A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation

IEEE/CAA Journal of Automatica Sinica
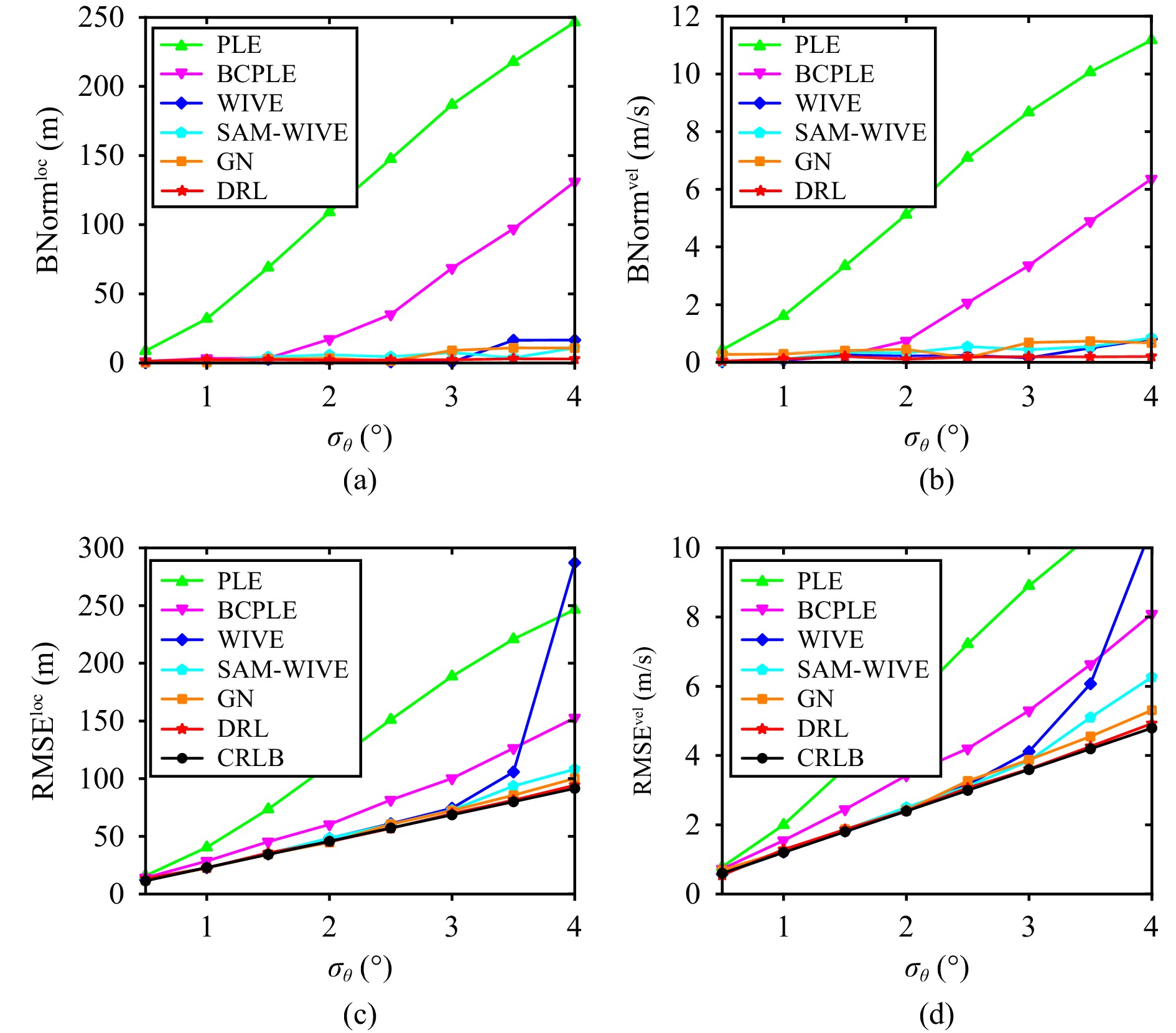
| Citation: | C. Zhou, M. Liu, S. Zhang, R. Zheng, and S. Dong, “Bearings-only target motion analysis via deep reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 4, pp. 1–3, Apr. 2025.

|

| [1] |
S. C. Nardone, A. G. Lindgren, and K. F. Gong, “Fundamental properties and performance of conventional bearings-only target motion analysis,” IEEE Trans. Autom. Control, vol. 29, no. 9, pp. 775–787, 1984. doi: 10.1109/TAC.1984.1103664
|
| [2] |
H. J. Shao, X. P. Zhang, and Z. Wang, “Efficient closed-form algorithms for AOA based self-localization of sensor nodes using auxiliary variables,” IEEE Trans. Signal Process., vol. 62, no. 10, pp. 2580–2594, 2014. doi: 10.1109/TSP.2014.2314064
|
| [3] |
A. G. Lindgren and K. F. Gong, “Position and velocity estimation via bearing observations,” IEEE Trans. Aerosp. Electron. Syst., vol. AES-14, no. 4, pp. 564–577, 1978. doi: 10.1109/TAES.1978.308681
|
| [4] |
M. Arellano and O. Bover, “Another look at the instrumental variable estimation of error-components models,” J. Econometrics, vol. 68, no. 1, pp. 29–51, 1995. doi: 10.1016/0304-4076(94)01642-D
|
| [5] |
Z. Wang, J. A. Luo, and X. P. Zhang, “A novel location-penalized maximum likelihood estimator for bearing-only target localization,” IEEE Trans. Signal Process., vol. 60, no. 12, pp. 6166–6181, 2012. doi: 10.1109/TSP.2012.2218809
|
| [6] |
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, 2nd ed. Cambridge, USA: MIT Press, 2018.
|
| [7] |
K. Doğançay, “3D pseudolinear target motion analysis from angle measurements,” IEEE Trans. Signal Process., vol. 63, no. 6, pp. 1570–1580, 2015. doi: 10.1109/TSP.2015.2399869
|
| [8] |
F. Pang, K. Doğançay, N. H. Nguyen, and Q. Zhang, “AOA Pseudolinear target motion analysis in the presence of sensor location errors,” IEEE Trans. Signal Process., vol. 68, pp. 3385–3399, 2020. doi: 10.1109/TSP.2020.2998896
|
| [9] |
K. Doğançay, “Bias compensation for the bearings-only pseudolinear target track estimator,” IEEE Trans. Signal Process., vol. 54, no. 1, pp. 59–68, 2006. doi: 10.1109/TSP.2005.861088
|
| [10] |
B. D. Ziebart, A. Maas, J. A. Bagnell, and A. K. Dey, “Maximum entropy inverse reinforcement learning.,” in Proc. AAAI Conf. Artif. Intell., 2008, pp. 1433–1438.
|
| [11] |
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Offpolicy maximum entropy deep reinforcement learning with a stochastic actor,” in Proc. Int. Conf. Mach. Learn., 2018, vol. 80, pp. 1861–1870.
|
| [12] |
W. Qin and X. Luo, “Asynchronous parallel fuzzy stochastic gradient descent for high-dimensional incomplete data representation,” IEEE Trans. Fuzzy Syst., vol. 32, no. 2, pp. 445–459, 2024. doi: 10.1109/TFUZZ.2023.3300370
|
| [13] |
X. Y. Shi, Q. He, X. Luo, Y. N. Bai, and M. S. Shang, “Large-scale and scalable latent factor analysis via distributed alternative stochastic gradient descent for recommender systems,” IEEE Trans. Big Data, vol. 8, no. 2, pp. 420–431, 2022.
|
| [14] |
K. Doğançay, “Bearings-only target localization using total least squares,” Signal Process, vol. 85, no. 9, pp. 1695–1710, 2005. doi: 10.1016/j.sigpro.2005.03.007
|
Figures(1)






 DownLoad:
DownLoad: