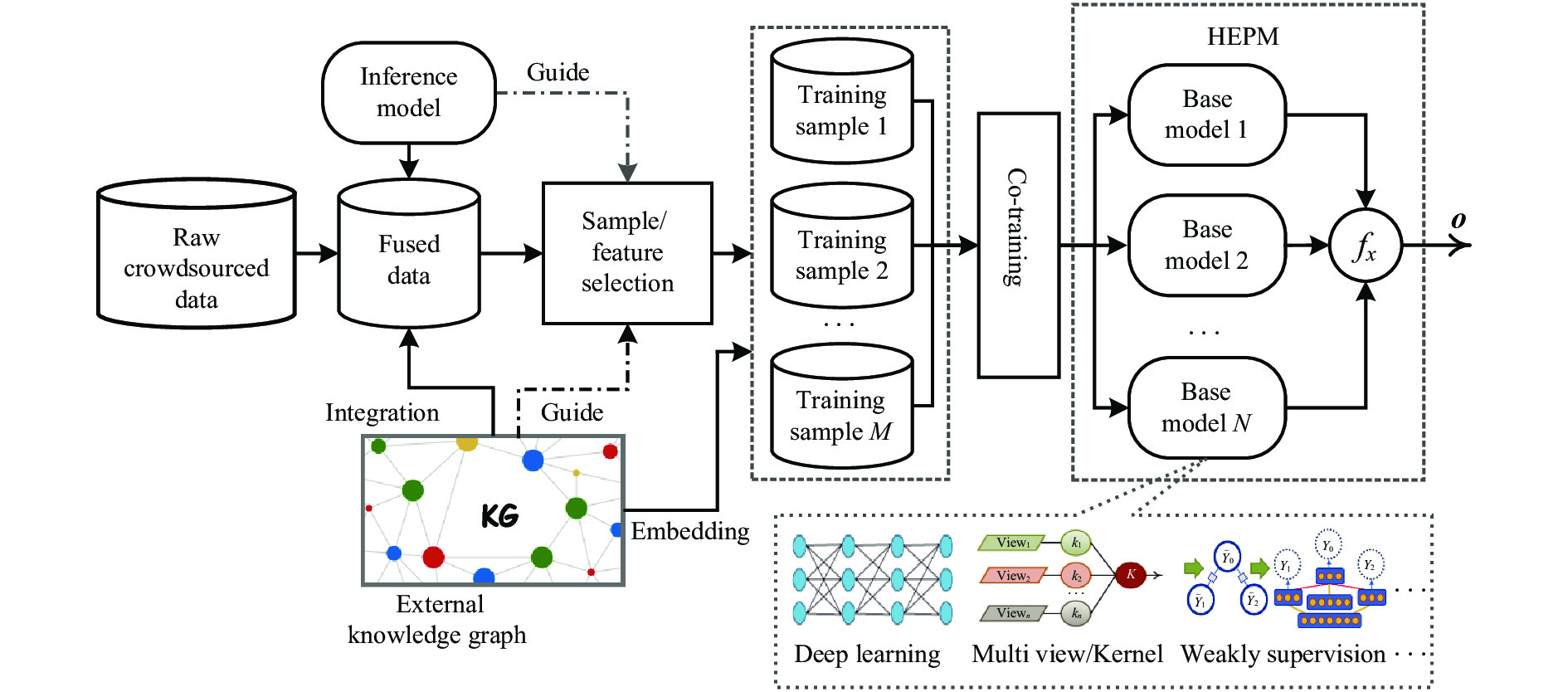
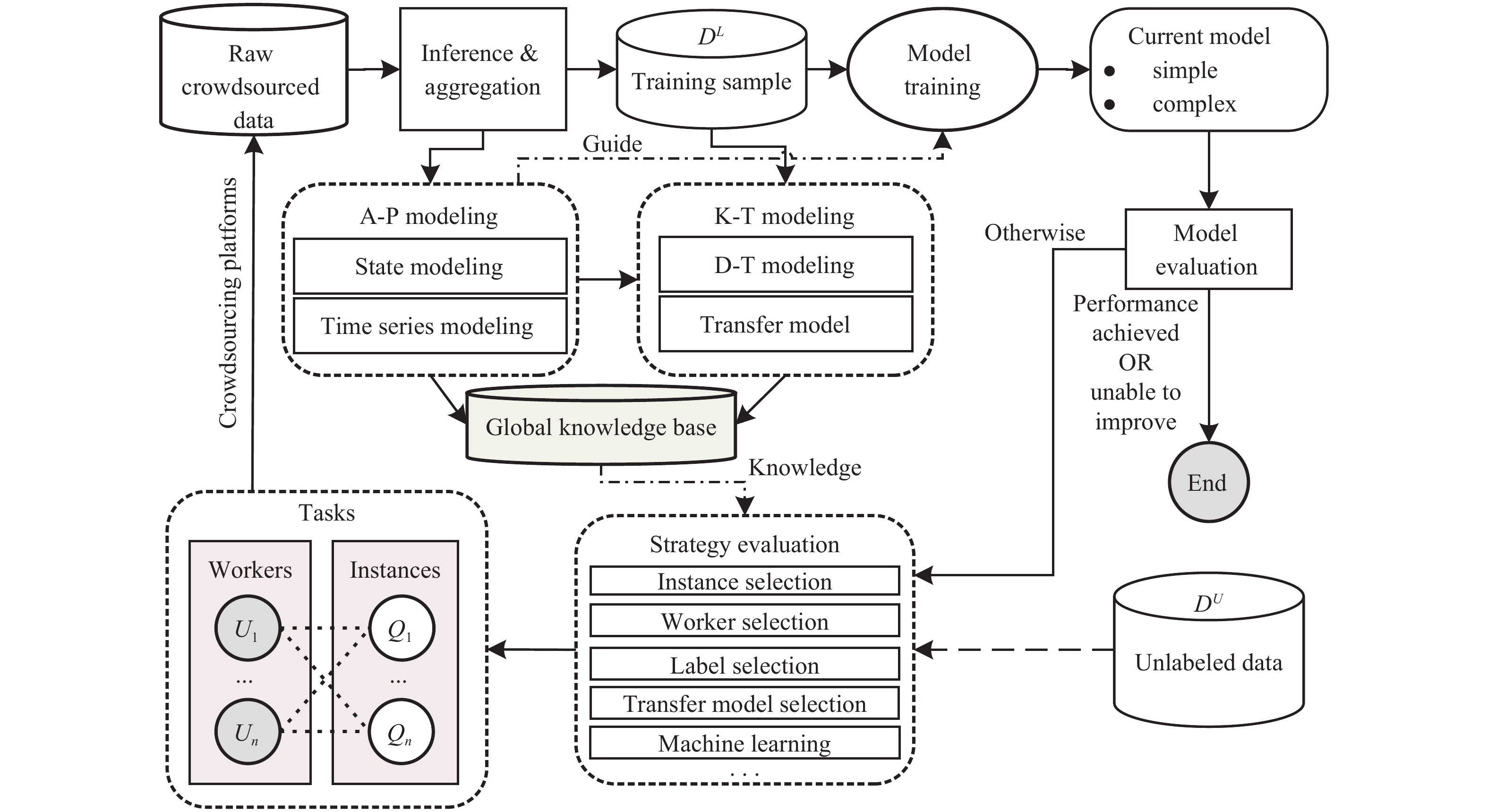
A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 9
Issue 5
Volume 9
Issue 5
IEEE/CAA Journal of Automatica Sinica
| Citation: | J. Zhang, “Knowledge learning with crowdsourcing: A brief review and systematic perspective,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 5, pp. 749–762, May 2022. doi: 10.1109/JAS.2022.105434

|

| [1] |
J. Howe, “The rise of crowdsourcing,” Wired Magazine, vol. 14, no. 6, pp. 1–4, 2006.
|
| [2] |
M. Sabou, K. Bontcheva, and A. Scharl, “Crowdsourcing research opportunities: Lessons from natural language processing,” in Proc. 12th Int. Conf. Knowl. Management Knowl. Technologies, 2012, pp. 1–8.
|
| [3] |
A. Kovashka, O. Russakovsky, L. Fei-Fei, K. Grauman, et al., “Crowdsourcing in computer vision,” Foundations and Trends® Comput. Graphics Vis., vol. 10, no. 3, pp. 177–243, 2016.
|
| [4] |
B. M. Good and A. I. Su, “Crowdsourcing for bioinformatics,” Bioinformatics, vol. 29, no. 16, pp. 1925–1933, 2013. doi: 10.1093/bioinformatics/btt333
|
| [5] |
Y. Li, N. Du, C. Liu, Y. Xie, W. Fan, Q. Li, J. Gao, and H. Sun, “Reliable medical diagnosis from crowdsourcing: Discover trustworthy answers from non-experts,” in Proc. 10th ACM Int. Conf. Web Search Data Mining, 2017, pp. 253–261.
|
| [6] |
J. W. Vaughan, “Making better use of the crowd: How crowdsourcing can advance machine learning research,” J. Mach. Learn. Res., vol. 18, pp. 7026–7071, 2017.
|
| [7] |
V. S. Sheng, F. Provost, and P. G. Ipeirotis, “Get another label? Improving data quality and data mining using multiple, noisy labelers,” in Proc. 14th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2008, pp. 614–622.
|
| [8] |
R. Snow, B. O’Connor, D. Jurafsky, and A. Y. Ng, “Cheap and fast – But is it good? Evaluating non-expert annotations for natural language tasks,” in Proc. Conf. Empirical Methods Natural Language Process, 2008, pp. 254–263.
|
| [9] |
A. Dawid and A. M. Skene, “Maximum likelihood estimation of observer error-rates using the EM algorithm,” J. Royal Statistical Society:Series C (Appl. Statistics)
|
| [10] |
J. Zhang, X. Wu, and V. S. Sheng, “Learning from crowdsourced labeled data: A survey,” Artif. Intell. Rev., vol. 46, no. 4, pp. 543–576, 2016. doi: 10.1007/s10462-016-9491-9
|
| [11] |
Y. Zheng, G. Li, Y. Li, C. Shan, and R. Cheng, “Truth inference in crowdsourcing: Is the problem solved?” Proc. VLDB Endowment, vol. 10, no. 5, pp. 541–552, 2017. doi: 10.14778/3055540.3055547
|
| [12] |
V. C. Raykar, S. Yu, L. H. Zhao, G. H. Valadez, C. Florin, L. Bogoni, and L. Moy, “Learning from crowds,” J. Mach. Learn. Res., vol. 11, pp. 1297–1322, 2010.
|
| [13] |
H. Kajino, Y. Tsuboi, and H. Kashima, “A convex formulation of learning from crowds,” in Proc. 26th AAAI Conf. Artif. Intell., 2012, pp. 73–79.
|
| [14] |
W. Bi, L. Wang, J. T. Kwok, and Z. Tu, “Learning to predict from crowdsourced data,” in Proc. 30th Conf. Uncertainty Artif. Intell., 2014, pp. 82–91.
|
| [15] |
P. Welinder and P. Perona, “Online crowdsourcing: Rating annotators and obtaining cost-effective labels,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognition Workshops, 2010, pp. 25–32.
|
| [16] |
M. Rokicki, S. Chelaru, S. Zerr, and S. Siersdorfer, “Competitive game designs for improving the cost effectiveness of crowdsourcing,” in Proc. 23rd ACM Int. Conf. Inf. Knowl. Management, 2014, pp. 1469–1478.
|
| [17] |
S.-J. Huang, J.-L. Chen, X. Mu, and Z.-H. Zhou, “Cost-effective active learning from diverse labelers,” in Proc. 26th Int. Joint Conf. Artif. Intell., 2017, pp. 1879–1885.
|
| [18] |
F. Daniel, Kucherbaev, C. Cappiello, B. Benatallah, and M. Allahbakhsh, “Quality control in crowdsourcing: A survey of quality attributes, assessment techniques, and assurance actions,” ACM Comput. Surveys, vol. 51, no. 1, Article No. 7, 2018.
|
| [19] |
A. I. Chittilappilly, L. Chen, and S. Amer-Yahia, “A survey of generalpurpose crowdsourcing techniques,” IEEE Trans. Knowl. Data Eng., vol. 28, no. 9, pp. 2246–2266, 2016. doi: 10.1109/TKDE.2016.2555805
|
| [20] |
V. S. Sheng and J. Zhang, “Machine learning with crowdsourcing: A brief summary of the past research and future directions,” in Proc. 33rd AAAI Conf. Artif. Intell., 2019, pp. 9837–9843.
|
| [21] |
J. Whitehill, T.-f. Wu, J. Bergsma, J. R. Movellan, and P. L. Ruvolo, “Whose vote should count more: Optimal integration of labels from labelers of unknown expertise,” in Advances Neural Inf. Process. Syst., vol. 22, 2009, pp. 2035–2043.
|
| [22] |
A. Kurve, D. J. Miller, and G. Kesidis, “Multicategory crowdsourcing accounting for variable task difficulty, worker skill, and worker intention,” IEEE Trans. Knowl. Data Eng., vol. 27, no. 3, pp. 794–809, 2015. doi: 10.1109/TKDE.2014.2327026
|
| [23] |
Q. Liu, J. Peng, and A. T. Ihler, “Variational inference for crowdsourcing,” in Advances Neural Inf. Process. Syst., vol. 25, 2012, pp. 692–700.
|
| [24] |
M. A. Gemalmaz and M. Yin, “Accounting for confirmation bias in crowdsourced label aggregation,” in Proc. 30th Int. Joint Conf. Artif. Intell., 2021.
|
| [25] |
P. Welinder, S. Branson, P. Perona, and S. J. Belongie, “The multidimensional wisdom of crowds,” in Advances Neural Inf. Process. Syst., vol. 23, 2010, pp. 2424–2432.
|
| [26] |
H.-C. Kim and Z. Ghahramani, “Bayesian classifier combination,” in Artif. Intell. and Statistics, 2012, pp. 619–627.
|
| [27] |
G. Demartini, D. E. Difallah, and P. Cudré-Mauroux, “Zencrowd: Leveraging probabilistic reasoning and crowdsourcing techniques for large-scale entity linking,” in Proc. 21st Int. Conf. World Wide Web, 2012, pp. 469–478.
|
| [28] |
T. Tian and J. Zhu, “Uncovering the latent structures of crowd labeling,” in Pacific-Asia Conf. Knowl. Discovery Data Mining, 2015, pp. 392–404.
|
| [29] |
D. Zhou, S. Basu, Y. Mao, and J. C. Platt, “Learning from the wisdom of crowds by minimax entropy,” in Advances Neural Inf. Process. Syst., vol. 25, 2012, pp. 2195–2203.
|
| [30] |
M. Venanzi, J. Guiver, G. Kazai, P. Kohli, and M. Shokouhi, “Community-based Bayesian aggregation models for crowdsourcing,” in Proc. 23rd Int. Conf. World Wide Web, 2014, pp. 155–164.
|
| [31] |
Y. Zhang, X. Chen, D. Zhou, and M. I. Jordan, “Spectral methods meet EM: A provably optimal algorithm for crowdsourcing,” J. Mach. Learn. Res., vol. 17, no. 1, pp. 3537–3580, 2016.
|
| [32] |
Y. Li, B. Rubinstein, and T. Cohn, “Exploiting worker correlation for label aggregation in crowdsourcing,” in Int. Conf. Mach. Learn., 2019, pp. 3886–3895.
|
| [33] |
D. Zhou, Q. Liu, J. Platt, and C. Meek, “Aggregating ordinal labels from crowds by minimax conditional entropy,” in Proc. 31st Int. Conf. Mach. Learn., 2014, pp. 262–270.
|
| [34] |
S.-Y. Li, S.-J. Huang, and S. Chen, “Crowdsourcing aggregation with deep Bayesian learning,” Science China Inf. Sciences, vol. 64, pp. 1–11, 2021.
|
| [35] |
J. Bragg, Mausam, and D. S. Weld, “Crowdsourcing multi-label classification for taxonomy creation,” in Proc. 1st AAAI Conf. Human Comput. Crowdsourcing, 2013, pp. 25–33.
|
| [36] |
L. Duan, S. Oyama, H. Sato, and M. Kurihara, “Separate or joint? Estimation of multiple labels from crowdsourced annotations” Expert Syst. Appl., vol. 41, no. 13, pp. 5723–5732, 2014. doi: 10.1016/j.eswa.2014.03.048
|
| [37] |
J. Zhang and X. Wu, “Multi-label inference for crowdsourcing,” in Proc. 24th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2018, pp. 2738–2747.
|
| [38] |
J. Zhang and X. Wu, “Multi-label truth inference for crowdsourcing using mixture models,” IEEE Trans. Knowl. Data Eng., vol. 33, pp. 2083–2095, 2021.
|
| [39] |
H. J. Jung and M. Lease, “Improving consensus accuracy via Z-score and weighted voting.” in Proc. 3rd Human Comput. Workshop, 2011.
|
| [40] |
D. R. Karger, S. Oh, and D. Shah, “Budget-optimal crowdsourcing using low-rank matrix approximations,” in Proc. 49th Annual Allerton Conf. Communication, Control, and Comput., 2011, pp. 284–291.
|
| [41] |
A. Ghosh, S. Kale, and P. McAfee, “Who moderates the moderators?: Crowdsourcing abuse detection in user-generated content,” in Proc. 12th ACM Conf. Electronic Commerce. ACM, 2011, pp. 167–176.
|
| [42] |
N. Dalvi, A. Dasgupta, R. Kumar, and V. Rastogi, “Aggregating crowdsourced binary ratings,” in Proc. 22nd Int. Conf. World Wide Web, 2013, pp. 285–294.
|
| [43] |
J. Zhang, X. Wu, and V. S. Sheng, “Imbalanced multiple noisy labeling,” IEEE Trans. Knowl. Data Eng., vol. 27, no. 2, pp. 489–503, 2015. doi: 10.1109/TKDE.2014.2327039
|
| [44] |
P. Donmez, J. G. Carbonell, and J. Schneider, “Efficiently learning the accuracy of labeling sources for selective sampling,” in Proc. 15th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2009, pp. 259–268.
|
| [45] |
B. I. Aydin, Y. S. Yilmaz, Y. Li, Q. Li, J. Gao, and M. Demirbas, “Crowdsourcing for multiple-choice question answering,” in Proc. 30th AAAI Conf. Artif. Intell., 2014, pp. 2946–2953.
|
| [46] |
F. Tao, L. Jiang, and C. Li, “Label similarity-based weighted soft majority voting and pairing for crowdsourcing,” Knowl. Inf. Syst., vol. 62, pp. 2521–2538, 2020. doi: 10.1007/s10115-020-01475-y
|
| [47] |
Q. Li, Y. Li, J. Gao, L. Su, B. Zhao, M. Demirbas, W. Fan, and J. Han, “A confidence-aware approach for truth discovery on long-tail data,” Proc. VLDB Endow., vol. 8, pp. 425–436, 2014. doi: 10.14778/2735496.2735505
|
| [48] |
Q. Li, Y. Li, J. Gao, B. Zhao, W. Fan, and J. Han, “Resolving conflicts in heterogeneous data by truth discovery and source reliability estimation,” in Proc. ACM SIGMOD Int. Conf. Management Data, 2014, pp. 1187–1198.
|
| [49] |
T. Tian and J. Zhu, “Max-margin majority voting for learning from crowds,” in Advances Neural Inf. Process. Syst., vol. 28, 2015, pp. 1621–1629.
|
| [50] |
Y. Zhou and J. He, “Crowdsourcing via tensor augmentation and completion,” in Proc. 25th Int. Joint Conf. Artif. Intell., 2016, pp. 2435–2441.
|
| [51] |
L. Jiang, H. Zhang, F. Tao, and C. Li, “Learning from crowds with multiple noisy label distribution propagation,” IEEE Trans. Neural Netw. Learn. Syst., 2021.
|
| [52] |
J. Zhang, V. S. Sheng, J. Wu, and X. Wu, “Multi-class ground truth inference in crowdsourcing with clustering,” IEEE Trans. Knowl. Data Eng., vol. 28, no. 4, pp. 1080–1085, 2016. doi: 10.1109/TKDE.2015.2504974
|
| [53] |
A. Gaunt, D. Borsa, and Y. Bachrach, “Training deep neural nets to aggregate crowdsourced responses,” in Proc. 32nd Conf. Uncertainty Artif. Intell., 2016, pp. 242–251.
|
| [54] |
L. Yin, J. Han, W. Zhang, and Y. Yu, “Aggregating crowd wisdoms with label-aware autoencoders,” in Proc. 26th Int. Joint Conf. Artif. Intell., 2017, pp. 1325–1331.
|
| [55] |
F. Rodrigues and F. Pereira, “Deep learning from crowds,” in Proc. 32nd AAAI Conf. Artif. Intell., 2018, pp. 1611–1618.
|
| [56] |
Z. Chen, H. Wang, H. Sun, P. Chen, T. Han, X. Liu, and J. Yang, “Structured probabilistic end-to-end learning from crowds,” in Proc. 29th Int. Joint Conf. Artif. Intell., 2020, pp. 1512–1518.
|
| [57] |
J. Tu, G. Yu, C. Domeniconi, J. Wang, G. Xiao, and M. Guo, “Multilabel crowd consensus via joint matrix factorization,” Knowl. Inf. Syst., vol. 62, pp. 1341–1369, 2020. doi: 10.1007/s10115-019-01386-7
|
| [58] |
J. Zhang, X. Wu, and V. S. Sheng, “Imbalanced multiple noisy labeling for supervised learning,” in Proc. 27th AAAI Conf. Artif. Intell., 2013, pp. 1651–1652.
|
| [59] |
C. Eickhoff, “Cognitive biases in crowdsourcing,” in Proc. 11th ACM Int. Conf. Web Search Data Mining, pp. 162–170, 2018.
|
| [60] |
D. L. Barbera, K. Roitero, G. Demartini, S. Mizzaro, and D. Spina, “Crowdsourcing truthfulness: The impact of judgment scale and assessor bias,” European Conf. Inf. Retrieval, vol. 12036, pp. 207–214, 2020.
|
| [61] |
E. Kamar, A. Kapoor, and E. Horvitz, “Identifying and accounting for task-dependent bias in crowdsourcing,” in Proc. 3rd AAAI Conf. Human Comput. Crowdsourcing, 2015, pp. 92–101.
|
| [62] |
N. M. Barbosa and M. Chen, “Rehumanized crowdsourcing: A labeling framework addressing bias and ethics in machine learning,” in Proc. CHI Conf. Human Factors Comput. Syst., pp. 1–12, 2019.
|
| [63] |
F. K. Khattak and A. Salleb-Aouissi, “Quality control of crowd labeling through expert evaluation,” in Proc. NIPS 2nd Workshop on Comput. Social Science and the Wisdom of Crowds, vol. 2, 2011.
|
| [64] |
T. Bonald and R. Combes, “A minimax optimal algorithm for crowdsourcing,” in Advances Neural Inf. Process. Syst., vol. 30, 2017, pp. 4355–4363.
|
| [65] |
S. Oyama, Y. Baba, Y. Sakurai, and H. Kashima, “Accurate integration of crowdsourced labels using workers’ self-reported confidence scores,” in Proc. 22th Int. Joint Conf. Artif. Intell., 2013, pp. 2554–2560.
|
| [66] |
M. Liu, L. Jiang, J. Liu, X. Wang, J. Zhu, and S. Liu, “Improving learning-from-crowds through expert validation,” in Proc. 26th Int. Joint Conf. Artif. Intell., 2017, pp. 2329–2336.
|
| [67] |
J. Zhang, V. S. Sheng, and T. Li, “Label aggregation for crowdsourcing with bi-layer clustering,” in Proc. 40th Int. ACM SIGIR Conf. Res. Development Inf. Retrieval, 2017, pp. 921–924.
|
| [68] |
J. Zhang, V. S. Sheng, T. Li, and X. Wu, “Improving crowdsourced label quality using noise correction,” IEEE Trans. Neural Netw. Learn. Syst., vol. 29, no. 5, pp. 1675–1688, 2018. doi: 10.1109/TNNLS.2017.2677468
|
| [69] |
W. Wang, X.-Y. Guo, S.-Y. Li, Y. Jiang, and Z.-H. Zhou, “Obtaining high-quality label by distinguishing between easy and hard items in crowdsourcing,” in Proc. 26th Int. Joint Conf. Artif. Intell., 2017, pp. 2964–2970.
|
| [70] |
J. Liu, F. Tang, L. Chen, and Y. Zhu, “Exploiting predicted answer in label aggregation to make better use of the crowd wisdom,” Inf. Sciences, vol. 574, pp. 66–83, 2021. doi: 10.1016/j.ins.2021.05.060
|
| [71] |
G. Han, J. Tu, G. Yu, J. Wang, and C. Domeniconi, “Crowdsourcing with multiple-source knowledge transfer,” in Proc. 29th Int. Joint Conf. Artif. Intell., 2020, pp. 2908–2914.
|
| [72] |
S. Xu and J. Zhang, “Crowdsourcing with meta-knowledge transfer,” in Proc. 36th AAAI Conf. Artif. Intell., 2022.
|
| [73] |
Y. Yan, R. Rosales, G. Fung, M. Schmidt, G. Hermosillo, L. Bogoni, L. Moy, and J. G. Dy, “Modeling annotator expertise: Learning when everybody knows a bit of something,” in Proc. 13 Int. Conf. Artif. Intell. Stat., 2010, pp. 932–939.
|
| [74] |
Y. Yan, R. Rosales, G. Fung, and J. G. Dy, “Active learning from crowds,” in Proc. 28th Int. Conf. Mach. Learn., vol. 11, 2011, pp. 1161–1168.
|
| [75] |
Y. Yan, R. Rosales, G. Fung, S. Ramanathan, and J. G. Dy, “Learning from multiple annotators with varying expertise,” Mach. Learn., vol. 95, pp. 291–327, 2013.
|
| [76] |
Z. Zhao, F. Wei, M. Zhou, W. Chen, and W. Ng, “Crowd-selection query processing in crowdsourcing databases: A task-driven approach,” in Proc. 18th Int. Conf. Extending Database Tech., 2015, pp. 397–408.
|
| [77] |
A. Iscen, G. Tolias, Y. Avrithis, O. Chum, and C. Schmid, “Graph convolutional networks for learning with few clean and many noisy labels,” in Proc. European Conf. Comput. Vis., 2020, pp. 286–302.
|
| [78] |
P. Cao, Y. Xu, Y. Kong, and Y. Wang, “Max-MIG: An information theoretic approach for joint learning from crowds,” ArXiv, vol. abs/1905.13436, 2019.
|
| [79] |
S. Li, S. Ge, Y. Hua, C. Zhang, H. Wen, T. Liu, and W. Wang, “Coupled-view deep classifier learning from multiple noisy annotators,” in Proc. 34th AAAI Conf. Artif. Intell., 2020, pp. 4667–4674.
|
| [80] |
L. Yin, Y. Liu, W. Zhang, and Y. Yu, “Aggregating crowd wisdom with side information via a clustering-based label-aware autoencoder,” in Proc. 29th Int. Joint Conf. Artif. Intell., 2020, pp. 1542–1548.
|
| [81] |
J. Deng, J. Krause, and F.-F. Li, “Fine-grained crowdsourcing for fine-grained recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognition, 2013, pp. 580–587.
|
| [82] |
J. Y. Zou, K. Chaudhuri, and A. T. Kalai, “Crowdsourcing feature discovery via adaptively chosen comparisons,” in Proc. 3rd AAAI Conf. Human Comput. Crowdsourcing, 2015, pp. 198–205.
|
| [83] |
H. Kajino, Y. Tsuboi, and H. Kashima, “Clustering crowds,” in Proc. 27th AAAI Conf. Artif. Intell., 2013, pp. 1120–1127.
|
| [84] |
P. Donmez and J. G. Carbonell, “Proactive learning: Cost-sensitive active learning with multiple imperfect oracles,” in Proc. 17th ACM Conf. Inf. Knowl. Management, 2008, pp. 619–628.
|
| [85] |
V. S. Sheng, “Simple multiple noisy label utilization strategies,” in Proc. IEEE 11th Int. Conf. Data Mining, 2011, pp. 635–644.
|
| [86] |
S. Lomax and S. Vadera, “A survey of cost-sensitive decision tree induction algorithms,” ACM Comput. Surv., vol. 45, no. 16, pp. 1–35, 2013.
|
| [87] |
K. Atarashi, S. Oyama, and M. Kurihara, “Semi-supervised learning from crowds using deep generative models,” in Proc. 32nd AAAI Conf. Artif. Intell., 2018, pp. 1555–1562.
|
| [88] |
W. Shi, V. S. Sheng, X. Li, and B. Gu, “Semi-supervised multi-label learning from crowds via deep sequential generative model,” in Proc. 26th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, pp. 1141–1149, 2020.
|
| [89] |
D. Wang, Tiwari, M. Shorfuzzaman, and I. Schmitt, “Deep neural learning on weighted datasets utilizing label disagreement from crowdsourcing,” Comput. Netw., vol. 196, pp. 108–227, 2021.
|
| [90] |
C. H. Lin, Mausam, and D. S. Weld, “To re (label), or not to re (label),” in Proc. 2nd AAAI Conf. Human Comput. Crowdsourcing, 2014, pp. 151–158.
|
| [91] |
J. Zhang, M. Wu, and V. S. Sheng, “Ensemble learning from crowds,” IEEE Trans. Knowl. Data Eng., vol. 31, no. 8, pp. 1506–1519, 2018.
|
| [92] |
Q. Wang, Z. Mao, B. Wang, and L. Guo, “Knowledge graph embedding: A survey of approaches and applications,” IEEE Trans. Knowl. Data Eng., vol. 29, no. 12, pp. 2724–2743, 2017. doi: 10.1109/TKDE.2017.2754499
|
| [93] |
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Yu, “A comprehensive survey on graph neural networks,” IEEE Trans. Neural Netw. Learn. Syst., vol. 32, pp. 4–24, 2019.
|
| [94] |
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolution networks,” in Proc. Int. Conf. Learn. Representation, 2017.
|
| [95] |
Y. Zhou and J. He, “A randomized approach for crowdsourcing in the presence of multiple views,” in Proc. IEEE Int. Conf. Data Mining, pp. 685–694, 2017.
|
| [96] |
M. Fang, X. Zhu, B. Li, W. Ding, and X. Wu, “Self-taught active learning from crowds,” in Proc. IEEE 12th Int. Conf. Data Mining, 2012, pp. 858–863.
|
| [97] |
A. J. Ratner, C. M. De Sa, S. Wu, D. Selsam, and C. Ré, “Data programming: Creating large training sets, quickly,” in Advances Neural Inf. Process. Syst., vol. 29, 2016, pp. 3567–3575.
|
| [98] |
C.-J. Hsieh, N. Natarajan, and I. S. Dhillon, “PU learning for matrix completion,” in Proc. 32nd Int. Conf. Mach. Learn., 2015, pp. 2445–2453.
|
| [99] |
X. Zou, Z. Zhang, Z. He, and L. Shi, “Unsupervised ensemble learning with noisy label correction,” in Proc. 44th Int. ACM SIGIR Conf. Res. Development Inf. Retrieval, 2021, pp. 2308–2312.
|
| [100] |
G. Li, J. Wang, Y. Zheng, and M. J. Franklin, “Crowdsourced data management: A survey,” IEEE Trans. Knowl. Data Eng., vol. 28, no. 9, pp. 2296–2319, 2016. doi: 10.1109/TKDE.2016.2535242
|
| [101] |
J. Zhang, X. Wu, and V. S. Shengs, “Active learning with imbalanced multiple noisy labeling,” IEEE Trans. Cybernetics, vol. 45, no. 5, pp. 1095–1107, 2015. doi: 10.1109/TCYB.2014.2344674
|
| [102] |
C. Long, G. Hua, and A. Kapoor, “Active visual recognition with expertise estimation in crowdsourcing,” in Proc. IEEE Int. Conf. Comput. Vis., 2013, pp. 3000–3007.
|
| [103] |
S.-Y. Li, Y. Jiang, N. V. Chawla, and Z.-H. Zhou, “Multi-label learning from crowds,” IEEE Trans. Knowl. Data Eng., vol. 31, pp. 1369–1382, 2019. doi: 10.1109/TKDE.2018.2857766
|
| [104] |
G. Yu, J. Tu, J. Wang, C. Domeniconi, and X. Zhang, “Active multilabel crowd consensus,” IEEE Trans. Neural Netw. Learn. Syst., 2020.
|
| [105] |
C. H. Lin, Mausam, and D. S. Weld, “Re-active learning: Active learning with relabeling,” in Proc. 30th AAAI Conf. Artif. Intell., 2016, pp. 1845–1852.
|
| [106] |
F. Rodrigues, F. Pereira, and B. Ribeiro, “Gaussian process classification and active learning with multiple annotators,” in Proc. 31st Int. Conf. Mach. Learn., 2014, pp. 433–441.
|
| [107] |
H. J. Jung, Y. Park, and M. Lease, “Predicting next label quality: A time-series model of crowdwork,” in Proc. 2nd AAAI Conf. Human Comput. Crowdsourcing, 2014, pp. 87–95.
|
| [108] |
K. Mo, E. Zhong, and Q. Yang, “Cross-task crowdsourcing,” in Proc. 19th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2013, pp. 677–685.
|
| [109] |
M. Fang, J. Yin, and X. Zhu, “Knowledge transfer for multi-labeler active learning,” in Joint European Conf. Mach. Learn. Knowl. Discovery Databases, 2013, pp. 273–288.
|
| [110] |
M. Fang, J. Yin, and D. Tao, “Active learning for crowdsourcing using knowledge transfer,” in Proc. 28th AAAI Conf. Artif. Intell., 2014, pp. 1809–1815.
|
| [111] |
Z. Zhao, D. Yan, W. Ng, and S. Gao, “A transfer learning based framework of crowd-selection on twitter,” in Proc. 19th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2013, pp. 1514–1517.
|
| [112] |
X. Zhu, “Machine teaching: An inverse problem to machine learning and an approach toward optimal education,” in Proc. 29th AAAI Conf. Artif. Intell., 2015, pp. 4083–4087.
|
| [113] |
J. Zhang, H. Wang, S. Meng, and V. S. Sheng, “Interactive learning with proactive cognition enhancement for crowd workers,” in Proc. 34th AAAI Conf. Artif. Intell., 2020, pp. 541–547.
|
| [114] |
Q. V. H. Nguyen, T. T. Nguyen, N. T. Lam, and K. Aberer, “BATC: A benchmark for aggregation techniques in crowdsourcing,” in Proc. 36th Int. ACM SIGIR Conf. Res. Development Inf. Retrieval, 2013, pp. 1079–1080.
|
| [115] |
A. Sheshadri and M. Lease, “Square: A benchmark for research on computing crowd consensus,” in Proc. 1st AAAI Conf. Human Comput. Crowdsourcing, 2013, pp. 156–164.
|
| [116] |
J. Zhang, V. S. Sheng, B. A. Nicholson, and X. Wu, “CEKA: A tool for mining the wisdom of crowds,” J. Mach. Learn. Res., vol. 16, no. 1, pp. 2853–2858, 2015.
|
| [117] |
M. Hall, E. Frank, G. Holmes, B. Pfahringer, Reutemann, and I. H. Witten, “The WEKA data mining software: An update,” ACM SIGKDD Explorations Newsletter, vol. 11, no. 1, pp. 10–18, 2009. doi: 10.1145/1656274.1656278
|
| [118] |
M. Venanzi, O. Parson, A. Rogers, and N. Jennings, “The activecrowdtoolkit: An open-source tool for benchmarking active learning algorithms for crowdsourcing research,” in Proc. 3rd AAAI Conf. Human Comput. Crowdsourcing, 2015, pp. 44–45.
|
Figures(3) / Tables(2)






 DownLoad:
DownLoad: