and P. Tonella, “Mind the gap! A study on the transferability of virtual vs physical-world testing of autonomous driving systems,” arXiv preprint arXiv: 2112.11255, 2021.
|

Figures(15) / Tables(13)






 DownLoad:
DownLoad: