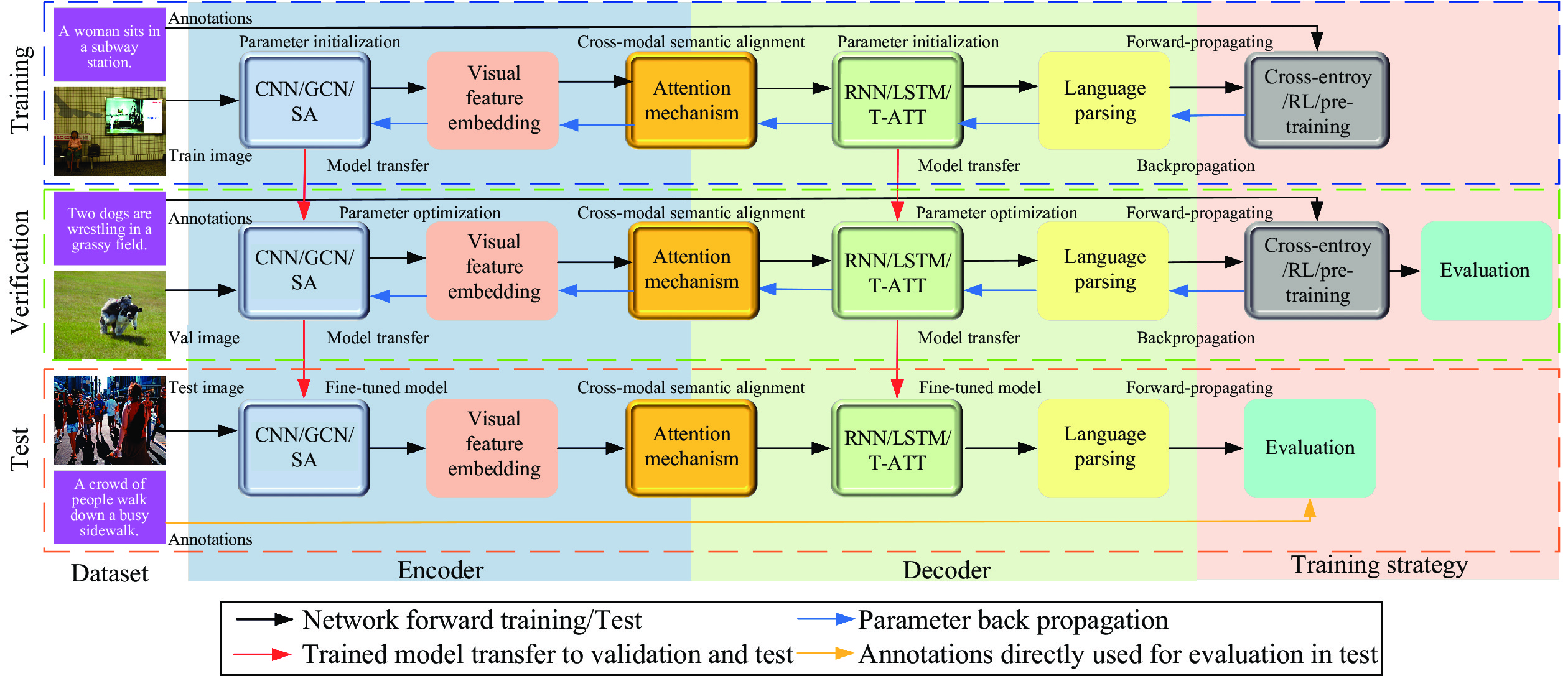
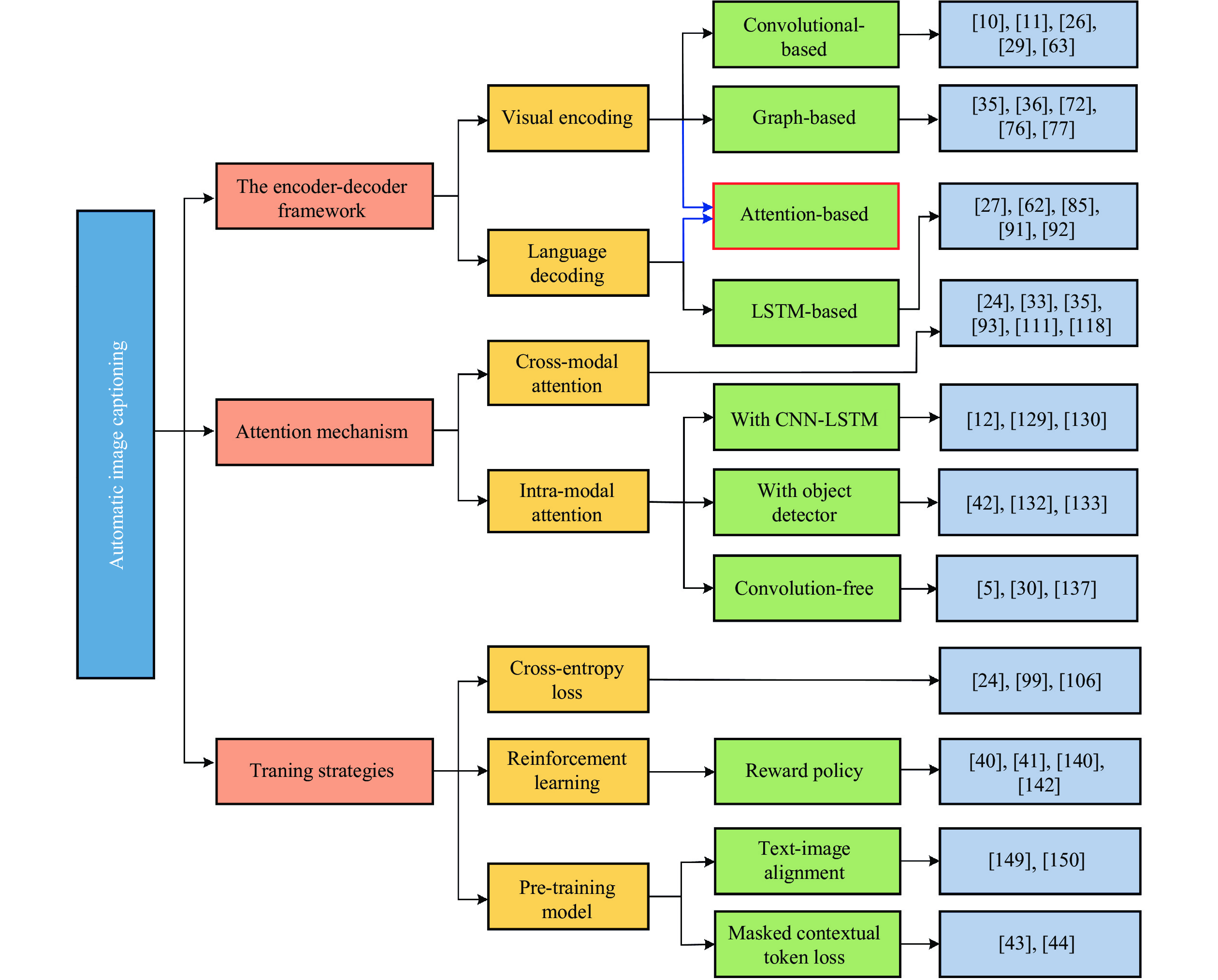
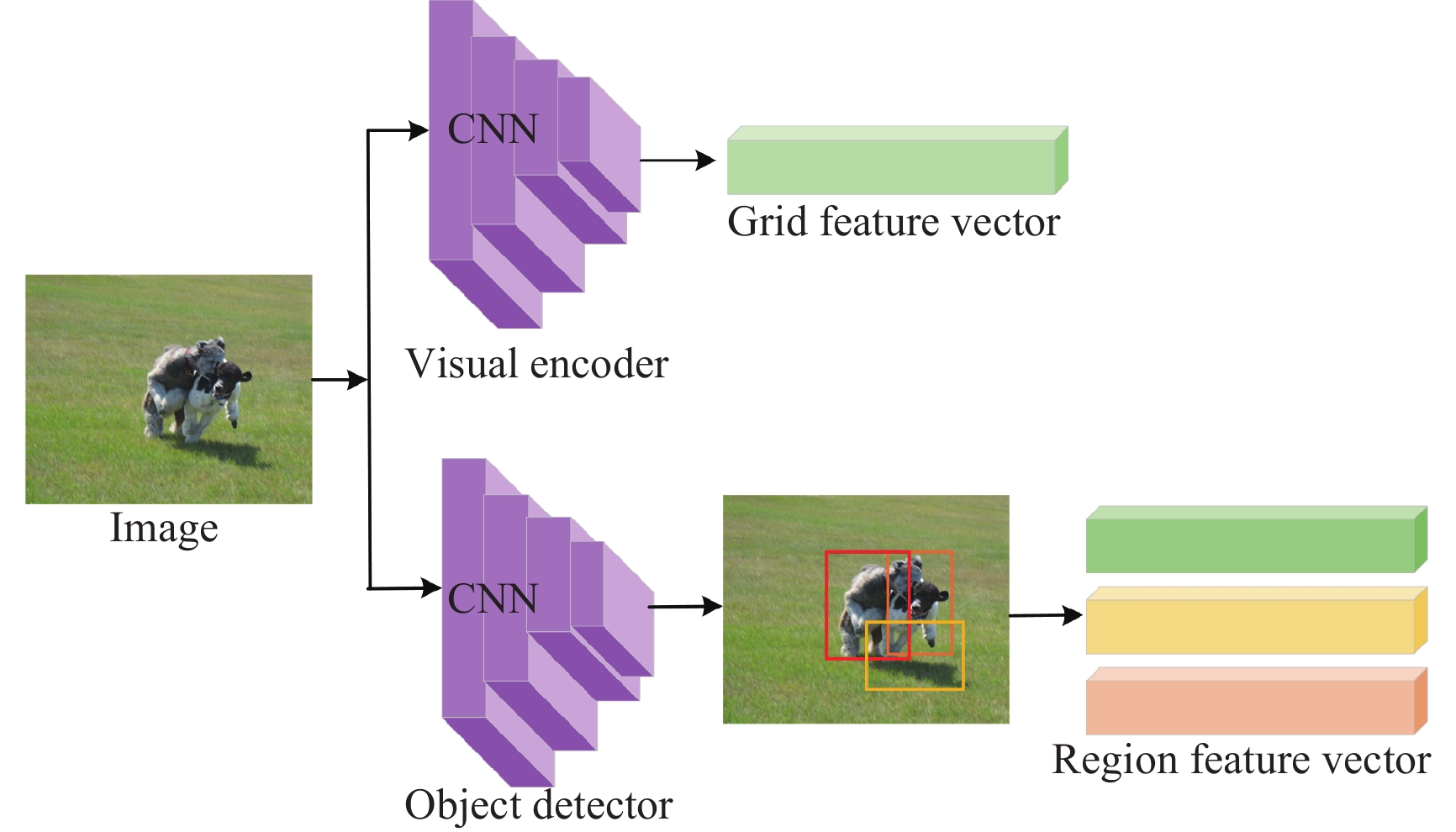
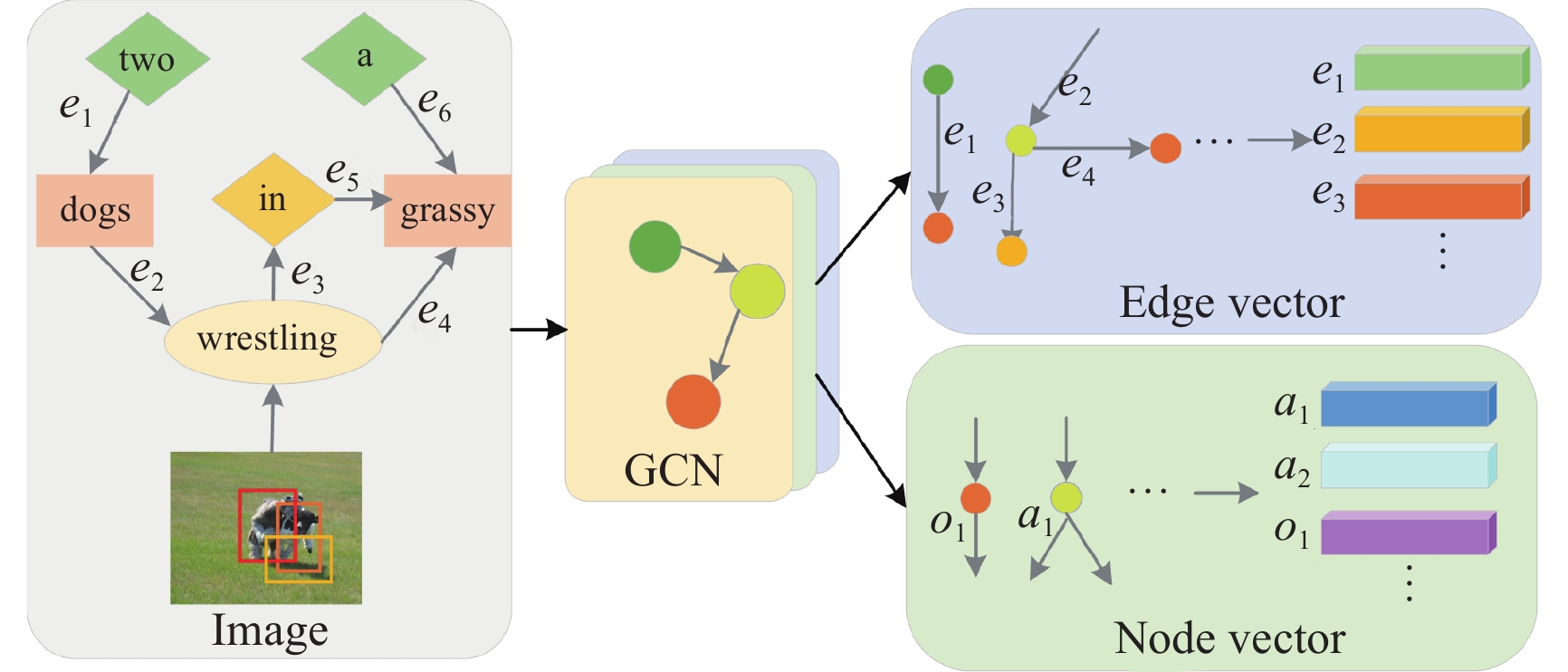
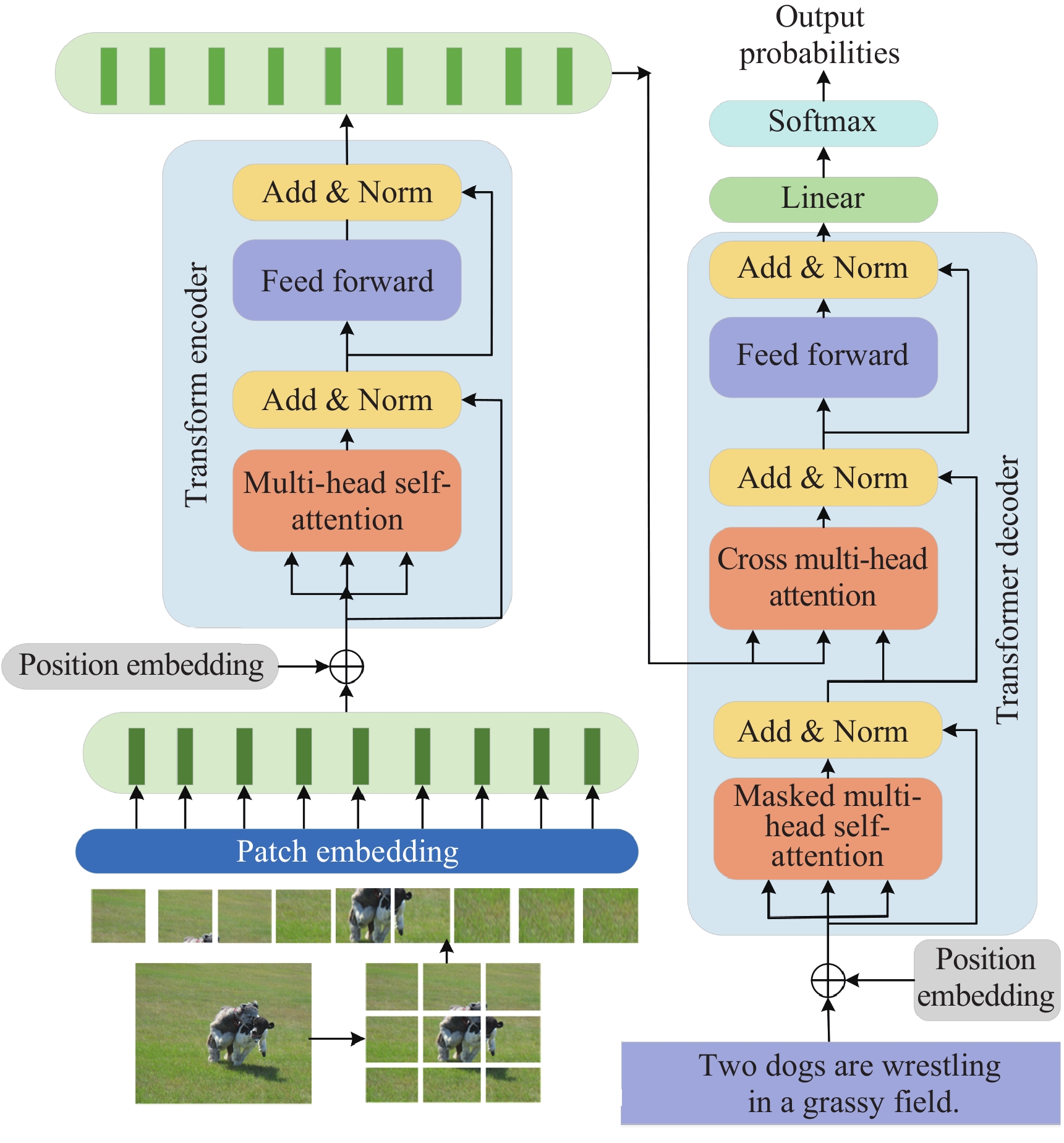
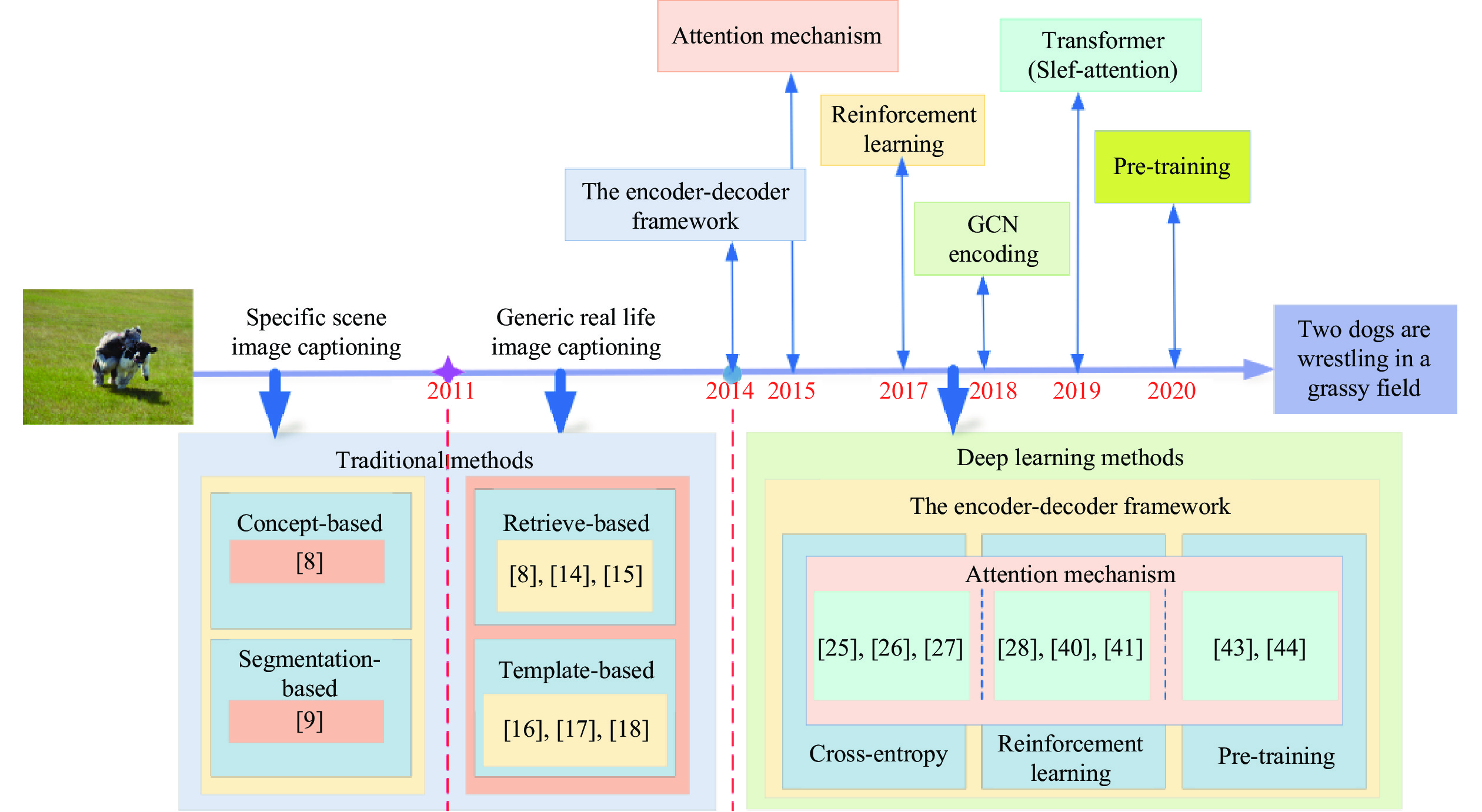
| [1] |
S. P. Manay, S. A. Yaligar, Y. Thathva Sri Sai Reddy, and N. J. Saunshimath, “Image captioning for the visually impaired,” in Proc. Emerging Research in Computing, Information, Communication and Applications, Springer, 2022, pp. 511−522.
|
| [2] |
R. Hinami, Y. Matsui, and S. Satoh, “Region-based image retrieval revisited,” in Proc. 25th ACM Int. Conf. Multimedia, 2017, pp. 528−536.
|
| [3] |
E. Hand and R. Chellappa, “Attributes for improved attributes: A multi-task network utilizing implicit and explicit relationships for facial attribute classification,” in Proc. AAAI Conf. Artificial Intelligence, 2017, vol. 31, no. 1, pp. 4068−4074.
|
| [4] |
X. Cheng, J. Lu, J. Feng, B. Yuan, and J. Zhou, “Scene recognition with objectness,” Pattern Recognition, vol. 74, pp. 474–487, 2018. doi: 10.1016/j.patcog.2017.09.025 |
| [5] |
Z. Meng, L. Yu, N. Zhang, T. L. Berg, B. Damavandi, V. Singh, and A. Bearman, “Connecting what to say with where to look by modeling human attention traces,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2021, pp. 12679−12688.
|
| [6] |
L. Liu, W. Ouyang, X. Wang, P. Fieguth, J. Chen, X. Liu, and M. Pietikäinen, “Deep learning for generic object detection: A survey,” Int. J. Computer Vision, vol. 128, no. 2, pp. 261–318, 2020. doi: 10.1007/s11263-019-01247-4 |
| [7] |
D. Gurari, Y. Zhao, M. Zhang, and N. Bhattacharya, “Captioning images taken by people who are blind,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 417−434.
|
| [8] |
A. Kojima, T. Tamura, and K. Fukunaga, “Natural language description of human activities from video images based on concept hierarchy of actions,” Int. J. Computer Vision, vol. 50, no. 2, pp. 171–184, 2002. doi: 10.1023/A:1020346032608 |
| [9] |
P. Hède, P.-A. Moëllic, J. Bourgeoys, M. Joint, and C. Thomas, “Automatic generation of natural language description for images.” in Proc. RIAO, Citeseer, 2004, pp. 306−313.
|
| [10] |
S. Li, G. Kulkarni, T. Berg, A. Berg, and Y. Choi, “Composing simple image descriptions using web-scale n-grams,” in Proc. 15th Conf. Computational Natural Language Learning, 2011, pp. 220−228.
|
| [11] |
S. P. Liu, Y. T. Xian, H. F. Li, and Z. T. Yu, “Text detection in natural scene images using morphological component analysis and Laplacian dictionary,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 1, pp. 214–222, Jan. 2020.
|
| [12] |
A. Tran, A. Mathews, and L. Xie, “Transform and tell: Entity-aware news image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 13035−13045.
|
| [13] |
P. Kuznetsova, V. Ordonez, T. L. Berg, and Y. Choi, “Treetalk: Composition and compression of trees for image descriptions,” Trans. Association for Computational Linguistics, vol. 2, pp. 351–362, 2014. doi: 10.1162/tacl_a_00188 |
| [14] |
M. Hodosh, P. Young, and J. Hockenmaier, “Framing image description as a ranking task: Data, models and evaluation metrics,” J. Artificial Intelligence Research, vol. 47, pp. 853–899, 2013. doi: 10.1613/jair.3994 |
| [15] |
G. Kulkarni, V. Premraj, V. Ordonez, S. Dhar, S. Li, Y. Choi, A. C. Berg, and T. L. Berg, “Babytalk: Understanding and generating simple image descriptions,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 35, no. 12, pp. 2891–2903, 2013. doi: 10.1109/TPAMI.2012.162 |
| [16] |
M. Mitchell, J. Dodge, A. Goyal, K. Yamaguchi, K. Stratos, X. Han, A. Mensch, A.-d. Berg, T. Berg, and H. Daumé III, “Midge: Generating image descriptions from computer vision detec-tions,” in Proc. 13th Conf. European Chapter Association for Computational Linguistics, 2012, pp. 747−756.
|
| [17] |
Y. Yang, C. Teo, H. Daumé III, and Y. Aloimonos, “Corpus-guided sentence generation of natural images,” in Proc. Conf. Empirical Methods in Natural Language Processing, 2011, pp. 444−454.
|
| [18] |
W. N. H. W. Mohamed, M. N. M. Salleh, and A.-d. H. Omar, “A comparative study of reduced error pruning method in decision tree algorithms,” in Proc. IEEE Int. Conf. Control System, Computing and Engineering, 2012, pp. 392−397.
|
| [19] |
W. Liu, Z. Wang, Y. Yuan, N. Zeng, K. Hone, and X. Liu, “A novel sigmoid-function-based adaptive weighted particle swarm optimizer,” IEEE Trans. Cybernetics, vol. 51, no. 2, pp. 1085–1093, 2019. doi: 10.1109/TCYB.2019.2925015 |
| [20] |
S. Harford, F. Karim, and H. Darabi, “Generating adversarial samples on multivariate time series using variational autoencoders,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 9, pp. 1523–1538, Sept. 2021.
|
| [21] |
M. S. Sarafraz and M. S. Tavazoei, “A unified optimization-based framework to adjust consensus convergence rate and optimize the network topology in uncertain multi-agent systems,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 9, pp. 1539–1539, Sept. 2021.
|
| [22] |
Y. R. Wang, S. C. Gao, M. C. Zhou, and Y. Yu, “A multi-layered gravitational search algorithm for function optimization and real-world problems,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 1, pp. 94–109, Jan. 2021.
|
| [23] |
K. H. Liu, Z. H. Ye, H. Y. Guo, D. P. Cao, L. Chen, and F.-Y. Wang, “FISS GAN: A generative adversarial network for foggy image semantic segmentation,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 8, pp. 1428–1439, Aug. 2021.
|
| [24] |
Y. Ming, X. Meng, C. Fan, and H. Yu, “Deep learning for monocular depth estimation: A review,” Neurocomputing, vol. 438, no. 28, pp. 14–33, 2021.
|
| [25] |
K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in Proc. Int. Conf. Machine Learning, 2015, pp. 2048−2057.
|
| [26] |
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: Lessons learned from the 2015 MS COCO image captioning challenge,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 39, no. 4, pp. 652–663, 2016.
|
| [27] |
J. Lu, C. Xiong, D. Parikh, and R. Socher, “Knowing when to look: Adaptive attention via a visual sentinel for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2017, pp. 375−383.
|
| [28] |
S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross, and V. Goel, “Self-critical sequence training for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2017, pp. 7008−7024.
|
| [29] |
P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang, “Bottom-up and top-down attention for image captioning and visual question answering,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2018, pp. 6077−6086.
|
| [30] |
W. Liu, S. Chen, L. Guo, X. Zhu, and J. Liu, “CPTR: Full transformer network for image captioning,” arXiv preprint arXiv: 2101.10804, 2021.
|
| [31] |
R. Kiros, R. Salakhutdinov, and R. Zemel, “Multimodal neural language models,” in Proc. Int. Conf. Machine Learning, 2014, pp. 595−603.
|
| [32] |
A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2015, pp. 3128−3137.
|
| [33] |
L. Wu, M. Xu, J. Wang, and S. Perry, “Recall what you see continually using grid LSTM in image captioning,” IEEE Trans. Multimedia, vol. 22, no. 3, pp. 808–818, 2019.
|
| [34] |
K. Lin, Z. Gan, and L. Wang, “Augmented partial mutual learning with frame masking for video captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2021, vol. 35, no. 3, pp. 2047−2055.
|
| [35] |
T. Yao, Y. Pan, Y. Li, and T. Mei, “Exploring visual relationship for image captioning,” in Proc. European Conf. Computer Vision, 2018, pp. 684−699.
|
| [36] |
L. Guo, J. Liu, J. Tang, J. Li, W. Luo, and H. Lu, “Aligning linguistic words and visual semantic units for image captioning,” in Proc. 27th ACM Int. Conf. Multimedia, 2019, pp. 765−773.
|
| [37] |
X. Yang, H. Zhang, and J. Cai, “Auto-encoding and distilling scene graphs for image captioning,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 44, no. 5, pp. 2313–2327, 2020. doi: 10.1109/TPAMI.2020.3042192 |
| [38] |
X. S. Li, Y. T. Liu, K. F. Wang, and F.-Y. Wang, “A recurrent attention and interaction model for pedestrian trajectory prediction,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 5, pp. 1361–1370, Sept. 2020.
|
| [39] |
P. Liu, Y. Zhou, D. Peng, and D. Wu, “Global-attention-based neural networks for vision language intelligence,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 7, pp. 1243–1252, 2020.
|
| [40] |
T. L. Zhou, M. Chen, and J. Zou, “Reinforcement learning based data fusion method for multi-sensors,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 6, pp. 1489–1497, Nov. 2020.
|
| [41] |
P. H. Seo, P. Sharma, T. Levinboim, B. Han, and R. Soricut, “Reinforcing an image caption generator using off-line human feedback,” in Proc. AAAI Conf. Artificial Intelligence, 2020, vol. 34, no. 3, pp. 2693−2700.
|
| [42] |
J. Yu, J. Li, Z. Yu, and Q. Huang, “Multimodal transformer with multi-view visual representation for image captioning,” IEEE Trans. Circuits and Systems for Video Technology, vol. 30, no. 12, pp. 4467–4480, 2020. doi: 10.1109/TCSVT.2019.2947482 |
| [43] |
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv: 1810.04805, 2018.
|
| [44] |
P. Zhang, X. Li, X. Hu, J. Yang, L. Zhang, L. Wang, Y. Choi, and J. Gao, “VINVL: Revisiting visual representations in vision-language models,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2021, pp. 5579−5588.
|
| [45] |
A. Farhadi, M. Hejrati, M. A. Sadeghi, P. Young, C. Rashtchian, J. Hockenmaier, and D. Forsyth, “Every picture tells a story: Generating sentences from images,” in Proc. European Conf. Computer Vision, Springer, 2010, pp. 15−29.
|
| [46] |
V. Ordonez, G. Kulkarni, and T. Berg, “Im2text: Describing images using 1 million captioned photographs,” Advances in Neural Information Processing Systems, vol. 24, pp. 1143–1151, 2011.
|
| [47] |
R. Socher, A. Karpathy, Q. V. Le, C. D. Manning, and A. Y. Ng, “Grounded compositional semantics for finding and describing images with sentences,” Trans. Association Computational Linguistics, vol. 2, pp. 207–218, 2014. doi: 10.1162/tacl_a_00177 |
| [48] |
R. Mason and E. Charniak, “Nonparametric method for data-driven image captioning,” in Proc. 52nd Annual Meeting Association for Computational Linguistics, 2014, vol. 2, pp. 592−598.
|
| [49] |
C. Sun, C. Gan, and R. Nevatia, “Automatic concept discovery from parallel text and visual corpora,” in Proc. IEEE Int. Conf. Computer Vision, 2015, pp. 2596−2604.
|
| [50] |
A. Gupta, Y. Verma, and C. Jawahar, “Choosing linguistics over vision to describe images,” in Proc. AAAI Conf. Artificial Intelligence, 2012, vol. 26, no. 1.
|
| [51] |
J. Devlin, S. Gupta, R. Girshick, M. Mitchell, and C. L. Zitnick, “Exploring nearest neighbor approaches for image captioning,” arXiv preprint arXiv: 1505.04467, 2015.
|
| [52] |
R. Xu, C. Xiong, W. Chen, and J. Corso, “Jointly modeling deep video and compositional text to bridge vision and language in a unified framework,” in Proc. AAAI Conf. Artificial Intelligence, 2015, vol. 29, no. 1.
|
| [53] |
R. Lebret, P. Pinheiro, and R. Collobert, “Phrase-based image captioning,” in Proc. Int. Conf. Machine Learning, 2015, pp. 2085−2094.
|
| [54] |
N. Krishnamoorthy, G. Malkarnenkar, R. Mooney, K. Saenko, and S. Guadarrama, “Generating natural-language video descriptions using text-mined knowledge,” in Proc. AAAI Conf. Artificial Intelligence, 2013, vol. 27, no. 1.
|
| [55] |
I. U. Rahman, Z. Wang, W. Liu, B. Ye, M. Zakarya, and X. Liu, “An n-state markovian jumping particle swarm optimization algorithm,” IEEE Trans. Systems, Man, and Cybernetics: Systems, vol. 51, no. 11, pp. 6626–6638, 2020. doi: 10.1109/TSMC.2019.2958550 |
| [56] |
Y. Ushiku, M. Yamaguchi, Y. Mukuta, and T. Harada, “Common subspace for model and similarity: Phrase learning for caption generation from images,” in Proc. IEEE Int. Conf. Computer Vision, 2015, pp. 2668−2676.
|
| [57] |
M. Muzahid, W. G. Wan, F. Sohel, L. Y. Wu, and L. Hou, “CurveNet: Curvature-based multitask learning deep networks for 3D object recognition,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 6, pp. 1177–1187, Jun. 2021.
|
| [58] |
Q. Wu, C. Shen, L. Liu, A. Dick, and A. Van Den Hengel, “What value do explicit high level concepts have in vision to language problems?” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2016, pp. 203−212.
|
| [59] |
J. Gu, S. Joty, J. Cai, and G. Wang, “Unpaired image captioning by language pivoting,” in Proc. European Conf. Computer Vision, 2018, pp. 503−519.
|
| [60] |
J. Gamper and N. Rajpoot, “Multiple instance captioning: Learning representations from histo-pathology textbooks and articles,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2021, pp. 16549−16559.
|
| [61] |
Y. Song, S. Chen, Y. Zhao, and Q. Jin, “Unpaired cross-lingual image caption generation with self-supervised rewards,” in Proc. 27th ACM Int. Conf. Multi-Media, 2019, pp. 784−792.
|
| [62] |
J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell, “Long-term recurrent convolutional networks for visual recognition and description,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2015, pp. 2625−2634.
|
| [63] |
X. Zhang, X. Sun, Y. Luo, J. Ji, Y. Zhou, Y. Wu, F. Huang, and R. Ji, “Rstnet: Captioning with adaptive attention on visual and non-visual words,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2021, pp. 15465−15474.
|
| [64] |
J. Mao, J. Huang, A. Toshev, O. Camburu, A. L. Yuille, and K. Murphy, “Generation and comprehension of unambiguous object descriptions,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2016, pp. 11−20.
|
| [65] |
H. Fang, S. Gupta, F. Iandola, R. K. Srivastava, L. Deng, P. Dollár, J. Gao, X.-D. He, M. Mitchell, J. C. Platt, C. L. Zitnick, and G. Zweig, “From captions to visual concepts and back,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2015, pp. 1473−1482.
|
| [66] |
P. Anderson, S. Gould, and M. Johnson, “Partially-supervised image captioning,” arXiv preprint arXiv: 1806.06004, 2018.
|
| [67] |
R. Girshick, “Fast R-CNN,” in Proc. IEEE Int. Conf. Computer Vision, 2015, pp. 1440−1448.
|
| [68] |
S. Datta, K. Sikka, A. Roy, K. Ahuja, D. Parikh, and A. Divakaran, “Align2Ground: Weakly supervised phrase grounding guided by image-caption alignment,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 2601−2610.
|
| [69] |
X. Chen, M. Zhang, Z. Wang, L. Zuo, B. Li, and Y. Yang, “Leveraging unpaired out-of-domain data for image captioning,” Pattern Recognition Letters, vol. 132, pp. 132–140, 2020. doi: 10.1016/j.patrec.2018.12.018 |
| [70] |
D.-J. Kim, T.-H. Oh, J. Choi, and I. S. Kweon, “Dense relational image captioning via multi-task triple-stream networks,” arXiv preprint arXiv: 2010.03855, 2020.
|
| [71] |
L.-C. Yang, C.-Y. Yang, and J. Y.-j. Hsu, “Object relation attention for image paragraph captioning,” in Proc. AAAI Conf. Artificial Intelligence, vol. 35, no. 4, 2021, pp. 3136−3144.
|
| [72] |
X. B. Hong, T. Zhang, Z. Cui, and J. Yang, “Variational gridded graph convolution network for node classification,” IEEE/CAA J. Autom.Sinica, vol. 8, no. 10, pp. 1697–1708, Oct. 2021.
|
| [73] |
X. Liu, M. Yan, L. Deng, G. Li, X. Ye, and D. Fan, “Sampling methods for efficient training of graph convolutional networks: A survey,” IEEE/CAA J. Autom. Sinica, vol. 2, no. 9, pp. 205–234, 2022.
|
| [74] |
X. Yang, K. Tang, H. Zhang, and J. Cai, “Auto-encoding scene graphs for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 10685−10694.
|
| [75] |
X. Yang, H. Zhang, and J. Cai, “Learning to collocate neural modules for image captioning,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 4250−4260.
|
| [76] |
J. Gu, S. Joty, J. Cai, H. Zhao, X. Yang, and G. Wang, “Unpaired image captioning via scene graph alignments,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 10323−10332.
|
| [77] |
R. Zellers, M. Yatskar, S. Thomson, and Y. Choi, “Neural motifs: Scene graph parsing with global context,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2018, pp. 5831−5840.
|
| [78] |
V. S. Chen, P. Varma, R. Krishna, M. Bernstein, C. Re, and L. Fei-Fei, “Scene graph prediction with limited labels,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 2580−2590.
|
| [79] |
Y. Zhong, L. Wang, J. Chen, D. Yu, and Y. Li, “Comprehensive image captioning via scene graph decomposition,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 211−229.
|
| [80] |
S. Chen, Q. Jin, P. Wang, and Q. Wu, “Say as you wish: Fine-grained control of image caption generation with abstract scene graphs,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 9962−9971.
|
| [81] |
W. Zhang, H. Shi, S. Tang, J. Xiao, Q. Yu, and Y. Zhuang, “Consensus graph representation learning for better grounded image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2021, pp.3394–3402.
|
| [82] |
S. Tripathi, K. Nguyen, T. Guha, B. Du, and T. Q. Nguyen, “Sg2caps: Revisiting scene graphs for image captioning,” arXiv preprint arXiv: 2102.04990, 2021.
|
| [83] |
D. Wang, D. Beck, and T. Cohn, “On the role of scene graphs in image captioning,” in Proc. Beyond Vision and Language: Integrating Real-World Knowledge, 2019, pp. 29−34.
|
| [84] |
V. S. J. Milewski, M. F. Moens, and I. Calixto, “Are scene graphs good enough to improve image captioning?” in Proc. 1st Conf. Asia-Pacific Chapter of Association for Computational Linguistics and 10th Int. Joint Conf. Natural Language Processing, 2020, pp. 504−515.
|
| [85] |
J. Mao, X. Wei, Y. Yang, J. Wang, Z. Huang, and A. L. Yuille, “Learning like a child: Fast novel visual concept learning from sentence descriptions of images,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2015, pp. 2533−2541.
|
| [86] |
L. Wang, A. G. Schwing, and S. Lazebnik, “Diverse and accurate image description using a variational auto-encoder with an additive gaussian encoding space,” arXiv preprint arXiv: 1711.07068, 2017.
|
| [87] |
M. Wang, L. Song, X. Yang, and C. Luo, “A parallel-fusion RNN-LSTM architecture for image caption generation,” in IEEE Int. Conf. Image Processing, IEEE, 2016, pp. 4448−4452.
|
| [88] |
W. Jiang, L. Ma, X. Chen, H. Zhang, and W. Liu, “Learning to guide decoding for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2018, pp. 6959−6966.
|
| [89] |
Y. Xian and Y. Tian, “Self-guiding multimodal LSTM—When we do not have a perfect training dataset for image captioning?” IEEE Trans. Image Processing, vol. 28, no. 11, pp. 5241–5252, 2019. doi: 10.1109/TIP.2019.2917229 |
| [90] |
X. Jia, E. Gavves, B. Fernando, and T. Tuytelaars, “Guiding the long-short term memory model for image caption generation,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2015, pp. 2407−2415.
|
| [91] |
J. Mao, W. Xu, Y. Yang, J. Wang, Z. Huang, and A. Yuille, “Deep captioning with multimodal recurrent neural networks (m-RNN),” arXiv preprint arXiv: 1412.6632, 2014.
|
| [92] |
C. Wang, H. Yang, C. Bartz, and C. Meinel, “Image captioning with deep bidirectional LSTMs,” in Proc. 24th ACM International Conf. Multimedia, 2016, pp. 988−997.
|
| [93] |
Y. Zheng, Y. Li, and S. Wang, “Intention oriented image captions with guiding objects,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 8395−8404.
|
| [94] |
I. Laina, C. Rupprecht, and N. Navab, “Towards unsupervised image captioning with shared multimodal embeddings,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 7414−7424.
|
| [95] |
W. J. Zhang, J. C. Wang, and F. P. Lan, “Dynamic hand gesture recognition based on short-term sampling neural networks,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 1, pp. 110–120, Jan. 2021.
|
| [96] |
L. Liu, J. Tang, X. Wan, and Z. Guo, “Generating diverse and descriptive image captions using visual paraphrases,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 4240−4249.
|
| [97] |
G. Yin, L. Sheng, B. Liu, N. Yu, X. Wang, and J. Shao, “Context and attribute grounded dense captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 6241−6250.
|
| [98] |
J. Gu, J. Cai, G. Wang, and T. Chen, “Stack-captioning: Coarse-to-fine learning for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2018, vol. 32, no. 1, pp. 6837–6844.
|
| [99] |
D.-J. Kim, J. Choi, T.-H. Oh, and I. S. Kweon, “Dense relational captioning: Triple-stream networks for relationship-based captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 6271−6280.
|
| [100] |
Z. Song, X. Zhou, Z. Mao, and J. Tan, “Image captioning with context-aware auxiliary guidance,” in Proc. AAAI Conf. Artificial Intelligence, 2021, vol. 35, no. 3, pp. 2584−2592.
|
| [101] |
X. D. Zhao, Y. R. Chen, J. Guo, and D. B. Zhao, “A spatial-temporal attention model for human trajectory prediction,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 4, pp. 965–974, Jul. 2020.
|
| [102] |
L. Li, S. Tang, L. Deng, Y. Zhang, and Q. Tian, “Image caption with global-local attention,” in Proc. AAAI Conf. Artificial Intelligence, 2017, vol. 31, no. 1, pp. 4133−4239.
|
| [103] |
C. Wu, Y. Wei, X. Chu, F. Su, and L. Wang, “Modeling visual and word-conditional semantic attention for image captioning,” Signal Processing: Image Communication, vol. 67, pp. 100–107, 2018. doi: 10.1016/j.image.2018.06.002 |
| [104] |
Z. Zhang, Q. Wu, Y. Wang, and F. Chen, “Fine-grained and semantic-guided visual attention for image captioning,” in Proc. IEEE Winter Conf. Applications of Computer Vision, IEEE, 2018, pp. 1709−1717.
|
| [105] |
P. Cao, Z. Yang, L. Sun, Y. Liang, M. Q. Yang, and R. Guan, “Image captioning with bidirectional semantic attention-based guiding of long short-term memory,” Neural Processing Letters, vol. 50, no. 1, pp. 103–119, 2019. doi: 10.1007/s11063-018-09973-5 |
| [106] |
S. Wang, L. Lan, X. Zhang, G. Dong, and Z. Luo, “Object-aware semantics of attention for image captioning,” Multimedia Tools and Applications, vol. 79, no. 3, pp. 2013–2030, 2020.
|
| [107] |
L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao, W. Liu, and T.-S. Chua, “SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2017, pp. 5659−5667.
|
| [108] |
J. Zhou, X. Wang, J. Han, S. Hu, and H. Gao, “Spatial-temporal attention for image captioning,” in Proc. IEEE Fourth Int. Conf. Multimedia Big Data, 2018, pp. 1−5.
|
| [109] |
J. Ji, C. Xu, X. Zhang, B. Wang, and X. Song, “Spatio-temporal memory attention for image captioning,” IEEE Trans. Image Processing, vol. 29, pp. 7615–7628, 2020. doi: 10.1109/TIP.2020.3004729 |
| [110] |
J. Lu, J. Yang, D. Batra, and D. Parikh, “Neural baby talk,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2018, pp. 7219−7228.
|
| [111] |
F. Xiao, X. Gong, Y. Zhang, Y. Shen, J. Li, and X. Gao, “DAA: Dual LSTMs with adaptive attention for image captioning,” Neurocomputing, vol. 364, pp. 322–329, 2019. doi: 10.1016/j.neucom.2019.06.085 |
| [112] |
Z. Deng, Z. Jiang, R. Lan, W. Huang, and X. Luo, “Image captioning using DenseNet network and adaptive attention,” Signal Processing: Image Communication, vol. 85, p. 115836, 2020.
|
| [113] |
C. Yan, Y. Hao, L. Li, J. Yin, A. Liu, Z. Mao, Z. Chen, and X. Gao, “Task-adaptive attention for image captioning,” IEEE Trans. Circuits and Systems for Video Technology, vol. 32, no. 1, pp. 43–51, 2021. doi: 10.1109/TCSVT.2021.3067449 |
| [114] |
M. Cornia, L. Baraldi, G. Serra, and R. Cucchiara, “Paying more attention to saliency: Image captioning with saliency and context attention,” ACM Trans. Multimedia Computing,Communications,and Applications, vol. 14, no. 2, pp. 1–21, 2018.
|
| [115] |
J. Wang, W. Wang, L. Wang, Z. Wang, D. D. Feng, and T. Tan, “Learning visual relationship and context-aware attention for image captioning,” Pattern Recognition, vol. 98, p. 107075, 2020.
|
| [116] |
H. Chen, G. Ding, Z. Lin, Y. Guo, and J. Han, “Attend to knowledge: Memory-enhanced attention network for image captioning,” in Proc. Int. Conf. Brain Inspired Cognitive Systems, Springer, 2018, pp. 161−171.
|
| [117] |
T. Wang, X. Xu, F. Shen, and Y. Yang, “A cognitive memory-augmented network for visual anomaly detection,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 7, pp. 1296–1307, Jul. 2021.
|
| [118] |
C. Xu, M. Yang, X. Ao, Y. Shen, R. Xu, and J. Tian, “Retrieval-enhanced adversarial training with dynamic memory-augmented attention for image paragraph captioning,” Knowledge-Based Systems, vol. 214, p. 106730, 2021.
|
| [119] |
Y. Cheng, F. Huang, L. Zhou, C. Jin, Y. Zhang, and T. Zhang, “A hierarchical multimodal attention-based neural network for image captioning,” in Proc. 40th Int. ACM SIGIR Conf. Research and Development in Information Retrieval, 2017, pp. 889−892.
|
| [120] |
Q. Wang and A. B. Chan, “Gated hierarchical attention for image captioning,” in Proc. Asian Conf. Computer Vision, Springer, 2018, pp. 21−37.
|
| [121] |
W. Wang, Z. Chen, and H. Hu, “Hierarchical attention network for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2019, vol. 33, no. 1, pp. 8957−8964.
|
| [122] |
S. Yan, Y. Xie, F. Wu, J. S. Smith, W. Lu, and B. Zhang, “Image captioning via hierarchical attention mechanism and policy gradient optimization,” Signal Processing, vol. 167, p. 107329, 2020.
|
| [123] |
L. Gao, K. Fan, J. Song, X. Liu, X. Xu, and H. T. Shen, “Deliberate attention networks for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2019, vol. 33, no. 1, pp. 8320−8327.
|
| [124] |
Z. Zhang, Y. Wang, Q. Wu, and F. Chen, “Visual relationship attention for image captioning,” in Proc. IEEE Int. Joint Conf. Neural Networks, 2019, pp. 1−8.
|
| [125] |
Z. Zhang, Q. Wu, Y. Wang, and F. Chen, “Exploring region relationships implicitly: Image captioning with visual relationship attention,” Image and Vision Computing, vol. 109, p. 104146, 2021.
|
| [126] |
R. Del Chiaro, B. Twardowski, A. D. Bagdanov, and J. Van de Weijer, “Ratt: Recurrent attention to transient tasks for continual image captioning,” arXiv preprint arXiv: 2007.06271, 2020.
|
| [127] |
Y. Li, X. Zhang, J. Gu, C. Li, X. Wang, X. Tang, and L. Jiao, “Recurrent attention and semantic gate for remote sensing image captioning,” IEEE Trans. Geoscience and Remote Sensing, vol.60, p. 5608816, 2021.
|
| [128] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. Advances in Neural Information Processing Systems, 2017, pp. 5998−6008.
|
| [129] |
Y. Pan, T. Yao, Y. Li, and T. Mei, “X-linear attention networks for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 10971−10980.
|
| [130] |
J. Banzi, I. Bulugu, and Z. F. Ye, “Learning a deep predictive coding network for a semi-supervised 3D-hand pose estimation,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 5, pp. 1371–1379, Sept. 2020.
|
| [131] |
X. Zhu, L. Li, J. Liu, H. Peng, and X. Niu, “Captioning transformer with stacked attention modules,” Applied Sciences, vol. 8, no. 5, p. 739, 2018.
|
| [132] |
S. Herdade, A. Kappeler, K. Boakye, and J. Soares, “Image captioning: Transforming objects into words,” in Proc. Advances in Neural Information Processing Systems, 2019, pp. 11137−11147.
|
| [133] |
L. Guo, J. Liu, X. Zhu, P. Yao, S. Lu, and H. Lu, “Normalized and geometry-aware self-attention network for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 10327−10336.
|
| [134] |
G. Li, L. Zhu, P. Liu, and Y. Yang, “Entangled transformer for image captioning,” in Proc. IEEE Int. Conf. Computer Vision, 2019, pp. 8928−8937.
|
| [135] |
M. Cornia, M. Stefanini, L. Baraldi, and R. Cucchiara, “Meshed-memory transformer for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 10578−10587.
|
| [136] |
Y. Luo, J. Ji, X. Sun, L. Cao, Y. Wu, F. Huang, C. Lin, and R. Ji, “Dual-level collaborative transformer for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2021, pp. 1−8.
|
| [137] |
C. Sundaramoorthy, L. Z. Kelvin, M. Sarin, and S. Gupta, “End-to-end attention-based image captioning,” arXiv preprint arXiv: 2104.14721, 2021.
|
| [138] |
N. Zeng, H. Li, Z. Wang, W. Liu, S. Liu, F. E. Alsaadi, and X. Liu, “Deep-reinforcement-learning-based images segmentation for quantitative analysis of gold immunochromatographic strip,” Neurocomputing, vol. 425, pp. 173–180, 2021. doi: 10.1016/j.neucom.2020.04.001 |
| [139] |
J. Ji, X. Sun, Y. Zhou, R. Ji, F. Chen, J. Liu, and Q. Tian, “Attacking image captioning towards accuracy-preserving target words removal,” in Proc. 28th ACM Int. Conf. Multimedia, 2020, pp. 4226−4234.
|
| [140] |
T. Liu, B. Tian, Y. F. Ai, and F.-Y. Wang, “Parallel reinforcement learning-based energy efficiency improvement for a cyber-physical system,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 2, pp. 617–626, Mar. 2020.
|
| [141] |
M. Ranzato, S. Chopra, M. Auli, and W. Zaremba, “Sequence level training with recurrent neural networks,” arXiv preprint arXiv: 1511.06732, 2015.
|
| [142] |
R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2015, pp. 4566−4575.
|
| [143] |
P. Anderson, B. Fernando, M. Johnson, and S. Gould, “Spice: Semantic propositional image caption evaluation,” in Proc. European Conf. Computer Vision, Springer, 2016, pp. 382−398.
|
| [144] |
S. Liu, Z. Zhu, N. Ye, S. Guadarrama, and K. Murphy, “Improved image captioning via policy gradient optimization of spider,” in Proc. IEEE Int. Conf. Computer Vision, 2017, pp. 873−881.
|
| [145] |
L. Zhang, F. Sung, L. Feng, T. Xiang, S. Gong, Y. Yang, and T. Hospedales, “Actor-critic sequence training for image captioning,” in Visually-Grounded Interaction and Language: NIPS 2017 Workshop, 2017, pp.1–10.
|
| [146] |
Y. Lin, J. McPhee, and N. L. Azad, “Comparison of deep reinforcement learning and model predictive control for adaptive cruise control,” IEEE Trans. Intelligent Vehicles, vol. 6, no. 2, pp. 221–231, Jun. 2021. doi: 10.1109/TIV.2020.3012947 |
| [147] |
C. Chen, S. Mu, W. Xiao, Z. Ye, L. Wu, and Q. Ju, “Improving image captioning with conditional generative adversarial nets,” in Proc. AAAI Conf. Artificial Intelligence, 2019, vol. 33, no. 1, pp. 8142−8150.
|
| [148] |
X. Shi, X. Yang, J. Gu, S. Joty, and J. Cai, “Finding it at another side: A viewpoint-adapted matching encoder for change captioning,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 574−590.
|
| [149] |
L. Zhou, H. Palangi, L. Zhang, H. Hu, J. Corso, and J. Gao, “Unified vision-language pre-training for image captioning and VQA,” in Proc. AAAI Conf. Artificial Intelligence, 2020, vol. 34, no. 7, pp. 13041−13049.
|
| [150] |
X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei, et al., “Oscar: Object-semantics aligned pre-training for vision-language tasks,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 121−137.
|
| [151] |
X. Hu, X. Yin, K. Lin, L. Zhang, J. Gao, L. Wang, and Z. Liu, “Vivo: Visual vocabulary pre-training for novel object captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2021, vol. 35, no. 2, pp. 1575−1583.
|
| [152] |
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: Common objects in context,” in Proc. European Conf. Computer Vision, Springer, 2014, pp. 740−755.
|
| [153] |
P. Young, A. Lai, M. Hodosh, and J. Hockenmaier, “From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions,” Trans. Association Computational Linguistics, vol. 2, pp. 67–78, 2014. doi: 10.1162/tacl_a_00166 |
| [154] |
B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier, and S. Lazebnik, “Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,” in Proc. IEEE Int. Conf. Computer Vision, 2015, pp. 2641−2649.
|
| [155] |
M. Everingham, A. Zisserman, C. K. Williams, et al., “The 2005 pascal visual object classes challenge,” in Proc. Machine Learning Challenges Workshop, Springer, 2005, pp. 117−176.
|
| [156] |
B. Thomee, D. A. Shamma, G. Friedland, B. Elizalde, K. Ni, D. Poland, D. Borth, and L.-J. Li, “YFCC100m: The new data in multimedia research,” Commun. ACM, vol. 59, no. 2, pp. 64–73, 2016. doi: 10.1145/2812802 |
| [157] |
D. Elliott, S. Frank, K. Sima’an, and L. Specia, “Multi30k: Multilingual english-german image descriptions,” in Proc. 5th Workshop on Vision and Language, 2016, pp. 70−74.
|
| [158] |
J. Wu, H. Zheng, B. Zhao, Y. Li, B. Yan, R. Liang, W. Wang, S. Zhou, G. Lin, Y. Fu, Y. Z. Wang, and Y. G. Wang, “AI challenger: A large-scale dataset for going deeper in image understanding,” arXiv preprint arXiv: 1711.06475, 2017.
|
| [159] |
M. Grubinger, P. Clough, H. Müller, and T. Deselaers, “The iapr TC-12 benchmark: A new evaluation resource for visual information systems,” in Proc. Int. Workshop OntoImage, 2006, vol. 2, pp.13–23.
|
| [160] |
A. F. Biten, L. Gomez, M. Rusinol, and D. Karatzas, “Good news, everyone! Context driven entity-aware captioning for news images,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 12466−12475.
|
| [161] |
H. Agrawal, K. Desai, Y. Wang, X. Chen, R. Jain, M. Johnson, D. Batra, D. Parikh, S. Lee, and P. Anderson, “NOCAPS: Novel object captioning at scale,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 8948−8957.
|
| [162] |
X. Yang, H. Zhang, D. Jin, Y. Liu, C.-H. Wu, J. Tan, D. Xie, J. Wang, and X. Wang, “Fashion captioning: Towards generating accurate descriptions with semantic rewards,” in Proc. Computer Vision-ECCV, Springer, 2020, pp. 1−17.
|
| [163] |
O. Sidorov, R. Hu, M. Rohrbach, and A. Singh, “Textcaps: A dataset for image captioning with reading comprehension,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 742−758.
|
| [164] |
R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, L.-J. Li, D. A. Shamma, S. B. Michael, and F.-F. Li, “Visual genome: Connecting language and vision using crowdsourced dense image annotations,” Int. J. Computer Vision, vol. 123, no. 1, pp. 32–73, 2017. doi: 10.1007/s11263-016-0981-7 |
| [165] |
I. Krasin, T. Duerig, N. Alldrin, V. Ferrari, S. Abu-El-Haija, A. Kuznetsova, H. Rom, J. Uijlings, S. Popov, A. Veit, S. Abu-El-Haija, S. Belongie, C. University, D. Cai, Z. Y. Feng, V. Ferrari, and V. Gomes, “Openimages: A public dataset for large-scale multi-label and multi-class image classification,” Dataset available from https://github.com/openimages, vol. 2, no. 3, p. 18, 2017. |
| [166] |
K. Papineni, S. Roukos, T. Ward, and W. Zhu, “BLEU: A method for automatic evaluation of machine translation,” in Proc. 40th Annual Meeting Association for Computational Linguistics, 2002, pp. 311−318.
|
| [167] |
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,” in Proc. ACL Workshop Intrinsic and Extrinsic Evaluation Measures for Machine Trans. and/or Summarization, 2005, vol. 29, pp. 65−72.
|
| [168] |
C. Lin and F. J. Och, “Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics,” in Proc. 42nd Annual Meeting of Association for Computational Linguistics, 2004, pp. 605−612.
|
| [169] |
A. Deshpande, J. Aneja, L. Wang, A. G. Schwing, and D. Forsyth, “Fast, diverse and accurate image captioning guided by part-of-speech,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 10695−10704.
|
| [170] |
J. Aneja, H. Agrawal, D. Batra, and A. Schwing, “Sequential latent spaces for modeling the intention during diverse image captioning,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 4261−4270.
|
| [171] |
Q. Wang and A. B. Chan, “Describing like humans: On diversity in image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 4195−4203.
|
| [172] |
Q. Wang, J. Wan, and A. B. Chan, “On diversity in image captioning: Metrics and methods,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 44, no. 2, pp. 1035–1049, 2020. doi: 10.1109/TPAMI.2020.3013834 |
| [173] |
M. Jiang, Q. Huang, L. Zhang, X. Wang, P. Zhang, Z. Gan, J. Diesner, and J. Gao, “Tiger: Text-to-image grounding for image caption evaluation,” in Proc. Conf. Empirical Methods in Natural Language Processing and 9th Int. Joint Conf. Natural Language Processing, 2020, pp. 2141−2152.
|
| [174] |
S. Wang, Z. Yao, R. Wang, Z. Wu, and X. Chen, “Faier: Fidelity and adequacy ensured image caption evaluation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2021, pp. 14050−14059.
|
| [175] |
T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi, “Bertscore: Evaluating text generation with bert,” in Proc. Int. Conf. Learning Representations, 2019, pp. 1−43.
|
| [176] |
H. Lee, S. Yoon, F. Dernoncourt, D. S. Kim, T. Bui, and K. Jung, “Vilbertscore: Evaluating image caption using vision-and-language bert,” in Proc. 1st Workshop Evaluation and Comparison NLP Systems, 2020, pp. 34−39.
|
| [177] |
J. Wang, W. Xu, Q. Wang, and A. B. Chan, “Compare and reweight: Distinctive image captioning using similar images sets,” in Proc. European Conf. Computer Vision, Springer, 2020, pp. 370−386.
|
| [178] |
J. Hessel, A. Holtzman, M. Forbes, R. L. Bras, and Y. Choi, “Clipscore: A reference-free evaluation metric for image captioning,” arXiv preprint arXiv: 2104.08718, 2021.
|
| [179] |
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” Image, vol. 2, p. T2, 2021.
|
| [180] |
J. Feinglass and Y. Yang, “Smurf: Semantic and linguistic understanding fusion for caption evaluation via typicality analysis,” arXiv preprint arXiv: 2106.01444, 2021.
|
| [181] |
H. Lee, S. Yoon, F. Dernoncourt, T. Bui, and K. Jung, “Umic: An unreferenced metric for image captioning via contrastive learning,” in Proc. 59th Annual Meeting of the Association for Computational Linguistics and 11th Int. Joint Conf. Natural Language Processing, 2021, pp. 220−226.
|
| [182] |
J. Mao, W. Xu, Y. Yang, J. Wang, and A. L. Yuille, “Explain images with multimodal recurrent neural networks,” arXiv preprint arXiv: 1410.1090, 2014.
|
| [183] |
A. Karpathy, A. Joulin, and L. Fei-Fei, “Deep fragment embeddings for bidirectional image sentence mapping,” in Proc. 27th Int. Conf. Neural Information Processing Systems, 2014, vol. 2, pp. 1889−1897.
|
| [184] |
X. Chen and C. L. Zitnick, “Mind’s eye: A recurrent visual representation for image caption generation,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2015, pp. 2422−2431.
|
| [185] |
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2015, pp. 3156−3164.
|
| [186] |
K. Tran, X. He, L. Zhang, J. Sun, C. Carapcea, C. Thrasher, C. Buehler, and C. Sienkiewicz, “Rich image captioning in the wild,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2016, pp. 49−56.
|
| [187] |
L. A. Hendricks, S. Venugopalan, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell, “Deep compositional captioning: Describing novel object categories without paired training data,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2016, pp. 1−10.
|
| [188] |
L. Yang, K. Tang, J. Yang, and L.-J. Li, “Dense captioning with joint inference and visual context,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2017, pp. 2193−2202.
|
| [189] |
J. Gu, G. Wang, J. Cai, and T. Chen, “An empirical study of language cnn for image captioning,” in Proc. IEEE Int. Conf. Computer Vision, 2017, pp. 1222−1231.
|
| [190] |
Q. Wu, C. Shen, P. Wang, A. Dick, and A. van den Hengel, “Image captioning and visual question answering based on attributes and external knowledge,” IEEE Trans. Pattern Analysis &Machine Intelligence, vol. 40, no. 6, pp. 1367–1381, 2018.
|
| [191] |
J. Aneja, A. Deshpande, and A. G. Schwing, “Convolutional image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2018, pp. 5561−5570.
|
| [192] |
Q. Wang and A. B. Chan, “CNN + CNN: Convolutional decoders for image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2018, pp. 1−9.
|
| [193] |
X. Xiao, L. Wang, K. Ding, S. Xiang, and C. Pan, “Deep hierarchical encoder-decoder network for image captioning,” IEEE Trans. Multimedia, vol. 21, no. 11, pp. 2942–2956, 2019. doi: 10.1109/TMM.2019.2915033 |
| [194] |
Y. Qin, J. Du, Y. Zhang, and H. Lu, “Look back and predict forward in image captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 8367−8375.
|
| [195] |
J. Liu, K. Wang, C. Xu, Z. Zhao, R. Xu, Y. Shen, and M. Yang, “Interactive dual generative adversarial networks for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2020, vol. 34, no. 7, pp. 11588−11595.
|
| [196] |
Y. Wang, W. Zhang, Q. Liu, Z. Zhang, X. Gao, and X. Sun, “Improving intra-and inter-modality visual relation for image captioning,” in Proc. 28th ACM Int. Conf. Multimedia, 2020, pp. 4190−4198.
|
| [197] |
A. Hu, S. Chen, and Q. Jin, “ICECAP: Information concentrated entity-aware image captioning,” in Proc. 28th ACM Int. Conf. Multimedia, 2020, pp. 4217−4225.
|
| [198] |
Z. Fei, “Memory-augmented image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2021, vol. 35, no. 2, pp. 1317−1324.
|
| [199] |
Y. Zhang, X. Shi, S. Mi, and X. Yang, “Image captioning with transformer and knowledge graph,” Pattern Recognition Letters, vol. 143, pp. 43–49, 2021. doi: 10.1016/j.patrec.2020.12.020 |
| [200] |
Y. Luo, J. Ji, X. Sun, L. Cao, Y. Wu, F. Huang, C.-W. Lin, and R. Ji, “Dual-level collaborative transformer for image captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2021, vol. 35, no. 3, pp. 2286−2293.
|
| [201] |
Z. Shi, X. Zhou, X. Qiu, and X. Zhu, “Improving image captioning with better use of caption,” in Proc. 58th Annual Meeting Association for Computational Linguistics, 2020, pp. 7454−7464.
|
| [202] |
L. Huang, W. Wang, J. Chen, and X. Wei, “Attention on attention for image captioning,” in Proc. IEEE Int. Conf. Computer Vision, 2019, pp. 4634−4643.
|
| [203] |
D. Liu, Z.-J. Zha, H. Zhang, Y. Zhang, and F. Wu, “Context-aware visual policy network for sequence-level image captioning,” in Proc. 26th ACM Int. Conf. Multimedia, 2018, pp. 1416−1424.
|
| [204] |
W. Jiang, L. Ma, Y.-G. Jiang, W. Liu, and T. Zhang, “Recurrent fusion network for image captioning,” in Proc. European Conf. Computer Vision, Springer, 2018, pp. 499−515.
|
| [205] |
T. Yao, Y. Pan, Y. Li, Z. Qiu, and T. Mei, “Boosting image captioning with attributes,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2017, pp. 4894−4902.
|
| [206] |
T. Yao, Y. Pan, Y. Li, and T. Mei, “Hierarchy parsing for image captioning,” in Proc. IEEE/CVF Int. Conf. Computer Vision, 2019, pp. 2621−2629.
|
| [207] |
Y. Zhou, M. Wang, D. Liu, Z. Hu, and H. Zhang, “More grounded image captioning by distilling image-text matching model,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 4777−4786.
|
| [208] |
L. Wang, Z. Bai, Y. Zhang, and H. Lu, “Show, recall, and tell: Image captioning with recall mechanism.” in Proc. AAAI Conf. Artificial Intelligence, 2020, pp. 12176−12183.
|
| [209] |
J. Ji, Y. Luo, X. Sun, F. Chen, G. Luo, Y. Wu, Y. Gao, and R. Ji, “Improving image captioning by leveraging intra-and inter-layer global representation in transformer network,” in Proc. AAAI Conf. Artificial Intelligence, 2021, vol. 35, no. 2, pp. 1655−1663.
|
| [210] |
M. Cornia, L. Baraldi, and R. Cucchiara, “Show, control and tell: A framework for generating controllable and grounded captions,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 8307−8316.
|
| [211] |
C. Deng, N. Ding, M. Tan, and Q. Wu, “Length-controllable image captioning,” in Computer Vision-ECCV, Springer, 2020, pp. 712−729.
|
| [212] |
F. Sammani and L. Melas-Kyriazi, “Show, edit and tell: A framework for editing image captions,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2020, pp. 4808−4816.
|
| [213] |
X. Li, S. Jiang, and J. Han, “Learning object context for dense captioning,” in Proc. AAAI Conf. Artificial Intelligence, 2019, pp. 8650−8657.
|
| [214] |
S. Chen and Y.-G. Jiang, “Towards bridging event captioner and sentence localizer for weakly supervised dense event captioning,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2021, pp. 8425−8435.
|
| [215] |
K. Shuster, S. Humeau, H. Hu, A. Bordes, and J. Weston, “Engaging image captioning via personality,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, pp. 12516−12526.
|
| [216] |
R. Li, H. Liang, Y. Shi, F. Feng, and X. Wang, “Dual-CNN: A convolutional language decoder for paragraph image captioning,” Neurocomputing, vol. 396, pp. 92–101, 2020. doi: 10.1016/j.neucom.2020.02.041 |
| [217] |
Z. Fei, “Iterative back modification for faster image captioning,” in Proc. 28th ACM Int. Conf. Multimedia, 2020, pp. 3182−3190.
|
| [218] |
L. Guo, J. Liu, X. Zhu, and H. Lu, “Fast sequence generation with multi-agent reinforcement learning,” arXiv preprint arXiv: 2101.09698, 2021.
|




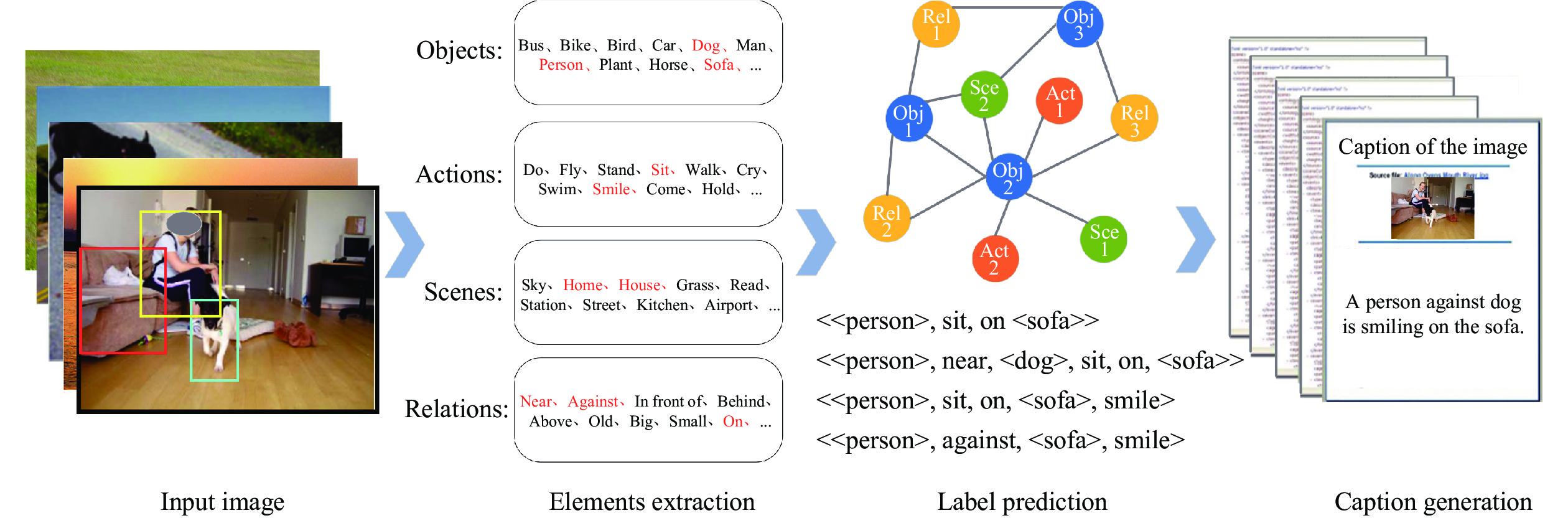
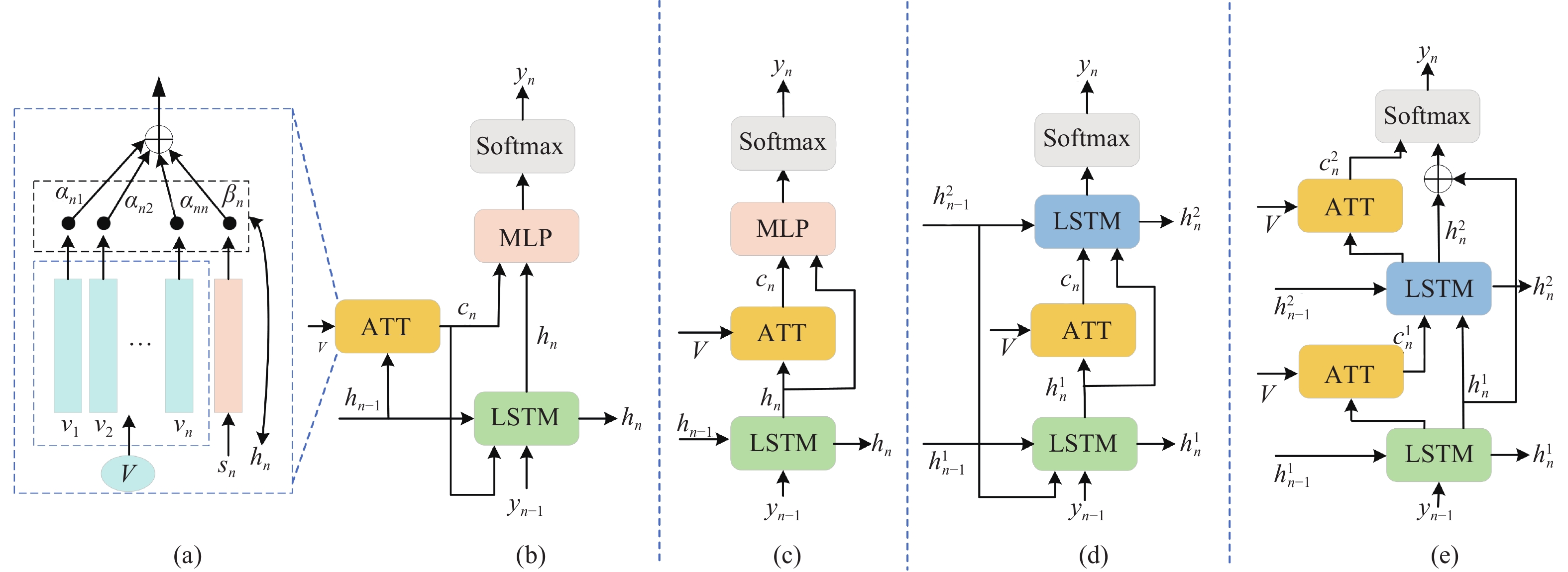
 DownLoad:
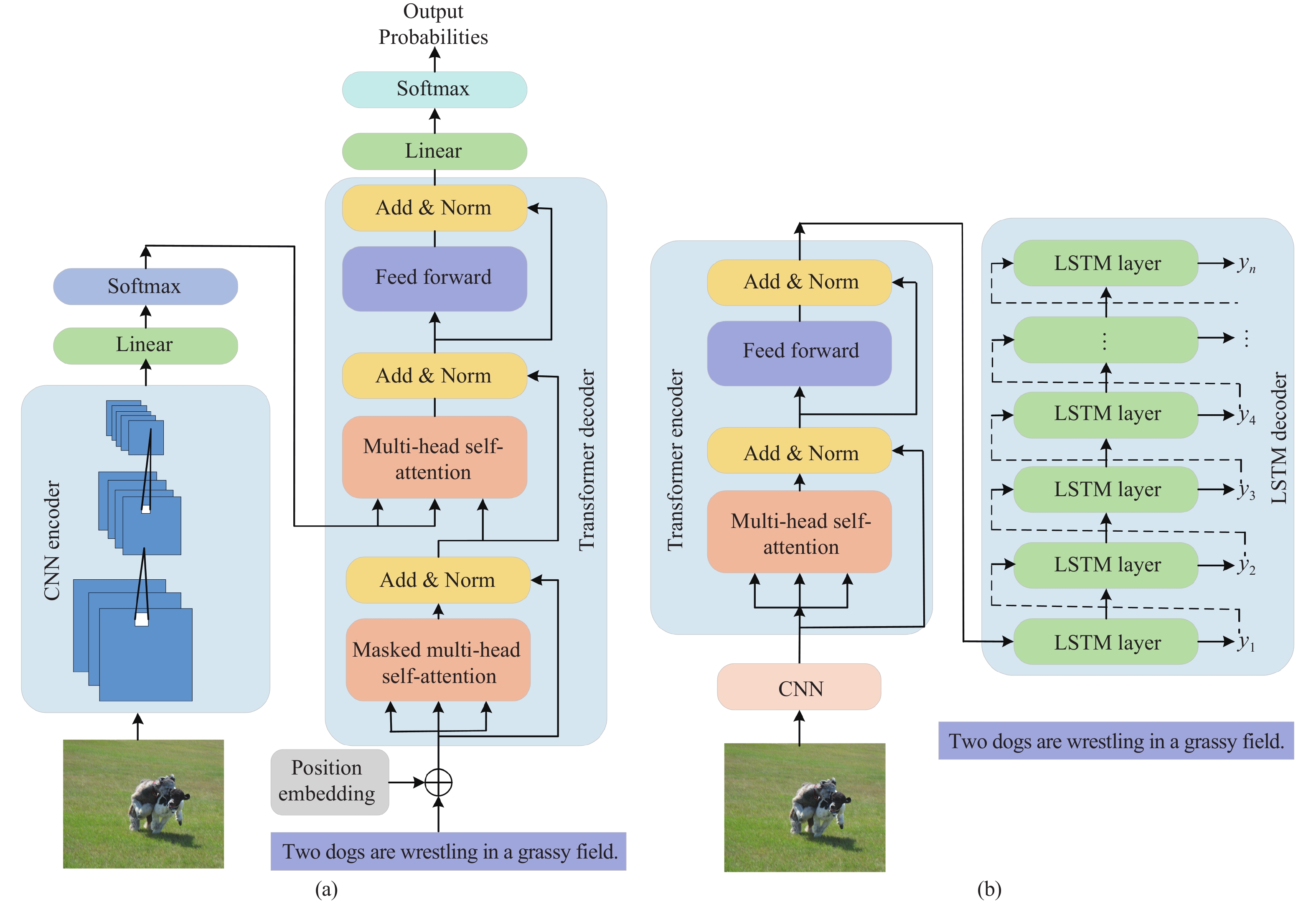
DownLoad:



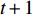
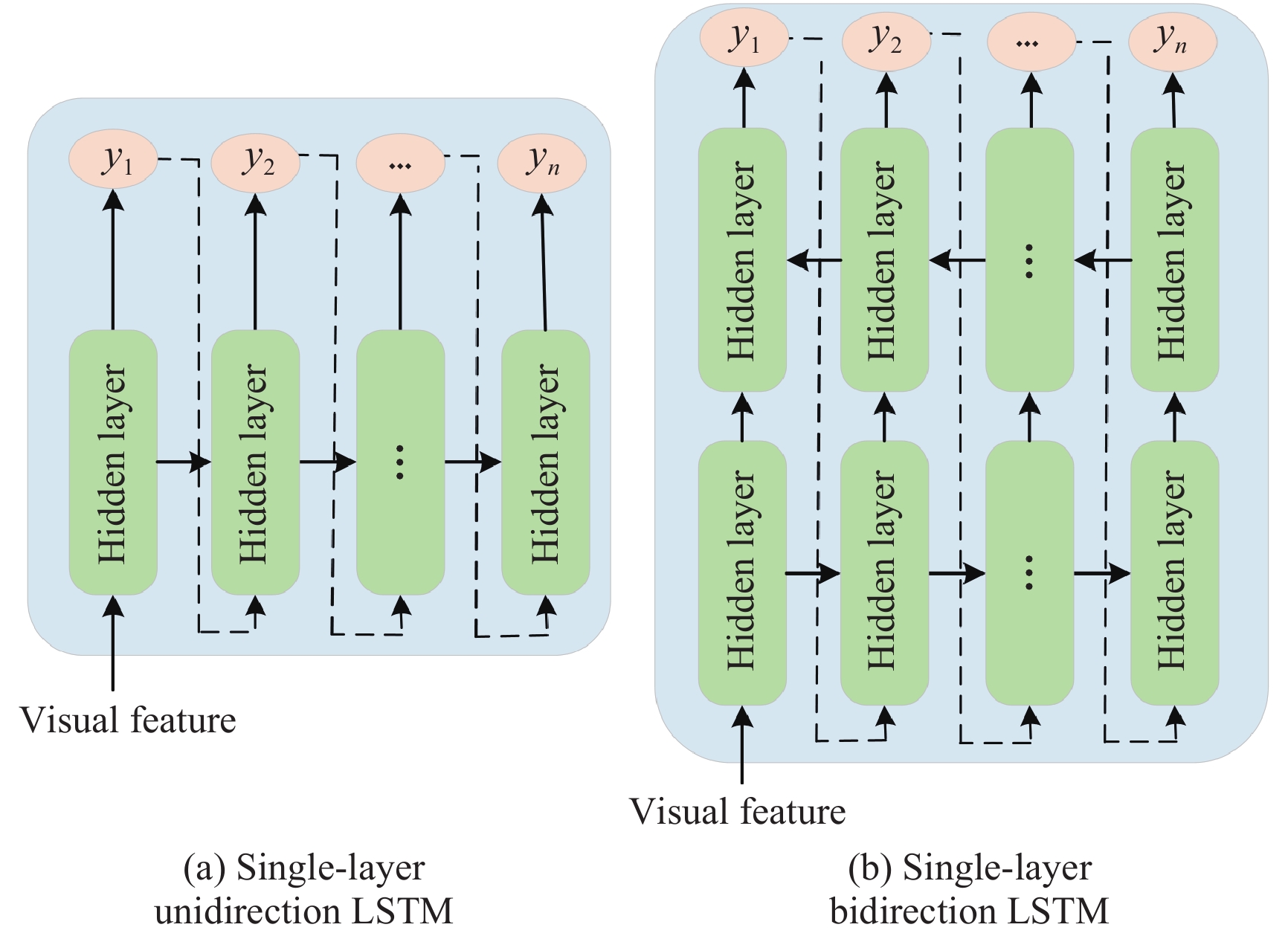
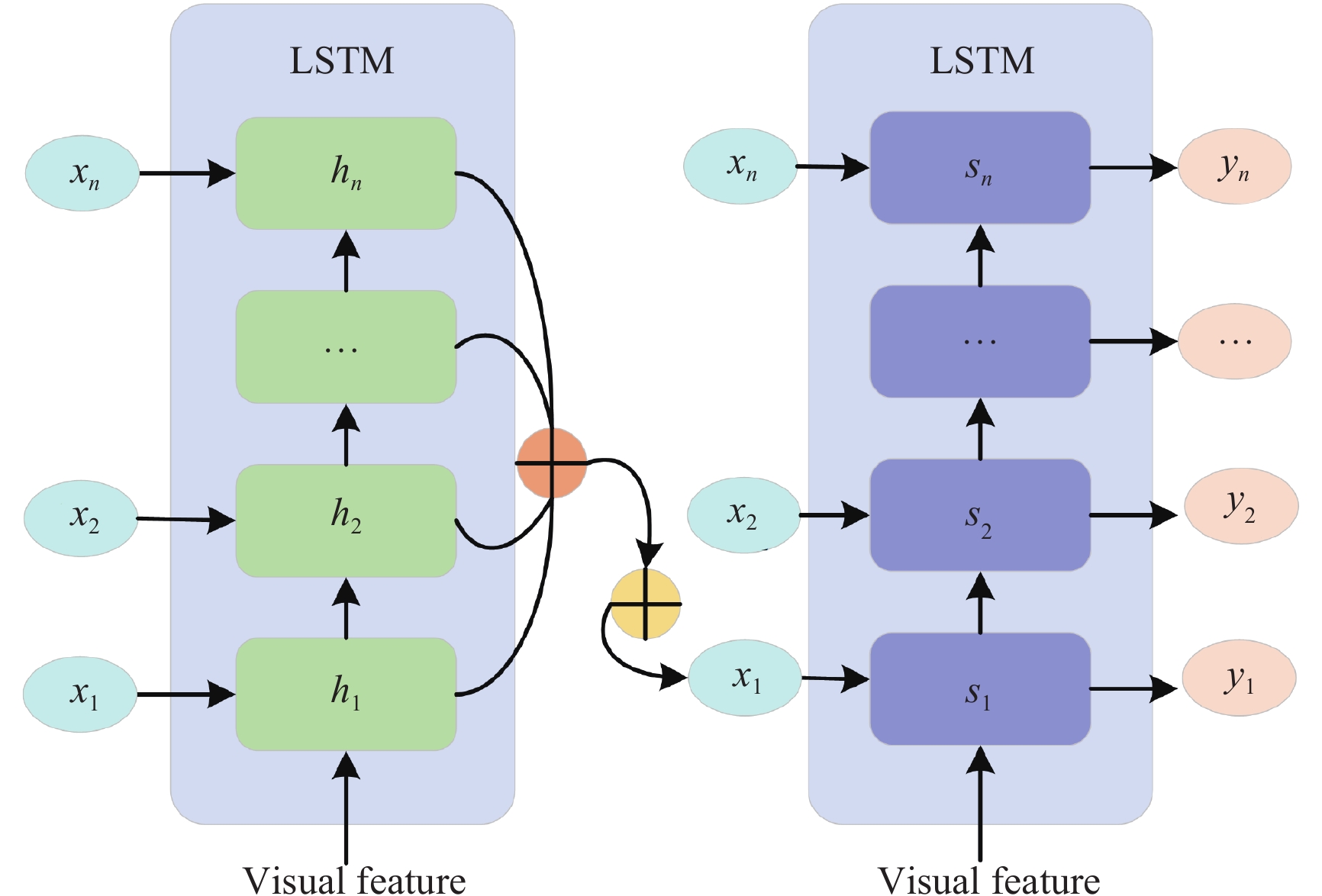
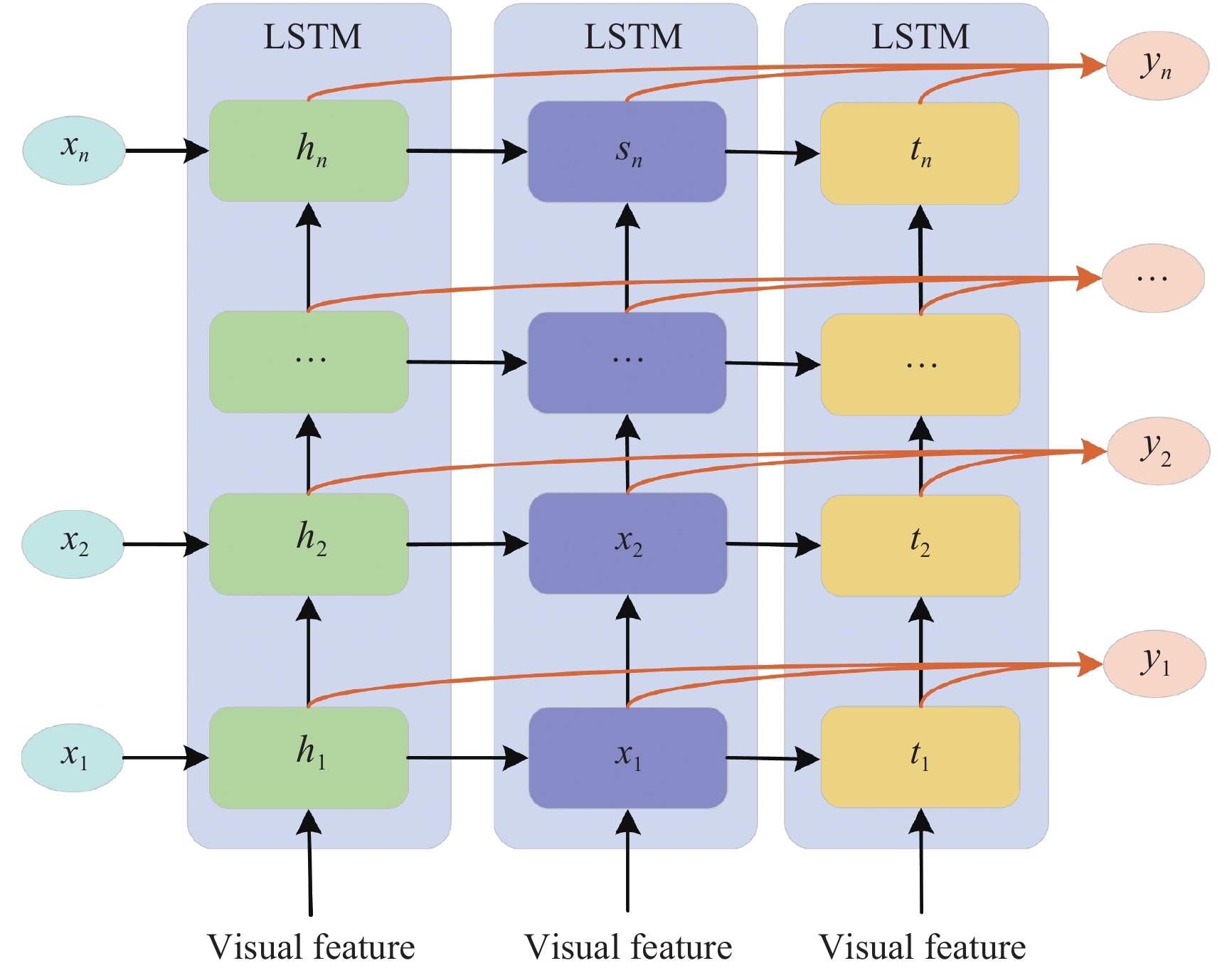
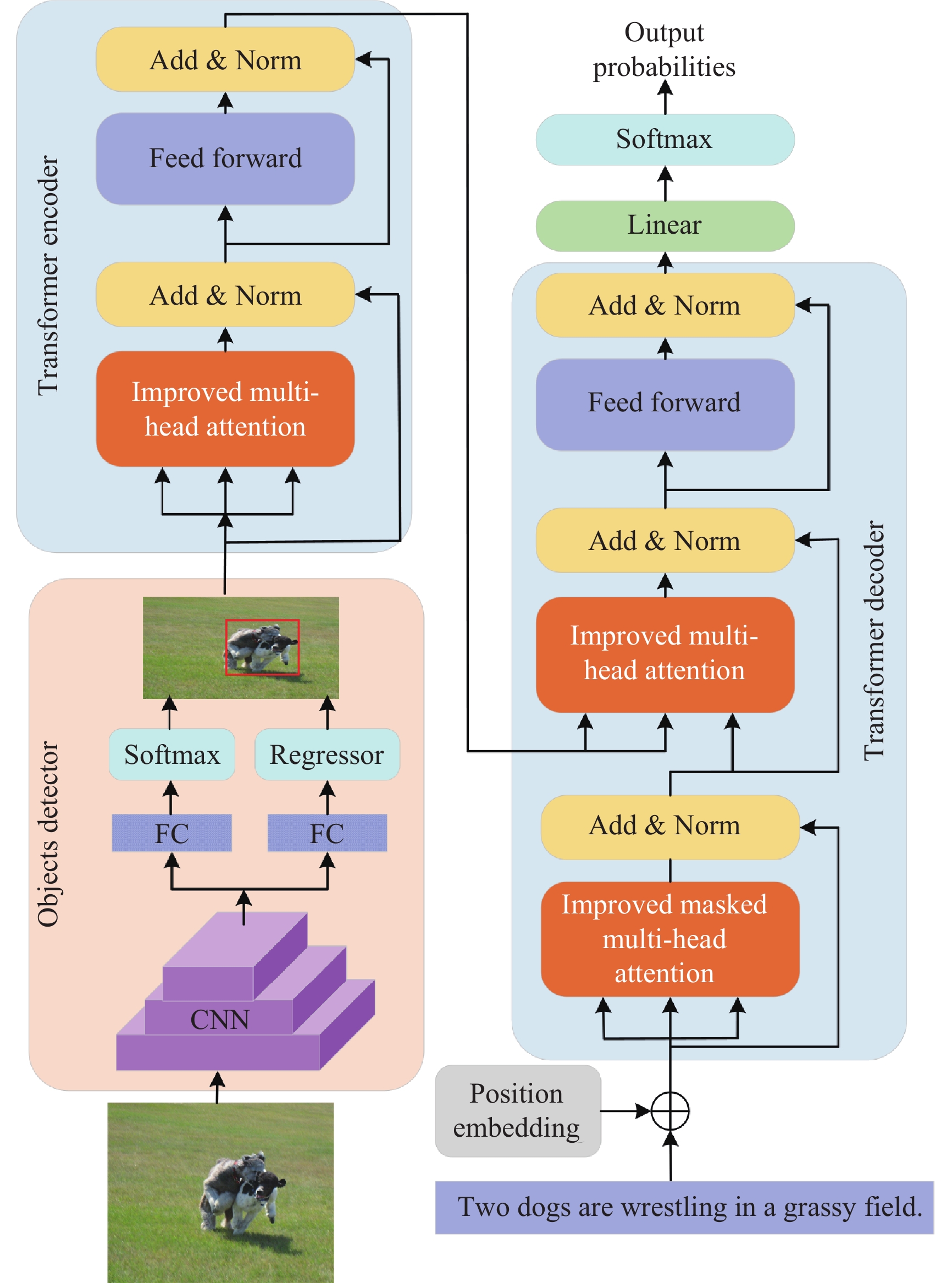
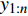
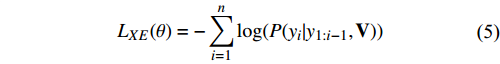
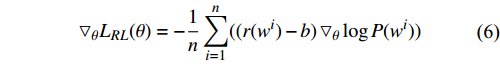
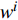
 DownLoad:
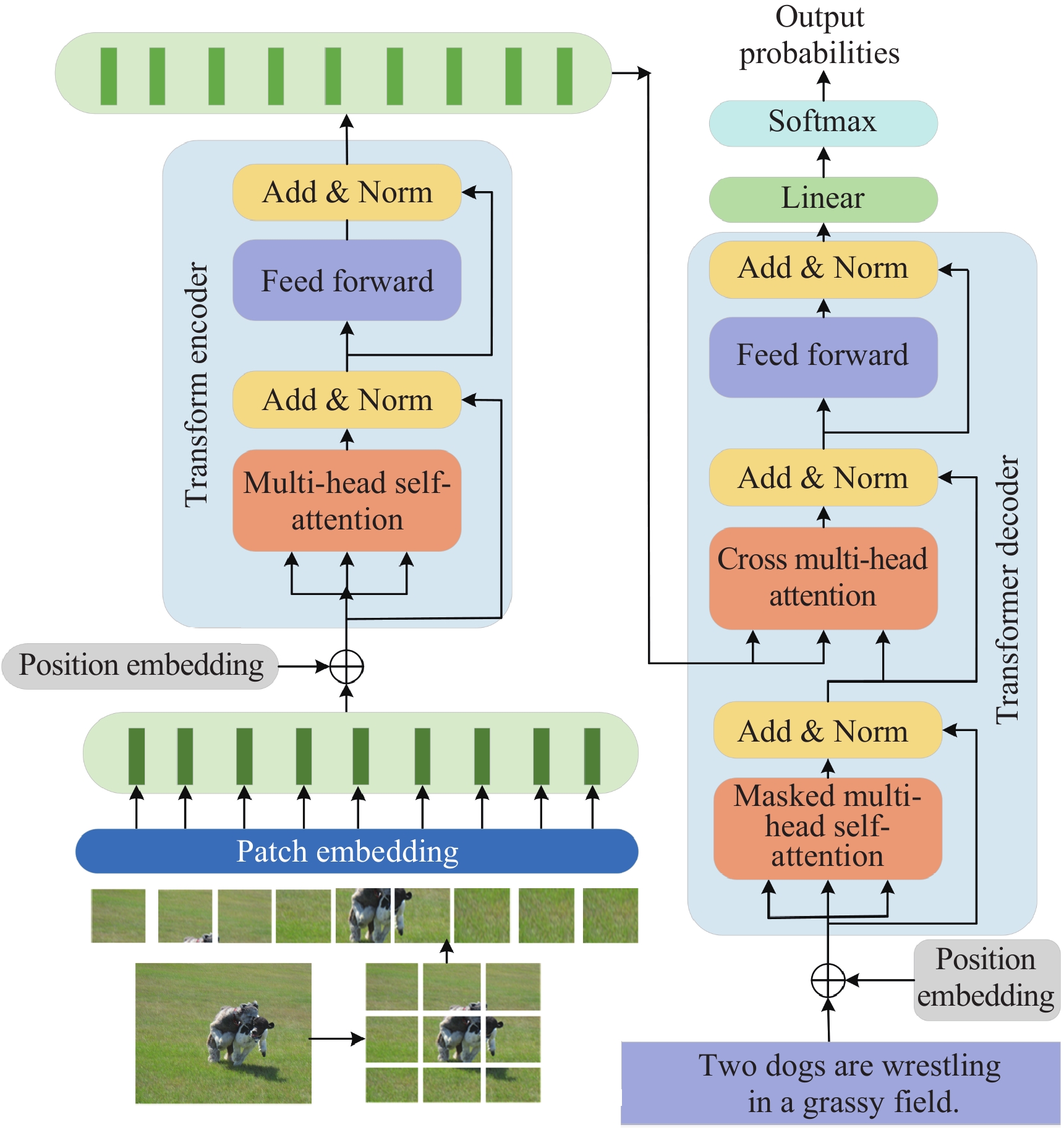
DownLoad:


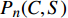



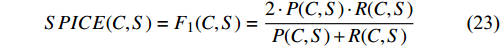

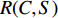







 DownLoad:
DownLoad: