A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation

IEEE/CAA Journal of Automatica Sinica
| Citation: | L. Chen, P. Deng, L. Li, and X. Hu, “Mixed motivation driven social multi-agent reinforcement learning for autonomous driving,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 6, pp. 1–11, Jun. 2025.

|

| [1] |
S. Teng, X. Hu, P. Deng, B. Li, Y. Li, Y. Ai, D. Yang, L. Li, Z. Xuanyuan, F. Zhu, and L. Chen, “Motion planning for autonomous driving: The state of the art and future perspectives,” IEEE Trans. Intelligent Vehicles, vol. 8, no. 6, pp. 3692–3711, 2023. doi: 10.1109/TIV.2023.3274536
|
| [2] |
L. Chen, Y. Li, C. Huang, B. Li, Y. Xing, D. Tian, L. Li, Z. Hu, X. Na, Z. Li, C. Lv, J. Wang, D. Cao, N. Zheng, and F.-Y. Wang, “Milestones in autonomous driving and intelligent vehicles: Survey of surveys,” IEEE Trans. Intelligent Vehicles, vol. 8, no. 2, pp. 1046–1056, 2023. doi: 10.1109/TIV.2022.3223131
|
| [3] |
Y. Hu, J. Yang, L. Chen, et al., “Planning-oriented autonomous driving,” in Proc. the IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2023, pp. 17 853–17 862.
|
| [4] |
L. Chen, Y. Xie, Y. Wang, S. Ge, and F.-Y. Wang, “Sustainable mining in the ERA of artificial intelligence,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 1, pp. 1–4, 2024. doi: 10.1109/JAS.2023.124182
|
| [5] |
X. Hu, S. Li, T. Huang, B. Tang, R. Huai, and L. Chen, “How simulation helps autonomous driving: A survey of sim2real, digital twins, and parallel intelligence,” IEEE Trans. Intelligent Vehicles, vol. 9, no. 1, pp. 593–612, 2024. doi: 10.1109/TIV.2023.3312777
|
| [6] |
Y. Ma, Z. Wang, H. Yang, and L. Yang, “Artificial intelligence applications in the development of autonomous vehicles: A survey,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 2, pp. 315–329, 2020. doi: 10.1109/JAS.2020.1003021
|
| [7] |
L. Chen, X. Hu, W. Tian, H. Wang, D. Cao, and F.-Y. Wang, “Parallel planning: A new motion planning framework for autonomous driving,” IEEE/CAA J. Autom. Sinica, vol. 6, no. 1, pp. 236–246, 2018.
|
| [8] |
X. Hu, B. Tang, L. Chen, S. Song, and X. Tong, “Learning a deep cascaded neural network for multiple motion commands prediction in autonomous driving,” IEEE Trans. Intelligent Transportation Systems, vol. 22, no. 12, pp. 7585–7596, 2020.
|
| [9] |
L. Chen, X. Hu, B. Tang, and Y. Cheng, “Conditional dqn-based motion planning with fuzzy logic for autonomous driving,” IEEE Trans. Intelligent Transportation Systems, vol. 23, no. 4, pp. 2966–2977, 2020.
|
| [10] |
T. Zhou, M. Chen, and J. Zou, “Reinforcement learning based data fusion method for multi-sensors,” IEEE/CAA J. Autom. Sinica, vol. 7, no. 6, pp. 1489–1497, 2020. doi: 10.1109/JAS.2020.1003180
|
| [11] |
S. Teng, L. Li, Y. Li, X. Hu, L. Li, Y. Ai, and L. Chen, “Fusionplanner: A multi-task motion planner for mining trucks via multi-sensor fusion,” Mechanical Systems and Signal Processing, vol. 208, p. 111051, 2024.
|
| [12] |
Y. Lin, G. Hu, L. Wang, Q. Li, and J. Zhu, “A multi-agv routing planning method based on deep reinforcement learning and recurrent neural network,” IEEE/CAA J. Autom. Sinica, 2023.
|
| [13] |
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,” arXiv preprint arXiv: 2306.16927, 2023.
|
| [14] |
L. D’Alfonso, F. Giannini, G. Franzè, G. Fedele, F. Pupo, and G. Fortino, “Autonomous vehicle platoons in urban road networks: A joint distributed reinforcement learning and model predictive control approach,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 1, pp. 141–156, 2024. doi: 10.1109/JAS.2023.123705
|
| [15] |
X. Hu, L. Chen, B. Tang, D. Cao, and H. He, “Dynamic path planning for autonomous driving on various roads with avoidance of static and moving obstacles,” Mech. Syst. Signal Process., vol. 100, pp. 482–500, 2018. doi: 10.1016/j.ymssp.2017.07.019
|
| [16] |
T. Zhang, W. Song, M. Fu, Y. Yang, and M. Wang, “Vehicle motion prediction at intersections based on the turning intention and prior trajectories model,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 10, pp. 1657–1666, 2021. doi: 10.1109/JAS.2021.1003952
|
| [17] |
L. Crosato, H. P. Shum, E. S. Ho, and C. Wei, “Interaction-aware decision-making for automated vehicles using social value orientation,” IEEE Trans. Intelligent Vehicles, vol. 8, no. 2, pp. 1339–1349, 2022.
|
| [18] |
X. Hu, Y. Liu, B. Tang, J. Yan, and L. Chen, “Learning dynamic graph for overtaking strategy in autonomous driving,” IEEE Trans. Intelligent Transportation Systems, 2023.
|
| [19] |
J. Wang, Q. Zhang, and D. Zhao, “Highway lane change decision-making via attention-based deep reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 3, pp. 567–569, 2021.
|
| [20] |
X. Tang, Y. Yang, T. Liu, X. Lin, K. Yang, and S. Li, “Path planning and tracking control for parking via soft actor-critic under non-ideal scenarios,” IEEE/CAA J. Autom. Sinica, 2023.
|
| [21] |
T. Zhang, J. Zhan, J. Shi, J. Xin, and N. Zheng, “Human-like decision-making of autonomous vehicles in dynamic traffic scenarios,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 10, pp. 1905–1917, 2023. doi: 10.1109/JAS.2023.123696
|
| [22] |
W. Schwarting, A. Pierson, J. Alonso-Mora, S. Karaman, and D. Rus, “Social behavior for autonomous vehicles,” Proc. the National Academy of Sciences, vol. 116, no. 50, pp. 24972–24978, 2019. doi: 10.1073/pnas.1820676116
|
| [23] |
M. Zhou, J. Luo, J. Villella, et al., “Smarts: Scalable multi-agent reinforcement learning training school for autonomous driving,” arXiv preprint arXiv: 2010.09776, 2020.
|
| [24] |
Q. Li, Z. Peng, L. Feng, Q. Zhang, Z. Xue, and B. Zhou, “Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3461–3475, 2022.
|
| [25] |
Z. Peng, Q. Li, K. M. Hui, C. Liu, and B. Zhou, “Learning to simulate self-driven particles system with coordinated policy optimization,” Advances in Neural Information Processing Systems, vol. 34, pp. 10784–10797, 2021.
|
| [26] |
X. He and C. Lv, “Towards energy-efficient autonomous driving: A multi-objective reinforcement learning approach,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1329–1331, 2023. doi: 10.1109/JAS.2023.123378
|
| [27] |
O. Vinyals, I. Babuschkin, W. M. Czarnecki, et al, “Grandmaster level in starcraft ii using multi-agent reinforcement learning,” Nature, vol. 575, no. 7782, pp. 350–354, 2019. doi: 10.1038/s41586-019-1724-z
|
| [28] |
Y. Zhang, L. Zhang, and Y. Cai, “Value iteration-based cooperative adaptive optimal control for multi-player differential games with incomplete information,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 3, pp. 690–697, 2024. doi: 10.1109/JAS.2023.124125
|
| [29] |
T. Yu, J. Huang, and Q. Chang, “Optimizing task scheduling in human-robot collaboration with deep multi-agent reinforcement learning,” J. Manufacturing Systems, vol. 60, pp. 487–499, 2021. doi: 10.1016/j.jmsy.2021.07.015
|
| [30] |
V. P. Tran, M. A. Garratt, K. Kasmarik, and S. G. Anavatti, “Dynamic frontier-led swarming: Multi-robot repeated coverage in dynamic environments,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 3, pp. 646–661, 2023. doi: 10.1109/JAS.2023.123087
|
| [31] |
J. Kang, J. Chen, M. Xu, Z. Xiong, Y. Jiao, L. Han, D. Niyato, Y. Tong, and S. Xie, “UAV-assisted dynamic avatar task migration for vehicular metaverse services: A multi-agent deep reinforcement learning approach,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 2, pp. 430–445, 2024. doi: 10.1109/JAS.2023.123993
|
| [32] |
X. Wang, C. Zhao, T. Huang, P. Chakrabarti, and J. Kurths, “Cooperative learning of multi-agent systems via reinforcement learning,” IEEE Trans. Signal and Information Processing Over Networks, vol. 9, pp. 13–23, 2023. doi: 10.1109/TSIPN.2023.3239654
|
| [33] |
K. Kurach, A. Raichuk, P. Stańczyk, et al., “Google research football: A novel reinforcement learning environment,” in Proc. AAAI Conf. Artificial Intelligence, 2020, vol. 34, no. 04, pp. 4501–4510.
|
| [34] |
M. Samvelyan, T. Rashid, C. S. De Witt, G. Farquhar, N. Nardelli, T. G. Rudner, C.-M. Hung, P. H. Torr, J. Foerster, and S. Whiteson, “The starcraft multi-agent challenge,” arXiv preprint arXiv: 1902.04043, 2019.
|
| [35] |
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi-agent reinforcement learning,” The J. Machine Learning Research, vol. 21, no. 1, pp. 7234–7284, 2020.
|
| [36] |
R. Lowe, Y. I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,” Advances in Neural Information Processing Systems, vol. 30, 2017.
|
| [37] |
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y. Wang, A. Bayen, and Y. Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,” Advances in Neural Information Processing Systems, vol. 35, pp. 24611–24624, 2022.
|
| [38] |
K. R. McKee, I. Gemp, B. McWilliams, E. A. Duéñez-Guzmán, E. Hughes, and J. Z. Leibo, “Social diversity and social preferences in mixed-motive reinforcement learning,” arXiv preprint arXiv: 2002.02325, 2020.
|
| [39] |
M. Tan, “Multi-agent reinforcement learning: Independent vs. cooperative agents,” in Proc. 10th Int. Conf. Machine Learning, 1993, pp. 330–337.
|
| [40] |
C. S. de Witt, T. Gupta, D. Makoviichuk, V. Makoviychuk, P. H. Torr, M. Sun, and S. Whiteson, “Is independent learning all you need in the starcraft multi-agent challenge?” arXiv preprint arXiv: 2011.09533, 2020.
|
| [41] |
X. Xu, L. Zuo, X. Li, L. Qian, J. Ren, and Z. Sun, “A reinforcement learning approach to autonomous decision making of intelligent vehicles on highways,” IEEE Trans. Systems, Man, and Cybern.: Systems, vol. 50, no. 10, pp. 3884–3897, 2018.
|
| [42] |
X. Chen, B. Fu, Y. He, and M. Wu, “Timesharing-tracking framework for decentralized reinforcement learning in fully cooperative multi-agent system,” IEEE/CAA J. Autom. Sinica, vol. 1, no. 2, pp. 127–133, 2014. doi: 10.1109/JAS.2014.7004541
|
| [43] |
J. Dollard and N. E. Miller, Social Learning and Imitation. Routledge, 2013.
|
| [44] |
R. L. Akers and W. G. Jennings, “Social learning theory,” The Handbook of Criminological Theory, pp. 230–240, 2015.
|
| [45] |
S. Sen and S. Airiau, “Emergence of norms through social learning.” in Proc. IJCAI, 2007, vol. 1507, p. 1512.
|
| [46] |
X. Chen, Z. Li, and X. Di, “Social learning in Markov games: Empowering autonomous driving,” in Proc. IEEE Intelligent Vehicles Symposium, 2022, pp. 478–483.
|
| [47] |
J. Wang, Y. Hong, J. Wang, J. Xu, Y. Tang, Q.-L. Han, and J. Kurths, “Cooperative and competitive multi-agent systems: From optimization to games,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 5, pp. 763–783, 2022. doi: 10.1109/JAS.2022.105506
|
| [48] |
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” in Proc. AAAI Conf. Artificial Intelligence, 2018, vol. 32, p. 1.
|
| [49] |
P. Sunehag, G. Lever, A. Gruslys, et al., “Value-decomposition networks for cooperative multi-agent learning,” arXiv preprint arXiv: 1706.05296, 2017.
|
| [50] |
J. Wang, Z. Ren, T. Liu, Y. Yu, and C. Zhang, “Qplex: Duplex dueling multi-agent q-learning,” arXiv preprint arXiv: 2008.01062, 2020.
|
| [51] |
Z. Dai, T. Zhou, K. Shao, D. H. Mguni, B. Wang, and H. Jianye, “Socially-attentive policy optimization in multi-agent self-driving system,” in Proc. Conf. Robot Learning, 2023, pp. 946–955.
|
| [52] |
B. Toghi, R. Valiente, D. Sadigh, R. Pedarsani, and Y. P. Fallah, “Social coordination and altruism in autonomous driving,” IEEE Trans. Intelligent Transportation Systems, vol. 23, no. 12, pp. 24 791–24 804, 2022. doi: 10.1109/TITS.2022.3207872
|
| [53] |
F. A. Oliehoek, C. Amato, et al., A Concise Introduction to Decentralized POMDPs. Springer, 2016, vol. 1.
|
| [54] |
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv: 1707.06347, 2017.
|
| [55] |
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High-dimensional continuous control using generalized advantage estimation,” arXiv preprint arXiv: 1506.02438, 2015.
|
| [56] |
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv: 1503.02531, 2015.
|
| [57] |
A. A. Rusu, S. G. Colmenarejo, C. Gulcehre, G. Desjardins, J. Kirkpatrick, R. Pascanu, V. Mnih, K. Kavukcuoglu, and R. Hadsell, “Policy distillation,” arXiv preprint arXiv: 1511.06295, 2015.
|
| [58] |
A. Hussein, M. M. Gaber, E. Elyan, and C. Jayne, “Imitation learning: A survey of learning methods,” ACM Computing Surveys, vol. 50, no. 2, pp. 1–35, 2017.
|
| [59] |
C.-A. Cheng, X. Yan, N. Wagener, and B. Boots, “Fast policy learning through imitation and reinforcement,” arXiv preprint arXiv: 1805.10413, 2018.
|
| [60] |
Z. Xue, Z. Peng, Q. Li, Z. Liu, and B. Zhou, “Guarded policy optimization with imperfect online demonstrations,” in Proc. 11st Int. Conf. Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=O5rKg7IRQIO
|
| [61] |
E. Liang, R. Liaw, R. Nishihara, P. Moritz, R. Fox, K. Goldberg, J. Gonzalez, M. Jordan, and I. Stoica, “Rllib: Abstractions for distributed reinforcement learning,” in Proc. Int. Conf. Machine Learning, 2018, pp. 3053–3062.
|
| [62] |
Y. Yang, R. Luo, M. Li, M. Zhou, W. Zhang, and J. Wang, “Mean field multi-agent reinforcement learning,” in Proc. Int. Conf. Machine Learning, 2018, pp. 5571–5580.
|
| [63] |
M. Babes, E. Munoz de Cote, and M. L. Littman, “Social reward shaping in the prisoner’s dilemma,” 2008.
|
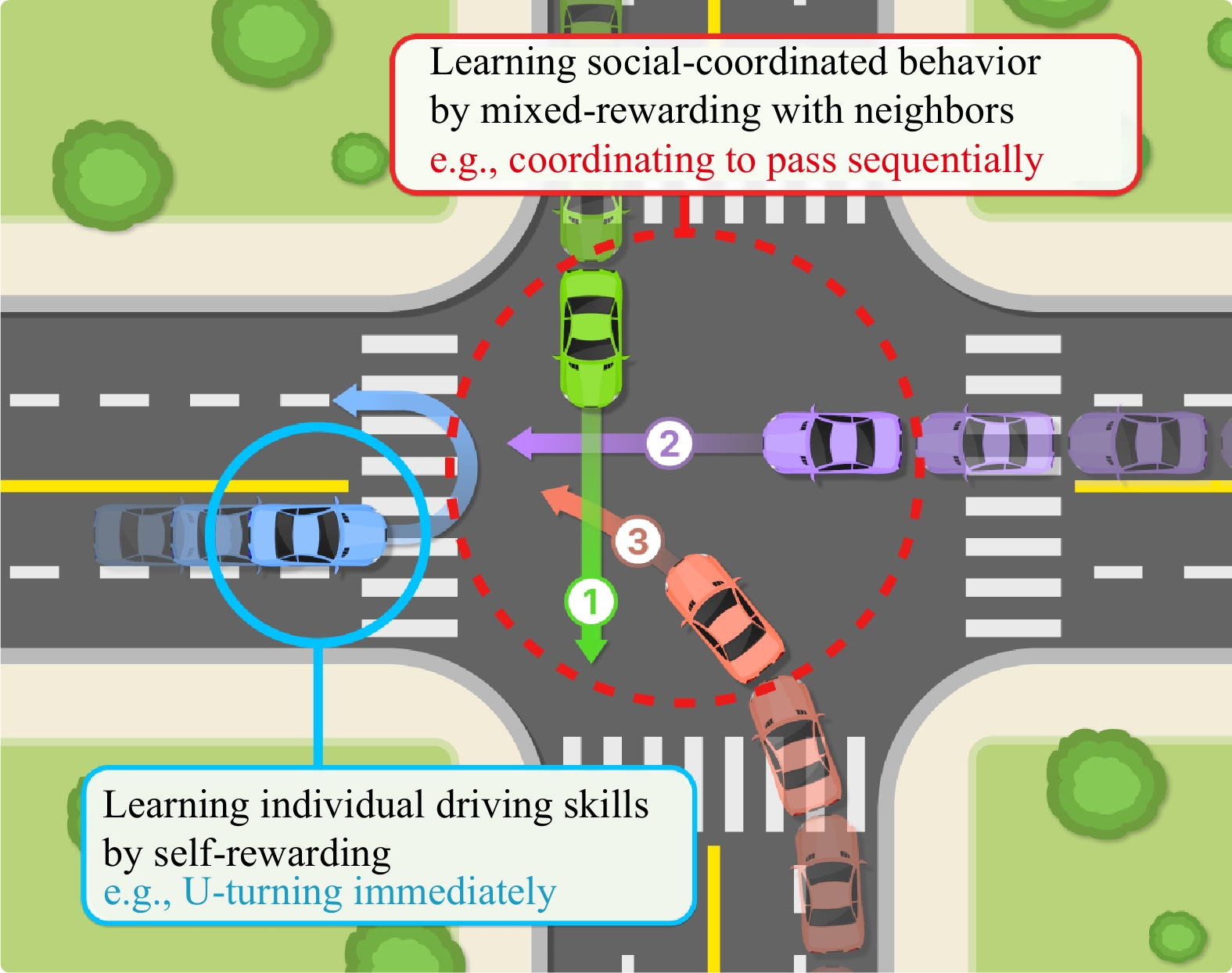
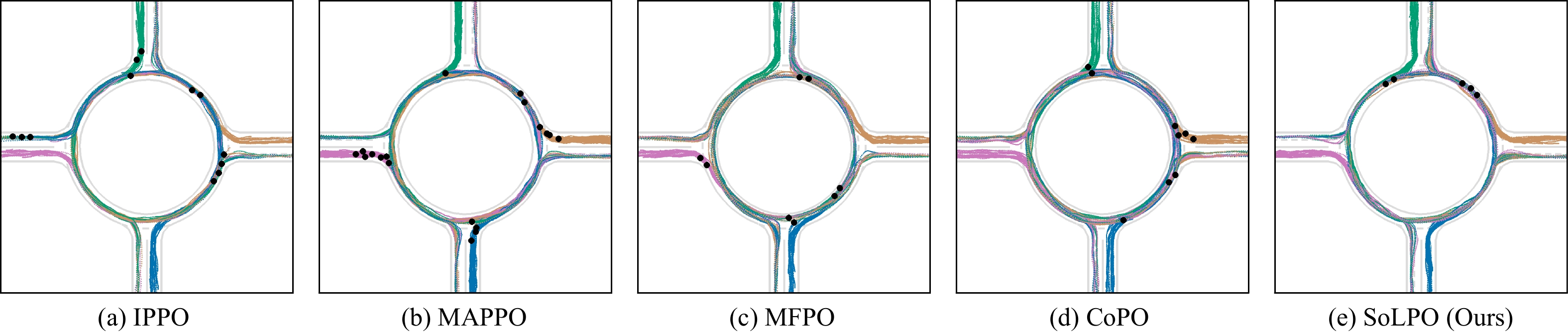
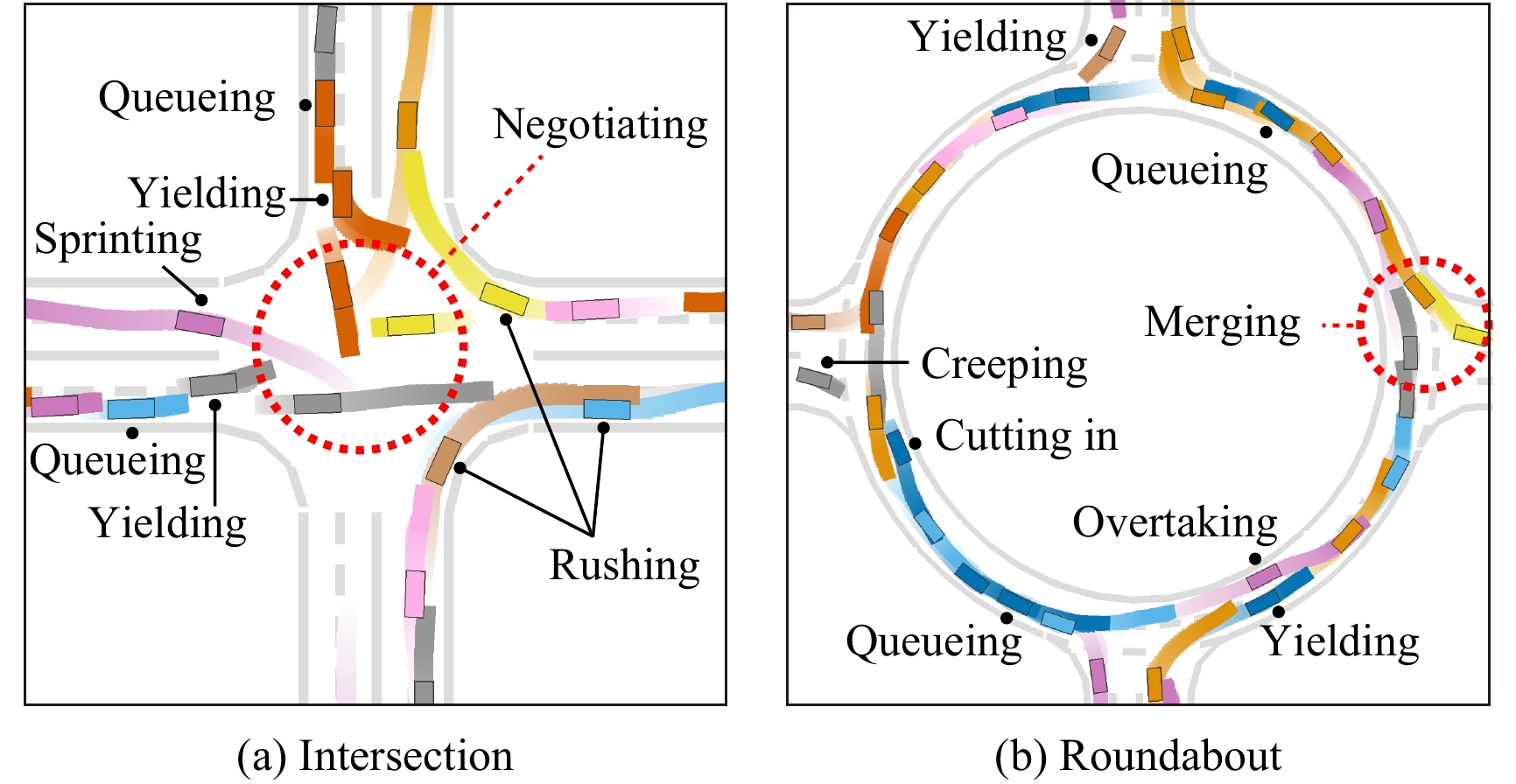
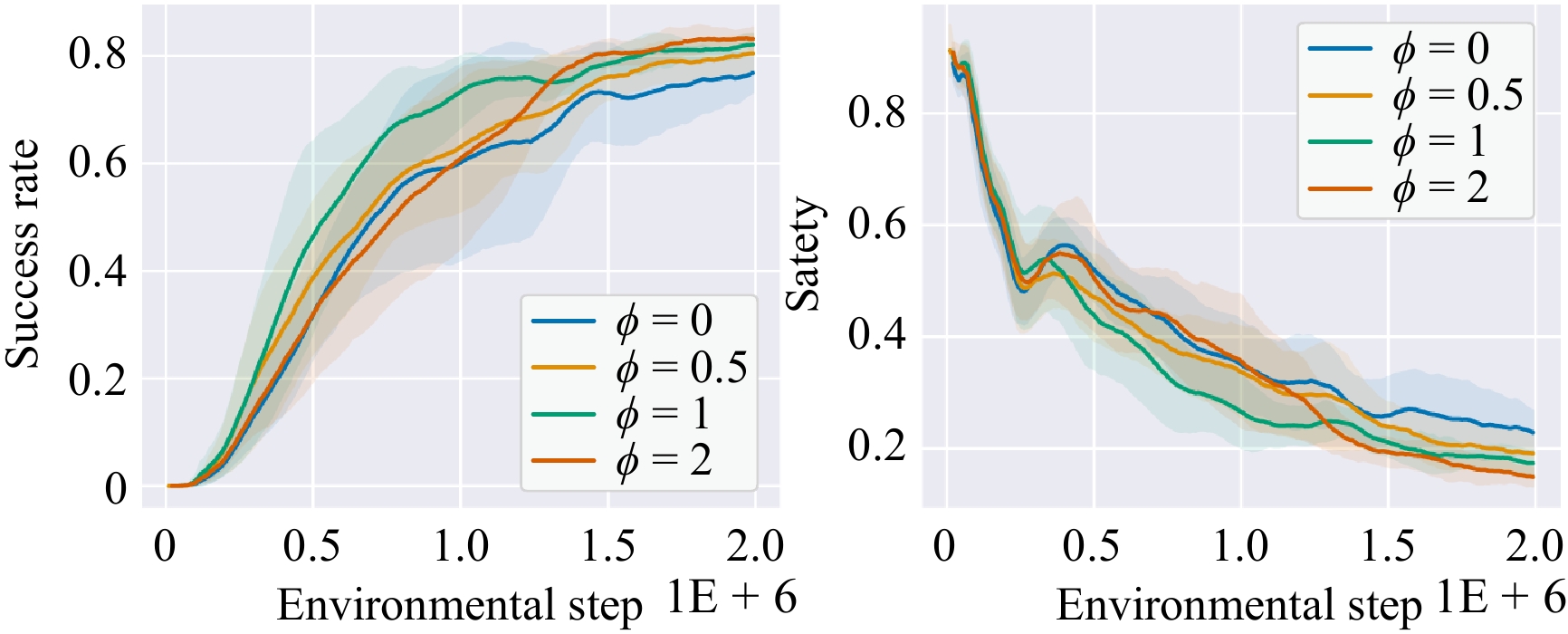
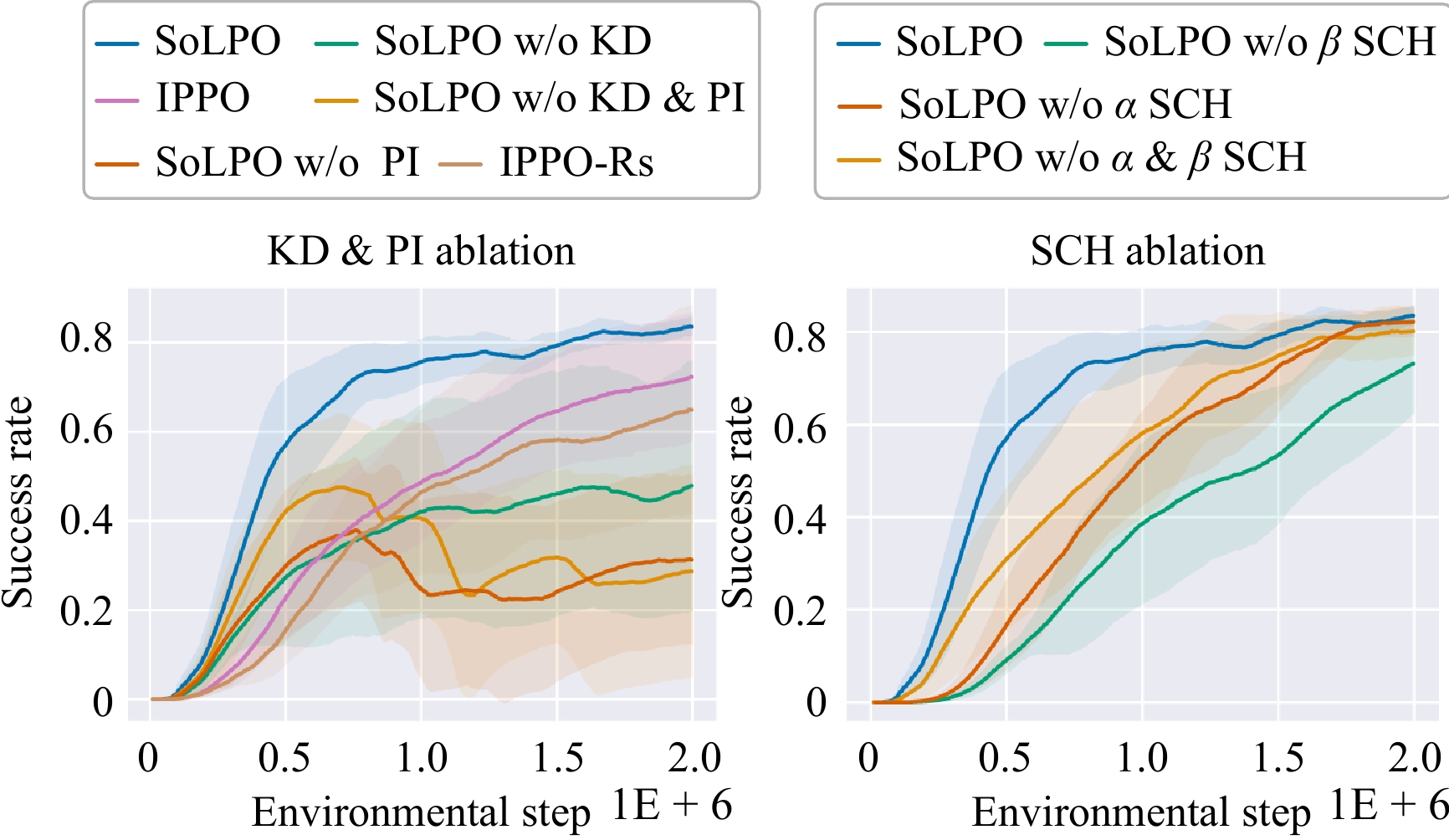
Figures(9) / Tables(5)






 DownLoad:
DownLoad: