A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
F. Y. Zhang, Q. Y. Yang, and D. An, “Privacy preserving demand side management method via multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 10, pp. 1984–1999, Oct. 2023. doi: 10.1109/JAS.2023.123321
Citation:
F. Y. Zhang, Q. Y. Yang, and D. An, “Privacy preserving demand side management method via multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 10, pp. 1984–1999, Oct. 2023. doi: 10.1109/JAS.2023.123321
F. Y. Zhang, Q. Y. Yang, and D. An, “Privacy preserving demand side management method via multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 10, pp. 1984–1999, Oct. 2023. doi: 10.1109/JAS.2023.123321
Citation:
F. Y. Zhang, Q. Y. Yang, and D. An, “Privacy preserving demand side management method via multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 10, pp. 1984–1999, Oct. 2023. doi: 10.1109/JAS.2023.123321
Funds:
This work was supported in part by the National Science Foundation of China (61973247, 61673315, 62173268), the Key Research and Development Program of Shaanxi (2022GY-033), the National Postdoctoral Innovative Talents Support Program of China (BX20200272), the Key Program of the National Natural Science Foundation of China (61833015), and the Fundamental Research Funds for the Central Universities (xzy022021050)
Feiye Zhang received the B.S. degree in electronic science and technology from Xi’an Jiaotong University in 2019. He is currently a Ph.D. degree candidate in control science and engineering at the Faculty of Electronic and Information Engineering, Xi’an Jiaotong University. His current research interests include multi-agent systems, reinforcement learning, and privacy preserving methods
Qingyu Yang (Member, IEEE) received the B.S. and M.S. degrees in mechatronics engineering and the Ph.D. degree in control science and engineering from Xi’an Jiaotong University in 1996, 1999, and 2003, respectively. He is a Professor with the Faculty of Electronic and InformationEngineering, Xi’an Jiaotong University, where he is also with the State Key Laboratory for Manufacturing Systems Engineering, Xi’an Jiaotong University. His current research interests include cyber-physical systems, power grid security and privacy, control and diagnosis of mechatronic systems, and intelligent control of industrial process
Dou An received the Ph.D. degree in control science and engineering from Xi’an Jiaotong University in 2017. He is currently an Associate Professor with the Faculty of Electronic and Information Engineering, Xi’an Jiaotong University, where he is also with the MOE Key Laboratory for Intelligent Networks and Network Security, Xi’an Jiaotong University. His current research interests include cyber-physical systems, IoT security and privacy, and incentive mechanism design for smart grid and IoT
The smart grid utilizes the demand side management technology to motivate energy users towards cutting demand during peak power consumption periods, which greatly improves the operation efficiency of the power grid. However, as the number of energy users participating in the smart grid continues to increase, the demand side management strategy of individual agent is greatly affected by the dynamic strategies of other agents. In addition, the existing demand side management methods, which need to obtain users’ power consumption information, seriously threaten the users’ privacy. To address the dynamic issue in the multi-microgrid demand side management model, a novel multi-agent reinforcement learning method based on centralized training and decentralized execution paradigm is presented to mitigate the damage of training performance caused by the instability of training experience. In order to protect users’ privacy, we design a neural network with fixed parameters as the encryptor to transform the users’ energy consumption information from low-dimensional to high-dimensional and theoretically prove that the proposed encryptor-based privacy preserving method will not affect the convergence property of the reinforcement learning algorithm. We verify the effectiveness of the proposed demand side management scheme with the real-world energy consumption data of Xi’an, Shaanxi, China. Simulation results show that the proposed method can effectively improve users’ satisfaction while reducing the bill payment compared with traditional reinforcement learning (RL) methods (i.e., deep Q learning (DQN), deep deterministic policy gradient (DDPG), QMIX and multi-agent deep deterministic policy gradient (MADDPG)). The results also demonstrate that the proposed privacy protection scheme can effectively protect users’ privacy while ensuring the performance of the algorithm.
THE smart grid [1] integrates efficient sensing technology, accurate measurement technology and advanced control methods to realize the efficient, safe and stable operation of the power grid system [2]. As a significant component of balancing the power demand during peak consumption periods in the smart grid, the demand side management (DSM) technology motivates the power users to change their inherent power consumption behavior by adopting certain incentives (e.g., financial compensation), which can achieve the objective of optimizing resource allocation and ensuring efficient operation of the power grid system [3].
Recently, multiple DSM paradigms have been proposed and implemented in the power grid operation, the research efforts of DSM can be mainly divided into the following two categories: price-based mechanism [4] and incentive-based mechanism [5]. Price-based DSM paradigm utilizes the electricity consumption controller (ECC) to offer energy users with autonomous load arrangement in response to the changes of energy prices [6]. And incentive-based DSM paradigm encourages energy users to reduce their peak-periods energy consumption via the economic compensation [7]. Although the DSM technology has been proven to significantly improve the efficiency of resource allocation, the uncertainties of the energy price, demand variation, etc., pose great difficulties to the decision-making process of the ECC.
The reinforcement learning methods, which can obtain the optimal solution to the sequential decision-making problem without explicitly constructing a complete environment model, have been widely deployed in addressing the uncertainty issue in the DSM problem [8], [9]. For instance, in [8], authors formulated the electric vehicle (EV) charging scheduling problem as a Markov decision process (MDP) and proposed a deep reinforcement learning algorithm to learn the optimal charging strategy responses to the dynamic energy price. Moreover, to tackle the incoordination issue of agents’ strategies caused by the increasing number of energy users participating in the DSM system, the multi-agent reinforcement learning method, which can obtain the joint optimal strategy of multiple agents, has gradually become a research hotspot in the DSM field [10], [11]. For instance, in [10], authors proposed an multi-agent deep deterministic policy gradient (MADDPG)-based method to decide the temperature and humidity setpoints for multi-zone buildings, which can achieve from 2.8% up to 15.4% energy saving under different thermal comfort demands.
The multi-agent reinforcement learning methods schedule the load resources of multiple energy users through the centralized information collection and training design, which effectively overcomes the partially observation issue in multi-agent environment. Nevertheless, substantial multi-agent reinforcement learning research efforts ignore the risk of privacy leakage in the centralized learning process. Some recent studies [12], [13] have shown that a malicious adversary can gain access to the private information of energy users by eavesdropping the communication, compromising smart meters, or hacking into the cloud server [14]. For instance, authors in [13] proved that utilizing a simple probability density estimation method can derive customers’ routines from the electricity consumption readings. Once the privacy of energy users is disclosed, the adversary can conduct targeted advertising for gaining profit through the inferred behavior patterns such as appliance usage and lifestyle of different households [15], even threaten the personal safety of the energy users conditioned on the inference such as consumers’ absence or presence and residential location [16].
To the best of our knowledge, there are only two works considering the privacy issues in DSM methods based on multi-agent reinforcement learning [17], [18]. In [17], authors applied the federated learning technique to enable energy users to determine the neural network parameters in a decentralized fashion without sharing private information. In [18], authors modeled the DSM problem of residential microgrid as a partially observable Markov decision process (POMDP), and employed the recurrent neural network (RNN) to enhance the feature representation of partial observation. The method did not utilize the private information such as indoor temperatures and arrival/departure times of EV in the training process.
Aforementioned privacy preserving DSM studies endow individual agent the ability of determining load control policies without obtaining the private information of other energy users. However, there still exist two significant challenges in deploying the privacy preserving DSM program for realistic residential users. First, the complete distributed training manner, which ignores valuable information of other agents in the training process, will pose significant damage to the training efficiency due to the dynamic and time-varying strategy of other agents results in the instability of training experience. Second, above privacy preserving DSM methods lack the proof of convergence property of the reinforcement learning algorithm, therefore they cannot theoretically guarantee the optimization effect of the DSM strategy. In summary, how to protect the privacy of energy users while maintaining the algorithm performance becomes the key issue of relevant field.
In this paper, we propose a multi-agent reinforcement learning algorithm based on centralized training and decentralized execution paradigm to mitigate the damage of training efficiency caused by the instability of training experience. Besides, we present an explicit privacy protection method by transforming the private information of energy user from low-dimensional to high-dimensional and theoretically prove that the proposed method will not affect the convergence property of the reinforcement learning algorithm. The main contributions of this paper are summarized as follows:
1) Novel Demand Side Management Algorithm: A novel multi-agent reinforcement learning algorithm is proposed to produce the DSM control strategy for microgrids. Specifically, the proposed method adopts the idea of centralized training and decentralized execution paradigm to improve the stability of training experience in the multi-agent environment. Moreover, an attention mechanism is proposed to endow each microgrid the ability of adaptively determining which microgrid is more noteworthy for better cooperation.
2) Explicit Privacy Protection Method: An encryptor based on a neural network with fixed parameters is presented to transform the private information of microgrid (i.e., the demand response strategy and the energy consumption demand) from low-dimensional to high-dimensional in order to protect users’ privacy. Furthermore, we theoretically prove that the proposed encryptor-based privacy preserving method will affect neither the convergence property nor the training performance of the reinforcement learning algorithm.
3) Complete Experiments With Real-World Data: Extensive simulations are performed to verify the effectiveness of the proposed method with the real-world energy consumption data of Xi’an, Shaanxi, China. Specifically, the proposed method is compared with the state-of-the-art RL methods in terms of the bill payment, satisfaction and utility. The ablation studies are conducted to prove the proposed privacy protection method will not cause performance degeneration of reinforcement learning algorithm.
The rest of this paper is organized as follows. In Section II, we briefly review the researches related. In Section III, we introduce the system model and the optimization objective of the power grid system. In Section IV, we present the POMDP model of the DSM control, the detailed description of the proposed algorithm and the privacy preserving method. In Section V, we introduce the experimental studies, and finally, we conclude our paper in Section VI. We summarize the main notations utilized in this paper in Table I.
Table
I.
Main Notations Utilized in This Paper
Notation
Explanation
di,t
Total energy consumption demand of microgrid i at time step t.
dbasei,t
Base energy demand of microgrid i at time step t.
dconi,t
Controllable energy demand of microgrid i at time step t.
et
Energy price at time step t.
pi,t
Demand side management control signal offered to microgrid i at time step t.
li,t
Actual amount of energy purchased by the microgrid i at time step t.
soci,t
Remaining battery energy of microgrid i at time step t.
δ
Transmission loss of battery.
K(⋅,⋅,⋅)
Satisfaction function.
st
State of the entire power grid environment at time step t.
oi,t, ai,t, ri,t
Observation, action, reward of microgrid i at time step t.
mi
High-dimensional state-action feature of microgrid i.
Recently, the uncertainty issue in the demand side management environment has attracted growing attention, and a large number of model-based approaches have been proposed. For instance, in [19], Erdinç et al. proposed a comfort violation minimization demand response strategy of air conditioning by forecasting the temperature set-point of thermostats to minimize the average discomfort among energy users. In [20], authors propose a stochastic day-ahead scheduling method for pool-based demand exchange environment, in which economic demand response is traded among participants. In [21], authors present a multi-class queueing system for residential demand aggregation to minimize the cost of the power consumption under day-ahead pricing. However, above model-based approaches require accurate environmental stochastic model, which may not be practical in real scenario.
Several literatures have been dedicated to tackle the direct load control problem of the power grid by applying the model-free deep reinforcement learning (DRL) algorithms. In [22], the scheduling strategies of home energy appliances are optimized by the double deep Q-learning (DDQN) algorithm, which is proved to be effective in minimizing the users’ cost compared to the traditional DQN method. Du and Li [23] propose a real-time energy management strategy of microgrid based on the monte-carlo method in order to decrease the demand-side peak-to-average ratio, and to maximize the profit from selling energy. Yu et al. [24] formulate the energy cost minimization problem of household appliances as an MDP, and propose a demand side management algorithm based on deep deterministic policy gradients (DDPG) to offer continuous action spaces control. Zhang et al. [25] propose an automated building demand response control framework and utilize the asynchronous advantage actor-critic (A3C) method to learn an optimal and cost-effective control policy.
Differently from above literatures that are devoted to solve the demand side management problem with single-agent RL methods, many researchers have applied the multi-agent RL algorithms to investigate the coordination of multiple energy users [11]. For instance, Zhang et al. [26] develop a multi-household energy management framework for residential units containing distributed energy resources (DERs) such as photovoltaic (PV), energy storage system (ESS) and controllable loads, which performs explicit collaboration to satisfy global grid constraints. Hu propose an MADDPG-based method to decide the temperature and humidity setpoints for multi-zone buildings. Besides, Yu et al. [27] formulate the energy cost minimization problem of commercial building containing heating, ventilation, and air conditioning (HVAC) systems as a Markov game and utilize the multi-agent actor-attention-critic (MAAC) method, which does not require any prior knowledge of uncertain parameters and can operate without knowing building thermal dynamics models, to optimize the HVAC control.
Differently from above research effort, in this paper, in addition to proposing a multi-agent reinforcement learning algorithm to mitigate the influence of the instable experience on the training performance, we also present an explicit privacy protection method by designing an encryptor based on the neural network with fixed parameters to transform the private information of the energy user from low-dimensional to high-dimensional and theoretically prove that the proposed method will not affect the convergence property of the reinforcement learning algorithm.
III.
Problem Formulation
In this section, we first describe the system model of the power grid considered in this paper, and then formulate the optimization objective of the demand side management system.
A
System Description
The considered power grid model is composed of a utility company, a centralized energy management system (CEMS) of high computing power and distributed microgrids equipped with energy storage system, energy consumption devices and local energy management system (LEMS) of low computing power, as shown in Fig. 1. Note that, in realistic scenarios, the LEMS deployed in the individual microgrid does not have high computing power and thus is not suitable for undertaking the strategy training task with high communication cost and training cost [28], [29]. In this paper, a CEMS is adopted to learn the demand side management strategies for all microgrids. The main components of the power grid system are described as follows.
Figure
1.
System model of the demand side management scheme.
1) Utility Company U: The utility company determines the current electricity price for all microgrids conditioned on the average demand of the entire power grid system [30].
2) Distributed Microgrids M={M1,M2,…,Mn}: Distributed microgrids report the energy consumption demand and battery information to the centralized energy management system conditioned on the status of electrical devices and equipped batteries, and then determine the demand side management strategy based on the guidance of CEMS and the partial observation. Note that, the number of microgrids is denoted as n.
3) Centralized Energy Management System CEMS: The centralized energy management system is responsible for the training process of all microgrids’ load scheduling. Note that the CEMS, which is regarded as a service provider, collects the demand and battery information from distributed microgrids and offers demand side management guidance to all microgrids with the objective of minimizing the operation cost of the entire power grid while improving each microgrid’s experience.
In this paper, the power grid operates in discrete time steps, i.e., t∈{0,1,…,T}, where T=+∞ is the infinite time horizon. According to the energy users’ preferences and consumption characteristics, the energy consumption demand di,t of microgrid i at time step t can be divided into two categories, i.e., the controllable demand (e.g., heating, ventilation, and air conditioning systems) and the base demand (e.g., television and computer)
di,t=dbasei,t+dconi,t
(1)
where, dbasei,t represents the energy that is necessary to maintain the operation of the microgrid i. Notice that, if the base demand exists, then the EMS should supply its consumption without any hesitation. In this way, the actual energy consumption of microgrid i at time step t cannot be less than dbasei,t. Moreover, dconi,t is the energy that the microgrid i can flexibly cut or increase in order to achieve the objective of demand response. The centralized energy management system first collects the joint information of all microgrids as well as the electricity price provided by the utility company, denoted as st
st={dbaset,dcont,et}
(2)
where dbaset and dcont represent the joint base demand and joint controllable demand, respectively, denoted as
Note that, in this paper, we assume that the CEMS can only observe the current state information st at time step t and is uncertain about the state information st+1 in the next time step t+1. Given the joint information st, the CEMS offers the scheduling signal to the LEMS of all microgrid. And the LEMS in turn determines the demand side management strategy conditioned on the partial observation and the guidance of CEMS. We denote the demand side management control signal of microgrid i at time step t as pi,t∈[−1,1], which represents the magnitude of extra (positive) and reduced (negative) purchased power of microgrid as a ratio of its energy consumption demand di,t.
The actual amount of energy li,t purchased by the microgrid i at time step t is described as
li,t=(1+pi,t)×di,t
(3)
in which pi,t<0 indicates that the microgrid i will cut the total energy consumption demand di,t at time step t by |pi,t|⋅di,t to reduce bill payment. pi,t>0 indicates that the microgrid i can not only fulfill its total energy consumption demand di,t at time step t, but also store extra energy by the volume pi,t⋅di,t in the battery for subsequent usage. Because the base energy consumption demand cannot be shifted or curtailed, the actual energy purchase volume at any time must be strictly greater than its base demand
(1+pi,t)×di,t>dbasei,t.
(4)
The state transition function of the microgrid i’s remaining battery energy soci from time step t to time step t+1 can be expressed as
where soci,t and soci,t+1 are respectively the remaining energy storages of microgrid i at the beginning of time step t and t+1. From (5) we can observe that, microgrid i will store the energy by the volume (1−δ)×pi,t×di,t in the battery device when the demand side management signal pi,t is no less than 0. While, when pi,t<0, the microgrid i will utilize the energy stored in the battery device to compensate the reduction of its purchased energy. δ∈(0,1) denotes the transmission loss representing the charging efficiency of batteries, which can be modeled as
δ=eNi,t10−e−Ni,t10eNi,t10+e−Ni,t10
(6)
where Ni,t is the corresponding number of charging/discharging cycles of the battery i at time step t [31], in which the transition function can be denoted as
Ni,t+1=Ni,t+|soci,t+1−soci,t|socimax
(7)
Equation (6) indicates that the charging and discharging behaviors of the battery will cause a certain degree of wear and tear, which results in the deterioration of charging efficiency. Empirically, the energy storage volume of a battery at any time step cannot exceed its maximum capacity. Thus, the soc_{i, t} at all time steps must comply with the following inequality:
where soc^{\max}_{i} is the maximum capacity of the energy storage devices for the microgrid i.
In summary, according to (5) as well as (4) and (8), the overall constraint for the demand side management control signal p_{i, t} of microgrid i at time step t can be presented as
The former part of (9) indicates that the demand side management control signal should ensure that the energy consumption at the current time step is higher than the base demand. Moreover, the latter part of (9) represents that the demand side management control signal should ensure that the remaining energy of the battery is lower than the maximum volume while ensuring p_{i, t} \leq 1 .
B
Optimization Objective
The objective of the entire power grid system is to adjust the consumption patterns of all microgrids to cope with dynamic energy prices, so as to minimize the energy purchase cost while improving the energy users’ experience from a social perspective. We utilize r^{b}_{i, t} to represent the bill payment of microgrid i at time step t and denote the satisfaction of microgrid i at time step t as r^{d}_{i, t} .
Specifically, the bill payment of microgrid i at time step t is denoted as
where -e_{t} \times d_{i, t} denotes the cost to fully satisfy the energy consumption demand of microgrid i. (1 + p_{i, t}) is the percentage of the actual purchased energy compared to the total energy consumption demand.
Notice that, when the actual energy consumption volume of microgrid i at time step t is less than its energy consumption demand, the required energy of microgrid i cannot be satisfied, which results in the bad experience. To characterize above experience of microgrids, we define the satisfaction of microgrid i at time step t as
where {\cal{K}}(\cdot, \cdot, \cdot) is the satisfaction function which is affected by the purchased energy, energy consumption demand and battery status of microgrid i at time step t. The satisfaction function is defined as follows:
where \rho_{i} and \varrho_{i} are microgrid-dependent satisfaction coefficients. \sigma_{i, t} = d_{i, t} - l_{i, t} - soc_{i, t} denotes the demand reduction of actual energy consumption compared to the energy consumption demand. The quadratic term \sigma_{i, t}^{2} in (12) indicates that a larger demand reduction \sigma_{i, t} results in a higher dissatisfaction level of microgrid i.
In summary, the overall objective of the demand side management system can be formulated as a constrained optimization problem, denoted as
The first term of the objective function (13) represents the sum of all microgirds’ bill payment at all time steps which should be minimized and the second term of the objective function (13) indicates that the total satisfaction of all microgirds’ at all time steps which should be maximized. The constrains (14)−(17) are utilized to ensure that the demand side management control signal of each microgrid p_{i, t} is within a reasonable range.
Note that, the energy consumption behavior as well as the energy price are unpredictable in the optimization problem (13). Thus, it is difficult to solve the optimization problem (13) via traditional optimization methods (e.g., Lyapunov optimization [32] and robust optimization [33]). This paper adopts an RL-based approach which can adaptively learn the optimal policy through the interaction between the agent and environment without requiring the exact system model.
IV.
Privacy Preserving MARL Method
In this section, the design motivation of privacy preserving demand side management strategy is first presented. Then, the demand side management problem is modeled as a decentralized partially observable Markov decision process (Dec-POMDP) [34] with infinite time horizon. And finally, a privacy preserving multi-agent reinforcement learning method is introduced to optimize the joint policy of all microgrids and to protect the private information of distributed microgrids.
A
Motivation of Privacy Preserving MARL Method
Recently, reinforcement learning (RL) technique [35] has been proven to be quite effective in addressing the sequential decision-making problem intractable to human being. Although several RL algorithms (e.g., deep Q learning (DQN) [36] and deep deterministic policy gradient (DDPG) [37]) have been employed in addressing the demand side measurement problem, they all ignore the fact that as the number of energy users participating in the power grid continues to increase, the demand side management strategy of individual agent is greatly affected by the dynamic strategies of other agents. Multi-agent reinforcement learning methods can learn a joint optimal strategy for all agents through centralized training paradigm, however, the private information (e.g., energy consumption demand and demand response strategy) of energy users will be exposed to extremely serious threats in the process of information transmission [38]. The energy consumption demand could potentially reveal the consumers’ personal daily behavior or habits, e.g., cooking time and frequency of going to the bathroom at night [12]. Therefore, once the privacy of energy users is disclosed, the adversary can conduct targeted advertising for gaining profit, even threaten the personal safety of energy users by monitoring the energy consumption information [1]. Thus, there is a need to retain the benefits of multi-agent coordination while ensuring that the private information is kept private.
In order to address the issue of dynamic strategies in the multi-microgrid demand side management model, we propose a novel multi-agent reinforcement learning scheme for demand side management problem based on the centralized training decentralized execution paradigm [39]. The proposed method greatly improves the stability of training experience in multi-agent environment. Furthermore, in order to protect energy users’ privacy in the centralized training process, we design an explicit encryptor to transform the energy consumption information and demand response strategy of microgrids from low-dimensional to high-dimensional. The proposed privacy protection method can effectively preserve the sensitive information of energy users while maintaining the algorithm performance.
B
Dec-POMDP Model
Due to the privacy concerns, obtaining the global information of the entire power grid system for the centralized demand side management strategy is sometimes impractical in realistic scenarios. In other words, the microgrids are unwilling to disclose all their operation conditions, which generally contain the private information, to other agents. To address above issue, the demand side management problem considered in this paper is formulated as a Dec-POMDP, which can be described as a six-element tuple [{\cal{N}}, {\cal{S}}, {\cal{O}}, {\cal{A}}, {\cal{P}}, {\cal{R}}] where {\cal{N}} = [1,2, \dots, n] is the set of agents. At each time step t, an agent i obtains an observation o_{i, t}\in{\boldsymbol{s}}_{t} from the observation space {\cal{O}} , which is a subset of the state space {\cal{S}} , i.e., {\cal{O}} \subset {\cal{S}} , then the agent i chooses an action a_{i, t} from the action space {\cal{A}} to interact with the environment conditioned on a certain policy a_{i, t} = \pi_{i}(o_{i, t}) . The environment responds a vector reward to the joint action of microgrids {\boldsymbol{a}}_{t} = \{a_{1, t}, \dots, a_{n, t}\} by the reward function {\cal{R}} , denoted as
and steps into the next state {\boldsymbol{s}}_{t+1} by the transition function {\cal{P}}({\boldsymbol{s}}_{t}, {\boldsymbol{a}}_{t}) . Note that, due to the complexity of obtaining the realistic grid system model, both the reward function {\cal{R}} and the transition function {\cal{P}} are unknown as a prior to agents. The description of the Dec-POMDP formulation is defined as follows:
1) Agents {\cal{N}} : Each microgrid is considered as an agent and the number of agents is denoted as n.
2) State Space {\cal{S}} : The state of the entire power grid environment at time step t is denoted as {\boldsymbol{s}}_{t} = \{{\boldsymbol{d}}^{\rm{base}}_{t}, {\boldsymbol{d}}^{\rm{con}}_{t}, e_{t}, {\boldsymbol{soc}}_{t} \} , where {\boldsymbol{d}}^{\rm{base}}_{t} , {\boldsymbol{d}}^{\rm{con}}_{t} and {\boldsymbol{soc}}_{t} represent the joint base demand, the joint controllable demand and the joint battery information at time step t, respectively. e_{t} denotes the energy price provided by the utility company at time step t.
3) Observation Space {\cal{O}} : We adopt the assumption that the state of environment is partial observable for each microgrid and formulate the observation of microgrid i at time step t as: o_{t} = \{d^{\rm{base}}_{i, t}, d^{\rm{con}}_{i, t}, soc_{i, t}\} .
4) Action Space {\cal{A}} : The action of microgrid i at time step t is designed as the demand side management control signal, i.e., a_{i, t} = p_{i, t} . Note that, a_{i, t} \in [-1, 1] and a_{i, t} < 0 indicates that the microgrid i will reduce the energy purchased volume at time step t while a_{i, t} > 0 indicates that the microgrid will purchase the energy beyond its demand for the subsequent usage.
5) Transition Function {\cal{P}} : The transition function is a mapping from the state {\boldsymbol{s}}_{t} at time step t to the next state {\boldsymbol{s}}_{t+1} at time step t+1 when the environment receives the joint action of all agents: {\boldsymbol{s}}_{t+1} = {\cal{P}}({\boldsymbol{s}}_{t}, {\boldsymbol{a}}_{t}) .
6) Reward Function {\cal{R}} : The objective of the entire power grid system is to minimize the energy purchase cost of all microgrid while improving the energy users’ experience. Thus, the immediate reward of microgrid i at time step t is denoted as
where \gamma \in (0, 1] represents the discount factor. The objective of all microgrids is to develop a joint policy {\boldsymbol{\pi}}^{\ast} = [\pi^{\ast}_{1}, \pi^{\ast}_{2}, \dots, \pi^{\ast}_{n}] that can maximize the cumulative rewards of all microgrids in the entire power grid system.
C
Solution via Privacy Preserving MARL Method
The overall structure of the proposed MARL method is illustrated in Fig. 2 which mainly includes three ingredients: 1) The actor network \pi(\cdot) , deployed in the local EMS of individual microgrid, is utilized to generate the action conditioned on the partial observation of each microgrid; 2) The critic network Q(\cdot, \cdot) , deployed in the centralized EMS, is utilized to estimate the value function which represents the cumulative reward obtained by performing a certain action in a certain state; 3) The encryptor Enc(\cdot, \cdot) is utilized to transform the private information of microgrids from low-dimensional to high-dimensional in order to protect users’ privacy. The workflow of the proposed method is described as follows.
Figure
2.
The structure of proposed method, including 1) Actor networks for decentralized execution; 2) Critic networks for centralized training; 3) Encryptors to transform the private information of microgrids from low-dimensional to high-dimensional.
1) Decentralized Execution: In this paper, we adopt a practical execution structure that each microgrid can only get access to its partial information, i.e., the microgrid i can only obtain its base demand d^{\rm{base}}_{i, t} , controllable demand d^{\rm{con}}_{i, t} and remaining battery energy soc_{i, t} rather than the global state information s_{t} of the entire power grid system. At each time step t, each microgrid obtains an observation o_{t} = \{d^{\rm{base}}_{i, t}, d^{{\rm{con}}}_{i, t}, soc_{i, t}\} from the environment and responds an action a_{i, t} by the actor network a_{i, t} = \pi^{\mu_{i}}_{i}(o_{i, t}) . The actor network is a multi-layer perceptron (MLP) [40] with \mu_{i} being the parameters.
Balancing the exploration and exploitation is necessary for the reinforcement learning algorithm in the action selection process, which effectively prevents the agent from falling into sub-optimal strategies [41]. To encourage agents’ effective exploration, we add a random Gaussian noise {\cal{N}}(0, I) to the output layer of the actor network and the executed action can be denoted as
where α is negatively correlated to the training episodes, i.e., \alpha = \frac{1}{ep} where ep is the number of current training episodes. The reason behind above setting is that, at the beginning of training, the agent should explore the environment more frequently since the knowledge about the environment is insufficient. As the training continues, the agent will have enough experience about the environment and the added noise should be gradually reduced. The function clip(\cdot, \cdot, \cdot) is utilized to ensure that the executed action is between \frac{d^{\rm{base}}_{i, t} - d_{i, t}}{d_{i, t}} and \min(\frac{soc_{i}^{\max} - soc_{i, t}}{d_{i, t} \times (1 - \delta)}, 1), which ensures the satisfaction of (4) representing that the actual energy consumption is no less than the base demand at all time steps and ensures the satisfaction of (8) indicating that the energy storage at a time step cannot exceed its maximum capacity.
After all agents have finished the action selection process, the environment will respond a vector reward {\boldsymbol{r}}_{t} = \{r_{1, t}, \dots, r_{n, t}\} to the joint action of agents {\boldsymbol{a}}_{t} = \{a_{1, t}, \dots, a_{n, t}\} and step into the next state s_{t+1} , in which agents can obtain the next joint observation {\boldsymbol{o}}_{t+1} . Finally, the interaction experience denoted as ({\boldsymbol{o}}_{t}, {\boldsymbol{a}}_{t}, {\boldsymbol{r}}_{t}, {\boldsymbol{o}}_{t+1}) is stored in the replay buffer B which keeps the property of independently identically distribution (I.I.D.) of training samples [42].
2) Privacy Preserving Method: In the proposed demand side management system, users’ demand response strategy and energy consumption demand (including the base demand and the controllable demand) are the most important privacy information. Once above private information of the energy users is disclosed, the privacy of energy users will be exposed to extremely serious threats. For instance, energy consumption demand and the demand response strategy may reveal the number of electricity users, energy users’ hobby or health status. Once a malicious adversary obtains such information, he/she can conduct targeted advertising for gaining profit, even threaten the personal safety of the energy users conditioned on their energy consumption habits. Thus, the privacy of users’ demand response strategy and energy consumption demand need to be well preserved in the demand side management system.
In this paper, we design a neural network with fixed parameters as the encryptor to protect the privacy of energy users. The structure of the proposed encryptor is illustrated in Fig. 3. The encryptor i is utilized to transform the low-dimensional observation o_{i} (contains the energy consumption demand) and action a_{i} (contains the demand response strategy) of the microgrid i to the high-dimensional feature m_{i} , denoted as
where {\boldsymbol{\omega}}_{i} = \{\omega_{i, 1}, \dots, \omega_{i, v}\} is the joint parameter of the encryptor i, in which v is the total number of layers of the neural network. [\omega_{i, k}| k \in [1, v]] denotes the parameter of k-th layer in the neural network.
It is worth mentioning that, during the entire training process, we fix the parameters of each microgrid’s encryptor {\boldsymbol{\omega}}_{i} , ensuring that the same observation-action input can obtain the same output, i.e.,
Theorem 1: Equation (23) ensures that the transformation from low-dimensional to high-dimensional will not affect the convergence property of the reinforcement learning algorithm.
Proof: According to [43] the value function Q(o, a) satisfies the Bellman equation, described as follows:
\begin{equation} Q_{\pi}(o, a) = r + \gamma \sum\limits_{o' \in {\cal{O}}} {\cal{P}}^{a}_{o, o'} \sum\limits_{a' \in {\cal{A}}}\pi(a'|o')Q_{\pi}(o', a') \end{equation}
(24)
where {\cal{P}}^{a}_{o, o'} is the probability that the observation transitioned from o to o' conditioned on the action a. Due to the fact that observation o and action a are encrypted as the high-dimensional feature, the original Bellman equation can be rewritten as
Due to the fact that this paper considers the deterministic reward function and the transition function of the environment, (25) will be true if the encryption function Enc(\cdot, \cdot) of the same observation-action input can obtain the same output during the entire training process. At the same time, because we fix the parameters of the encryptor in the entire training process, (25) will always hold.
Lemma 1: For each state-action pair of any Markov decision process, there always exists an optimal policy \pi^{\star} that can maximize the value function denoted as follows:
where Q_{\star}(Enc(o, a| {\boldsymbol{\omega}})) is the optimal value function.
The proof of Lemma 1 can be found in [43]. Lemma 1 denotes that the value function derived from the optimal policy \pi^{\star} is better than that from any policy π
Under this circumstance, as long as the agent takes the action following the optimal policy, the value function will be greater than or equal to the value function obtained from the previous non-optimal policy. According to (28), the way to select the action conditioned on the optimal policy is denoted as follows:
According to [44], the policy gradient method of (32) can ensure that each update can make the existing policy not inferior to the original policy, which theoretically guarantees the convergence of the algorithm.■
Theorem 1 assures that the proposed encryptor-based privacy preserving method will not affect the training performance of the reinforcement learning algorithm. Moreover, the parameters of each microgrid’s encryptor {\boldsymbol{\omega}}_{i} are kept secret to other participants of the demand side management system. Under this circumstance, even if a malicious adversary can obtain the m_{i} provided by the microgrid, it is impossible for him/her to infer the true demand response strategy and energy consumption demand of energy users from the high-dimensional feature, which effectively preserves the privacy of energy users’ sensitive information.
3) Policy Learning: In the proposed MARL method, we adopt the centralized training framework, i.e., each microgrid shares the encrypted information of the taken action and the observation with others. The individual microgrid utilizes the critic network to evaluate the cumulative reward that can be obtained by performing a certain action in a certain state. The critic network of microgrid i, parameterized by \theta_{i} , will utilize the encrypted feature shared by other agents as well as its individual observation and action to learn a centralized state-action value Q^{\theta_{i}}_{i}(o_{i}, a_{i}, {\boldsymbol{m}}_{-i}) , where {\boldsymbol{m}}_{-i} is the joint message received by agent i, denoted as
The objective of the demand side management system is to maximize the overall profits through effective cooperation of all microgrids in the entire power grid system. Under above circumstance, the energy consumption demand and the corresponding demand response strategy of different microgrids will have different impacts on the value function formulation of a certain microgrid. Thus, in the process of representing the value function using the critic network, we adopt the idea of attention mechanism [45] to endow each microgrid the capability of adaptively determining which microgrid is more noteworthy. The structure of proposed attention-based critic network is illustrated in Fig. 4.
Figure
4.
The structure of proposed attention-based critic network.
As shown in Fig. 4, an original value function {\boldsymbol{Q}}'_{i} \in \mathbb{R}^{n-1} = [Q_{i,1}, \dots, Q_{i,i-1}, Q_{i,i+1}, \dots, Q_{i,n}] can be obtained after the inputs o_{i} and a_{i} are propagating through an MLP. Then, we input the joint message {\boldsymbol{m}}_{-i} received by agent i into the MLP suffixed by a softmax layer to generate the adjustment coefficients {\boldsymbol{c}} \in \mathbb{R}^{n-1} = [c_{1}, \dots, c_{i-1}, c_{i+1}, \dots, c_{n}] of the original value function {\boldsymbol{Q}}'_{i} . And finally, the value function of microgrid i can be calculated by taking an inner-product of the adjustment coefficients with the original value function
Further, the parameters of actor network \pi^{\mu_{i}}_{i} of microgrid i are updated through maximizing the cumulative reward utilizing the gradient by a random mini-batch sampled from the replay buffer B, denoted as
7: Execute actions to obtain the reward r_{i, t} and next observation o_{i, t} for each microgrid.
8: end while
9: Calculate the evaluation metrics (i.e., the bill payment, the satisfaction and the utility of microgrids).
We summarized the proposed MARL method for learning the demand side management control strategy in Algorithm 1, which is named as the attention-based multi-agent deep deterministic policy gradient (AB-MADDPG). During the training process, each microgrid first perceives the observation, selects the action and transforms the private information from low-dimensional to high-dimensional, as given in Lines 4−7. Then, all microgrids execute the actions to interact with the environment and store the joint experience in the replay buffer, as given in Lines 9 and 10. Finally, each microgird receives the joint encrypted message provided by others and updates the actor network, critic network, target actor network and target critic network, as given in Lines 11−16.
During the testing process, only the actor networks are deployed to generate the control signals for each microgrid. The procedure of demand side management control strategy is outlined in Algorithm 2, in which each microgrid utilizes the trained actor network to produce the demand side management signals conditioned on the partial observation, as given in Lines 3−5. In Line 7, the environment provides the reward to each microgrid and steps into the next time step. Moreover, in Line 9, the evaluation metrics including the bill payment, the satisfaction and the utility of microgrids (which will be introduced in Section V-A-3) are calculated to demonstrate the effectiveness of the proposed method.
V.
Performance Evaluation
In this section, the experimental setup is first presented. Then, the effectiveness of the proposed method is verified through intuitive demand side management results. Next, the performance of the proposed AB-MADDPG algorithm is compared with those of other widely utilized RL methods in terms of the bill payment, the satisfaction and the utility. After that, the proposed privacy preserving method is proven to protect users’ privacy without compromising the performance through the comparison between the proposed privacy preserving algorithm with the algorithm without privacy protection. Finally, the ablation studies are conducted to analyze the impact of hyperparameters on the algorithm performance.
A
Experimental Setup
1) Dataset and Parameters: We build a simulation environment that emulates the actual demand side management of microgrids in a region of Xi’an, Shaanxi, China. In the proposed simulation environment, 12 microgrids (including shopping mail, hotel, college, factory and residential area) need to determine whether to reduce the energy consumption volume or to purchase excess energy for the subsequent usage conditioned on the energy demand as well as the battery information. The objective of each microgrid is to minimize the operation cost while improving its satisfaction of energy consumption. We set the minimum time interval to 1 h and define the unit of energy consumption as 100 kWh. The training data of each microgrid’s energy consumption demand at each time step are sampled from a Gaussian distribution based on the statistical results of the actual electricity consumption data of Xi’an, Shaanxi, China in 2014, as presented in Table II. The testing data are the energy consumption data with the time scale of one hour in the same microgrids for 2000 hours in 2015, as presented in Fig. 5. The base demand of the microgrid i at time step t is modeled as \xi \times d_{i, t} where d_{i, t} is the energy consumption demand and ξ is randomly sampled from the uniform distribution [0.1, 0.3] with the interval 0.001. The controllable demand is modeled as (1-\xi) \times d_{i, t} . The satisfaction coefficients of each microgrid \rho_{i} and \varrho_{i} are sampled from the uniform distribution [0.1, 0.2] with the interval 0.01. We set the maximum capacity of the battery soc^{\max} to 500 units. Moreover, the pricing scheme of the utility company is denoted as
Table
II.
The Distribution Of Energy Consumption Demand in One Hour for Each Microgrid in 20141
where \overline {{d_t}} = \frac{1}{n}\sum\nolimits_{i = 1}^n {{d_{i,t}}} is the average demand of all microgrids and n is the number of microgrids in the power grid system. The unit of energy price is defined as 100 yuan/unit energy consumption. The reason behind above setting is that the utility company needs to change the inherent behavior of energy users through price incentives to achieve the objective of peak-load-shifting. And the most intuitive way is to raise the energy price when the total energy consumption demand is high, and reduce the energy price when the total energy consumption demand is low.
The implementation details of the proposed AB-MADDPG method are summarized in Table III. Specifically, we train the algorithm 2\times10^{5} episodes and freeze the training process to evaluate the performance every 1\times10^{3} episodes. The evaluation process is carried out 10 times with 2\times10^{3} episodes. The parameters τ, γ, α, the size of replay buffer and the size of mini-batch are set to 1\times10^{-2} , 0.95, 1\times10^{-3} , 5\times10^{4} and 128, respectively.
Table
III.
Parameter Settings of the AB-MADDPG Method
2) Benchmarks: We compare the performance of the AB-MADDPG method with four widely used RL benchmarks and two learning methods which draw on the idea of typical optimization algorithms to evaluate the effectiveness. The benchmarks are briefly introduced as follows:
a) Independent deep Q network (IDQN) [36] is a value-based and single-agent RL method which utilizes the deep neural network to estimate the value function for each discrete action instead of the traditional look-up table. In order to deploy the DQN in the demand side management scenario, the discrete action is modeled as [-1, -0.9, \dots, 0, \dots, 0.9, 1] . Note that, the DQN follows a distributed training paradigm that each microgrid determines the demand side management strategies conditioned on the partial observations without coordinating with each other.
b) Independent deep deterministic policy gradients (IDDPG) [37] is a policy-based and single-agent RL method which utilizes the actor network to select the action and uses the critic network to estimate the value function. Since the critic network can output the continuous action, there is no need to discretize the action like the DQN method. The DDPG also follows a distributed training paradigm that does not require a centralized EMS to schedule multiple microgrids.
c) QMIX [46] is a value-based and multi-agent RL method which factors the joint value function into a monotonic combination of agents’ individual value function. It utilizes a mixing network with non-negative weights to combine the individual value function for ensuring the monotonicity of the joint value function and individual value functions.
d) MADDPG [39] is a policy-based and multi-agent RL method which utilizes the actor network to interact with the environment and trains the critic with the global information.
e) Greedy method [47] is a learning-based method which draws on the idea of the robust optimization, denoted as Greedy. At each time step t, each microgrid only cares about obtaining the maximum reward at current time step, and ignores the future reward.
f) Model-based DDPG method [48] is a learning-based method which draws on the idea of the model predictive control, denoted as DDPG-AE. Differently from the typical DDPG method, this method contains an auto-encoder (AE) to reconstruct the original observation from the observation feature, which enhances the capability of feature extraction.
3) Metrics: The following three metrics are utilized to evaluate the performance of the demand side management strategy.
a) Bill payment: Bill payment bp is the average expense of all microgrids for purchasing the energy in the entire evaluation process, which is denoted as
\begin{equation} bp = \frac{1}{n \times E_{{\rm{test}}}} \sum\limits_{i=1}^{n}\sum\limits_{t=1}^{E_{{\rm{test}}}} -r_{i, t}^{b}. \end{equation}
(38)
b) Satisfaction: Satisfaction sa is derived from the situation that the purchased energy is sufficient for user’s energy consumption demand. sa is calculated by the average satisfaction reward in the entire evaluation process, denoted as follows:
\begin{equation} sa = \frac{1}{n \times e_{{\rm{test}}}} \sum\limits_{i=1}^{n}\sum\limits_{t=1}^{e_{{\rm{test}}}} r_{i, t}^{d}. \end{equation}
(39)
c) Utility: Utility u is the average reward of all microgrids in the entire evaluation process which reflects the training performance of the algorithm, denoted as
The experimental results will answer the following questions:
Can the AB-MADDPG method help microgrids cut the energy consumption at time steps with higher energy prices and purchase extra energy at time steps with lower energy prices? The answer of this question will prove that the proposed method will achieve good demand side management performance.
Can the AB-MADDPG method achieve lower bill payment and higher satisfaction compared with the state-of-the-art RL-based methods? The answer of this question will clarify the effectiveness of the proposed method in the demand side management scenario.
Can the AB-MADDPG algorithm achieve similar performance compared with the AB-MADDPG algorithm without privacy protection? The answer of this question will clarify that the proposed privacy preserving method can mitigate the damage caused by the privacy leakage while ensuring the algorithm performance.
How do the system parameter ξ and the algorithm parameter γ affect the performance of the proposed AB-MADDPG method?
1) Demand Side Management Results: The intuitive demand side management results of the proposed method are presented in Figs. 6 and 7. Fig. 6 shows the energy consumption demand as well as the actual energy purchase of Shopping mall II, Hotel I, and College II at each time step with different energy prices for 72 hours. Fig. 7 illustrates the energy consumption demand as well as the actual energy consumption of Shopping mall II, Hotel I, and College II at each time step for 72 hours.
Figure
6.
The energy consumption demand as well as the actual energy purchase of (a) Shopping mall II, (b) Hotel I, and (c) College II at each time step with different energy price for 72 hours. Red lines represent dynamic energy prices.
Figure
7.
The energy consumption demand as well as the actual energy consumption of (a) Shopping mall II, (b) Hotel I, and (c) College II at each time step for 72 hours.
From Fig. 6 we can see that, after the training finished, all three microgrids have learned the ability of purchasing extra energy at the time step with lower energy prices (e.g., e_{t} = 1.5 ) and cutting the energy consumption demand at the time step with higher energy prices (e.g., e_{t} = 4.0 ). From Fig. 7 we can see that, with the help of equipped battery devises, although microgrids will cut the energy consumption at the time step with higher energy prices, the actual energy consumption is almost equal to the energy consumption demand. Simulation results can answer the first question raised at the beginning of this subsection, i.e., the proposed demand side management method can help microgrids meet their demand for energy consumption while endowing them the capability of cutting the energy purchase during peak energy price periods and buying extra energy during valley energy price periods.
2) Reducing Users’ Payment and Discomfort: The average bill payment, satisfaction and utility of all microgrids for the AB-MADDPG method as well as four RL-based benchmarks are presented in Fig. 8, in which solid lines and shaded areas illustrate the mean and standard deviation of three metrics, respectively. In order to make the results more intuitive, the average simulation result and its deviations under different algorithms of the last 10 evaluation episodes are listed in Table IV. From Fig. 8 and Table IV we can see that, the proposed AB-MADDPG method achieves the lowest bill payment, nearly the highest satisfaction and the highest utility compared with four widely utilized RL-based methods. Specifically, the average bill payment of the AB-MADDPG method reduces to about 31.2 after 2 \times 10^{5} training episodes, lower than the MADDPG method, the IDDPG method, the IDQN method and the QMIX method by about 97.9 \% , 63.8 \% , 49.7 \% and 89.0 \% , respectively. The satisfaction of the AB-MADDPG method reaches about −0.04 after 1 \times 10^{5} training episodes, higher than the MADDPG method, the IDQN method and the QMIX method by about 97.9 \% , 100.0 \% and 99.9 \% , respectively. And the satisfaction obtained by the IDDPG method is similar to that by the AB-MADDPG method. Moreover, the utility of the AB-MADDPG method reaches −31.2 at the end of training, higher than the MADDPG method, the IDDPG method, the IDQN method and the QMIX method by about 49.0 \% , 63.9 \% , 98.4 \% and 90.2 \% , respectively. Simulation results can sufficiently answer the second question raised at the beginning of this subsection, i.e., the proposed AB-MADDPG method can obtain better algorithm performance compared with four state-of-the-art RL-based methods in the demand side management scenario.
Figure
8.
Average (a) bill payment, (b) satisfaction, and (c) utility obtained by the AB-MADDPG algorithm (red), the MADDPG algorithm (blue), the IDDPG algorithm (green), the IDQN algorithm (purple), the QMIX algorithm (orange), the Greedy algorithm (yellow) and the AE-DDPG algorithm (cyan) under 10 different random seeds. The solid lines and shaded regions show the mean and standard deviation over ten runs, respectively.
Table
IV.
The Mean and Deviations of the Bill Payment, the Satisfaction as Well as the Utility for Seven Different Algorithms in the Last 10 Evaluation Episodes. All Methods are Run Ten Times With Different Random Seeds
The reason behind the better performance of policy-based MARL algorithms (i.e., the AB-MADDPG method and the MADDPG method) than single-agent RL algorithms (i.e., the DDPG method and the DQN method) is that the centralized training and decentralized execution paradigm can effectively address the issue of unstable training experience caused by the dynamic environment and agents’ constantly changing strategies in the multi-agent setting. Since the QMIX method utilizes the team reward to improve the performance of all agents and can not endow each agent the ability of utilizing heterogeneous rewards for strategy learning, it achieves the lower algorithm performance compared with the methods which can endow each agent the ability of perceiving the individual reward (e.g., the AB-MADDPG method, the MADDPG method and the DDPG method). Due to the fact that the proposed attention mechanism can let each microgrid adaptively determine which microgrid is more noteworthy, the AB-MADDPG method can achieve better cooperation performance (i.e., obtains lower bill payment, higher satisfaction and utility) compared with the MADDPG method in the multi-agent demand side management environment.
Besides, in order to further illustrate the effectiveness of the proposed method, we compare the proposed method with two learning-based methods which draw on the idea of typical optimization algorithms (i.e., the Greedy method and the AE-DDPG method). Simulation results are provided in Fig. 8 and Table IV. Fig. 8 and Table IV show that the proposed AB-MADDPG method achieves the lowest bill payment, the highest satisfaction and the highest utility compared with the Greedy method and the Model-based DDPG method. Specifically, the average bill payment of the AB-MADDPG method is lower than those of the Greedy method and the AE-DDPG method by 88.4% and 75.0%, respectively. The satisfaction of the AB-MADDPG method is higher than those of the Greedy method and the AE-DDPG method by 99.98% and 99.99%, respectively. And the utility obtained by the AB-MADDPG method is higher than those of the Greedy method and the AE-DDPG method by 92.3% and 92.1%, respectively. Simulation results prove that the proposed AB-MADDPG method is more effective than the learning-based methods that draw on the idea of typical optimization algorithms in the demand side management scenarios.
3) Performance of Privacy Preserving: We compare the proposed AB-MADDPG algorithm and the AB-MADDPG algorithm without privacy protection (denoted as AB-MADDPG-WP) to prove that the proposed encryptor-based privacy preserving method will not affect the training performance of the algorithm. Simulation results are illustrated in Fig. 9 and Table V. Results in Fig. 9 and Table V show that the proposed AB-MADDPG method can achieve similar demand side management performance compared to the AB-MADDPG-WP method. Specifically, the average bill payment of the AB-MADDPG method at the end of training is only 4.7 \% higher than that of the AB-MADDPG-WP method. The average satisfaction of the AB-MADDPG method after 1 \times 10^{5} training episodes is only lower than that of the AB-MADDPG-WP method by 0.02. Besides, the utility of the AB-MADDPG method after 1 \times 10^{5} training episodes is only lower than that of the AB-MADDPG-WP method by about 4.3 \% . The results can clearly answer the third question raised at the beginning of this section, i.e., the proposed encryptor-based privacy preserving method can effectively mitigate the damage caused by the privacy leakage while ensuring the algorithm performance.
Figure
9.
Average (a) bill payment, (b) satisfaction, and (c) utility obtained by the AB-MADDPG algorithm (red), the AB-MADDPG-WP algorithm (navy). The solid lines and shaded regions show the mean and standard deviation over ten runs, respectively.
Table
V.
The Mean and Deviations of the Bill Payment, the Satisfaction as Well as the Utility for the AB-MADDPG Algorithm and the AB-MADDPG-WP Algorithm in the Last 10 Evaluation Episodes
The reason behind simulation results is that transforming the private information of microgrids from low-dimensional to high-dimensional by the neural network with fixed parameters can ensure that the same state-action input can produce the same output and thus will not affect the stability of the training experience according to Theorem 1. Because the neural network can effectively extract features from both high-dimensional and low-dimensional data, the AB-MADDPG method can achieve the similar performance compared to the AB-MADDPG without the encryptor-based privacy protection method.
4) Ablation Study: In order to answer the fourth problem at the beginning of this section, the impact of maximum base demand ratio ξ on the algorithm performance is analyzed. Specifically, the maximum base demand ratio ξ is changed using the values from the set [0.2, 0.3, \dots, 0.9] . Simulation results are illustrated in Fig. 10, in which the symbols and error bars show the mean and standard deviation over ten runs, respectively. As shown in Fig. 10, the bill payment of microgrids obtained by the AB-MADDPG method under low maximum base demand ratio ξ (e.g., \xi=0.2, 0.3, 0.4 ) is lower than that under high maximum base demand ratio (e.g., \xi=0.5, 0.6, 0.7, 0.8, 0.9 ). The satisfaction of microgrids obtained by the AB-MADDPG method is not sensitive to the value of maximum base demand ratio ξ. And the utility of microgrids obtained by the AB-MADDPG method under low maximum base demand ratio ξ is higher than that under high maximum base demand ratio. The reason behind the experimental results is that smaller ξ will endow microgrids higher flexibility to cut/improve the energy consumption demand according to d_{i, t}^{\rm{con}} = (1-\xi) \times d_{i, t} , thus, the AB-MADDPG method with smaller ξ can achieve higher demand side management performance.
Figure
10.
The mean (a) bill payment, (b) satisfaction, and (c) utility obtained by the AB-MADDPG algorithm under different maximum ξ in the last 10 evaluation episodes. The symbols and error bars show the mean and standard deviation over ten runs, respectively.
Besides, we investigate the performance of the AB-MADDPG method at different values of discount factor γ. Each γ in the collection [0, 0.1, \dots, 1] is tested for ten times with different random seeds. Simulation results are illustrated in Fig. 11 which demonstrates an obvious impact of γ on the algorithm performance. As the value of γ increases, the bill payment of microgrids will decrease and the satisfaction and the utility of microgrids will increase. The main reason behind the experimental results is that higher γ means the more attention is paid to future rewards according to (20), as a consequence, the algorithm will obtain higher cumulative rewards.
Figure
11.
The mean (a) bill payment, (b) satisfaction, and (c) utility obtained by the AB-MADDPG algorithm under different γ in the last 10 evaluation episodes.
In this paper, the demand side management problem of distributed microgrids is formulated as a decentralized partially observable Markov decision process. And a novel multi-agent reinforcement learning algorithm (i.e., AB-MADDPG), which adopts the centralized training and decentralized execution paradigm, is proposed to produce the demand side management control strategies for each microgrid. Moreover, we design a neural network with fixed parameters as an encryptor to transform the energy users’ sensitive information from low-dimensional to high-dimensional for protecting the private information of microgrids. We utilize an attention mechanism to let each agent adaptively determine which agents are more noteworthy for better cooperation. We verified the effectiveness of the proposed demand side management scheme by the real-world energy consumption data of Xi’an, Shaanxi, China. Simulation results show that the proposed AB-MADDPG method achieves better demand side management performance in improving users’ satisfaction and reducing users’ the bill payment compared with state-of-the-art reinforcement learning methods. The results also prove that the proposed privacy protection scheme can protect users’ privacy while ensuring the performance of the algorithm.
The proposed encryptor-based privacy protection method is suitable for the scenarios where energy users transmit private data directly. In the future work, motivated by the idea of federated learning methods [49], we will further investigate the transmission method of parameters between the centralized network (server) and distributed networks (clients) in the scenarios where energy users transmit network parameters instead of private data to achieve the effect of privacy protection. The advantage behind above design is that, on the one hand, the size of private data is generally larger than the size of model parameters, and thus the method of federated learning can effectively reduce the communication cost. On the other hand, since there is no need to transmit the private data directly, federated learning can also achieve an effective privacy protection.
11 The data were provided by the State Grid Xi’an Electric Power Supply Company, Xi’an, Shaanxi, China.
D. Li, Q. Yang, W. Yu, D. An, Y. Zhang, and W. Zhao, “Towards differential privacy-based online double auction for smart grid,” IEEE Trans. Information Forensics and Security, vol. 15, pp. 971–986, 2020. doi: 10.1109/TIFS.2019.2932911
[2]
V. C. Gungor, D. Sahin, T. Kocak, S. Ergut, C. Buccella, C. Cecati, and G. Hancke, “Smart grid technologies: Communication technologies and standards,” IEEE Trans. Industrial Informatics, vol. 7, no. 4, pp. 529–539, 2011. doi: 10.1109/TII.2011.2166794
[3]
P. Palensky and D. Dietrich, “Demand side management: Demand response, intelligent energy systems, and smart loads,” IEEE Trans. Industrial Informatics, vol. 7, no. 3, pp. 381–388, 2011. doi: 10.1109/TII.2011.2158841
[4]
Z. Zhao, L. Wu, and G. Song, “Convergence of volatile power markets with price-based demand response,” IEEE Trans. Power Systems, vol. 29, no. 5, pp. 2107–2118, 2014. doi: 10.1109/TPWRS.2014.2307872
[5]
M. Zhang, Y. Xiong, H. Cai, M. Bo, and J. Wang, “Study on the standard calculation model of power demand response incentive subsidy based on master-slave game,” in Proc. IEEE 5th Conf. Energy Internet and Energy System Integration, 2021, pp. 1923–1927.
[6]
N. Liu, X. Yu, C. Wang, C. Li, L. Ma, and J. Lei, “Energy-sharing model with price-based demand response for microgrids of peer-to-peer prosumers,” IEEE Trans. Power Systems, vol. 32, no. 5, pp. 3569–3583, 2017. doi: 10.1109/TPWRS.2017.2649558
[7]
N. H. Tran, T. Z. Oo, S. Ren, Z. Han, E.-N. Huh, and C. S. Hong, “Reward-to-reduce: An incentive mechanism for economic demand response of colocation datacenters,” IEEE J. Selected Areas in Commun., vol. 34, no. 12, pp. 3941–3953, 2016. doi: 10.1109/JSAC.2016.2611958
[8]
F. Zhang, Q. Yang, and D. An, “CDDPG: A deep-reinforcement-learning-based approach for electric vehicle charging control,” IEEE Internet of Things J., vol. 8, no. 5, pp. 3075–3087, 2021. doi: 10.1109/JIOT.2020.3015204
[9]
A. Kumari and S. Tanwar, “A reinforcement-learning-based secure demand response scheme for smart grid system,” IEEE Internet of Things J., vol. 9, no. 3, pp. 2180–2191, 2022. doi: 10.1109/JIOT.2021.3090305
[10]
W. Hu, “Transforming thermal comfort model and control in the tropics: A machine-learning approach,” Ph.D. dissertation, School of Computer Science and Engineering, Nanyang Technological University, Singapore, 2020.
[11]
L. Yu, S. Qin, M. Zhang, C. Shen, T. Jiang, and X. Guan, “A review of deep reinforcement learning for smart building energy management,” IEEE Internet of Things J., vol. 8, no. 15, pp. 12046–12063, 2021. doi: 10.1109/JIOT.2021.3078462
[12]
R. Pal, H ui, and V. Prasanna, “Privacy engineering for the smart micro-grid,” IEEE Trans. Knowledge and Data Engineering, vol. 31, no. 5, pp. 965–980, 2019. doi: 10.1109/TKDE.2018.2846640
[13]
Z. Bilgin, E. Tomur, M. A. Ersoy, and E. U. Soykan, “Statistical appliance inference in the smart grid by machine learning,” in Proc. IEEE 30th Int. Symp. Personal, Indoor and Mobile Radio Commun. (PIMRC Workshops), 2019, pp. 1–7.
[14]
L. Lyu, K. Nandakumar, B. Rubinstein, J. Jin, J. Bedo, and M. Palaniswami, “PPFA: Privacy preserving fog-enabled aggregation in smart grid,” IEEE Trans. Industrial Informatics, vol. 14, no. 8, pp. 3733–3744, 2018. doi: 10.1109/TII.2018.2803782
[15]
L. Zhu, M. Li, Z. Zhang, C. Xu, R. Zhang, X. Du, and N. Guizani, “Privacy-preserving authentication and data aggregation for fog-based smart grid,” IEEE Commun. Magazine, vol. 57, no. 6, pp. 80–85, 2019. doi: 10.1109/MCOM.2019.1700859
[16]
W. Han and Y. Xiao, “Privacy preservation for V2G networks in smart grid: A survey,” Computer Commun., vol. 91–92, pp. 17–28, 2016. doi: 10.1016/j.comcom.2016.06.006
[17]
S. Bahrami, Y. C. Chen, and V. W. S. Wong, “Deep reinforcement learning for demand response in distribution networks,” IEEE Trans. Smart Grid, vol. 12, no. 2, pp. 1496–1506, 2021. doi: 10.1109/TSG.2020.3037066
[18]
Z. Qin, D. Liu, H. Hua, and J. Cao, “Privacy preserving load control of residential microgrid via deep reinforcement learning,” IEEE Trans. Smart Grid, vol. 12, no. 5, pp. 4079–4089, 2021. doi: 10.1109/TSG.2021.3088290
[19]
O. Erdinç, A. Taşcıkaraoğlu, N. G. Paterakis, Y. Eren, and J. S. Catalão, “End-user comfort oriented day-ahead planning for responsive residential HVAC demand aggregation considering weather forecasts,” IEEE Trans. Smart Grid, vol. 8, no. 1, pp. 362–372, 2017. doi: 10.1109/TSG.2016.2556619
[20]
H. Wu, M. Shahidehpour, A. Alabdulwahab, and A. Abusorrah, “Demand response exchange in the stochastic day-ahead scheduling with variable renewable generation,” IEEE Trans. Sustainable Energy, vol. 6, no. 2, pp. 516–525, 2015. doi: 10.1109/TSTE.2015.2390639
[21]
F. Elghitani and W. Zhuang, “Aggregating a large number of residential appliances for demand response applications,” IEEE Trans. Smart Grid, vol. 9, no. 5, pp. 5092–5100, 2018. doi: 10.1109/TSG.2017.2679702
[22]
Y. Liu, D. Zhang, and H. B. Gooi, “Optimization strategy based on deep reinforcement learning for home energy management,” CSEE J. Power and Energy Systems, vol. 6, no. 3, pp. 572–582, 2020.
[23]
Y. Du and F. Li, “Intelligent multi-microgrid energy management based on deep neural network and model-free reinforcement learning,” IEEE Trans. Smart Grid, vol. 11, no. 2, pp. 1066–1076, 2020. doi: 10.1109/TSG.2019.2930299
[24]
L. Yu, W. Xie, D. Xie, Y. Zou, D. Zhang, Z. Sun, L. Zhang, Y. Zhang, and T. Jiang, “Deep reinforcement learning for smart home energy management,” IEEE Internet of Things J., vol. 7, no. 4, pp. 2751–2762, 2020. doi: 10.1109/JIOT.2019.2957289
[25]
X. Zhang, D. Biagioni, M. Cai, P. Graf, and S. Rahman, “An edge-cloud integrated solution for buildings demand response using reinforcement learning,” IEEE Trans. Smart Grid, vol. 12, no. 1, pp. 420–431, 2021. doi: 10.1109/TSG.2020.3014055
[26]
C. Zhang, S. R. Kuppannagari, C. Xiong, R. Kannan, and V. K. Prasanna, “A cooperative multi-agent deep reinforcement learning framework for real-time residential load scheduling,” in Proc. Int. Conf. Internet of Things Design and Implementation, 2019, pp. 59–69.
[27]
L. Yu, Y. Sun, Z. Xu, C. Shen, D. Yue, T. Jiang, and X. Guan, “Multi-agent deep reinforcement learning for HVAC control in commercial buildings,” IEEE Trans. Smart Grid, vol. 12, no. 1, pp. 407–419, 2021. doi: 10.1109/TSG.2020.3011739
[28]
Y. Wan, J. Qin, X. Yu, T. Yang, and Y. Kang, “Price-based residential demand response management in smart grids: A reinforcement learning-based approach,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 1, pp. 123–134, 2021.
[29]
B. Wang, C. Zhang, and Z. Y. Dong, “Interval optimization based coordination of demand response and battery energy storage system considering SOC management in a microgrid,” IEEE Trans. Sustainable Energy, vol. 11, no. 4, pp. 2922–2931, 2020. doi: 10.1109/TSTE.2020.2982205
[30]
Y. Li, R. Wang, and Z. Yang, “Optimal scheduling of isolated microgrids using automated reinforcement learning-based multi-period forecasting,” IEEE Trans. Sustainable Energy, vol. 13, no. 1, pp. 159–169, 2022. doi: 10.1109/TSTE.2021.3105529
[31]
D. Xu, B. Zhou, K. W. Chan, C. Li, Q. Wu, B. Chen, and S. Xia, “Distributed multienergy coordination of multimicrogrids with biogas-solar-wind renewables,” IEEE Trans. Industrial Informatics, vol. 15, no. 6, pp. 3254–3266, 2019. doi: 10.1109/TII.2018.2877143
[32]
N. Priyadarshi, S. Padmanaban, M. S. Bhaskar, F. Blaabjerg, J. B. Holm-Nielsen, F. Azam, and A. K. Sharma, “A hybrid photovoltaic-fuel cell-based single-stage grid integration with Lyapunov control scheme,” IEEE Systems J., vol. 14, no. 3, pp. 3334–3342, 2020. doi: 10.1109/JSYST.2019.2948899
[33]
D. Bertsimas, D. B. Brown, and C. Caramanis, “Theory and applications of robust optimization,” SIAM Review, vol. 53, no. 3, pp. 464–501, 2011. doi: 10.1137/080734510
[34]
G. Shani, J. Pineau, and R. Kaplow, “A survey of point-based pomdp solvers,” Autonomous Agents and Multi-Agent Systems, vol. 27, no. 1, pp. 1–51, 2013. doi: 10.1007/s10458-012-9200-2
[35]
C. Szepesvári, “Algorithms for reinforcement learning,” Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 4, no. 1, pp. 1–103, 2010.
[36]
V. Mnih, K. Kavukcuoglu, D. Silver, et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015. doi: 10.1038/nature14236
[37]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprin arXiv: 1509.02971, 2019.
[38]
J. R. Vázquez-Canteli and Z. Nagy, “Reinforcement learning for demand response: A review of algorithms and modeling techniques,” Applied Energy, vol. 235, pp. 1072–1089, 2019. doi: 10.1016/j.apenergy.2018.11.002
[39]
R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environ- ments,” arXiv preprint arXiv: 1706.02275, 2020.
[40]
D. W. Ruck, S. K. Rogers, and M. Kabrisky, “Feature selection using a multilayer perceptron,” J. Neural Network Computing, vol. 2, no. 2, pp. 40–48, 1990.
[41]
H. Tang, R. Houthooft, D. Foote, A. Stooke, X. Chen, Y. Duan, J. Schulman, F. De Turck, and P. Abbeel, “exploration: A study of count-based exploration for deep reinforcement learning,” in Proc. 31st Conf. Neural Information Processing Systems, vol. 30, 2017, pp. 1–18.
[42]
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. doi: 10.1038/nature14539
[43]
R. Sutton and A. Barto, Reinforcement Learning: An Introduction. Cambridge, USA: MIT Press, 1998.
[44]
V. Konda and J. Tsitsiklis, “Actor-critic algorithms,” in Proc. 12th Conf.Neural Information Processing Systems, 1999, vol. 12, pp.1008–1014.
[45]
J. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y. Bengio, “Attention-based models for speech recognition,” arXiv preprint arXiv: 1506.07503, 2015.
[46]
T. Rashid, M. Samvelyan, C. Schroeder, G. Farquhar, J. Foerster, and S. Whiteson, “QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning,” in Proc. Int. Conf. Machine Learning, 2018, pp. 4295–4304.
[47]
H. Wang, T. Huang, X. Liao, H. Abu-Rub, and G. Chen, “Reinforcement learning for constrained energy trading games with incomplete information,” IEEE Trans. Cyber., vol. 47, no. 10, pp. 3404–3416, 2016.
[48]
T. Kurutach, I. Clavera, Y. Duan, A. Tamar, and P. Abbeel, “Model-ensemble trust-region policy optimization,” arXiv preprint arXiv: 1802.10592, 2018.
[49]
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv: 1503.02531, 2015.
Novel demand side management (DSM) algorithm: a novel multi-agent reinforcement learning algorithm is proposed to produce the DSM control strategy for microgrids. Specifically, the proposed method adopts the idea of centralized training and decentralized execution paradigm to improve the stability of training experience in the multi-agent environment. Moreover, an attention mechanism is proposed to endow each microgrid the ability of adaptively determining which microgrid is more noteworthy for better cooperation
Explicit privacy protection method: an encryptor based on a neural network with fixed parameters is presented to transform the private information of microgrid (i.e., the demand response strategy and the energy consumption demand) from low-dimensional to high-dimensional in order to protect energy users' privacy. Furthermore, this paper theoretically prove that the proposed encryptor-based privacy preserving method will not affect both the convergence property and the training performance of the reinforcement learning algorithm
Complete experiments with real-world data: extensive simulations are performed to verify the effectiveness of the proposed method with the real-world energy consumption data of Xi'an, Shaanxi, China. Specifically, the proposed method is compared with state-of-the-art RL methods in terms of the bill payment, satisfaction and utility. The ablation studies are conducted to prove the proposed privacy protection method will not cause performance degeneration of reinforcement learning algorithm
Export File
Citation
F. Y. Zhang, Q. Y. Yang, and D. An, “Privacy preserving demand side management method via multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 10, pp. 1984–1999, Oct. 2023. doi: 10.1109/JAS.2023.123321
F. Y. Zhang, Q. Y. Yang, and D. An, “Privacy preserving demand side management method via multi-agent reinforcement learning,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 10, pp. 1984–1999, Oct. 2023. doi: 10.1109/JAS.2023.123321
Table
IV.
The Mean and Deviations of the Bill Payment, the Satisfaction as Well as the Utility for Seven Different Algorithms in the Last 10 Evaluation Episodes. All Methods are Run Ten Times With Different Random Seeds
Table
V.
The Mean and Deviations of the Bill Payment, the Satisfaction as Well as the Utility for the AB-MADDPG Algorithm and the AB-MADDPG-WP Algorithm in the Last 10 Evaluation Episodes
Figure 1. System model of the demand side management scheme.
Figure 2. The structure of proposed method, including 1) Actor networks for decentralized execution; 2) Critic networks for centralized training; 3) Encryptors to transform the private information of microgrids from low-dimensional to high-dimensional.
Figure 3. The structure of proposed encryptor.
Figure 4. The structure of proposed attention-based critic network.
Figure 5. The energy consumption data of each microgrid with the time scale of one hour in 20151
Figure 6. The energy consumption demand as well as the actual energy purchase of (a) Shopping mall II, (b) Hotel I, and (c) College II at each time step with different energy price for 72 hours. Red lines represent dynamic energy prices.
Figure 7. The energy consumption demand as well as the actual energy consumption of (a) Shopping mall II, (b) Hotel I, and (c) College II at each time step for 72 hours.
Figure 8. Average (a) bill payment, (b) satisfaction, and (c) utility obtained by the AB-MADDPG algorithm (red), the MADDPG algorithm (blue), the IDDPG algorithm (green), the IDQN algorithm (purple), the QMIX algorithm (orange), the Greedy algorithm (yellow) and the AE-DDPG algorithm (cyan) under 10 different random seeds. The solid lines and shaded regions show the mean and standard deviation over ten runs, respectively.
Figure 9. Average (a) bill payment, (b) satisfaction, and (c) utility obtained by the AB-MADDPG algorithm (red), the AB-MADDPG-WP algorithm (navy). The solid lines and shaded regions show the mean and standard deviation over ten runs, respectively.
Figure 10. The mean (a) bill payment, (b) satisfaction, and (c) utility obtained by the AB-MADDPG algorithm under different maximum ξ in the last 10 evaluation episodes. The symbols and error bars show the mean and standard deviation over ten runs, respectively.
Figure 11. The mean (a) bill payment, (b) satisfaction, and (c) utility obtained by the AB-MADDPG algorithm under different γ in the last 10 evaluation episodes.




 DownLoad:
DownLoad:
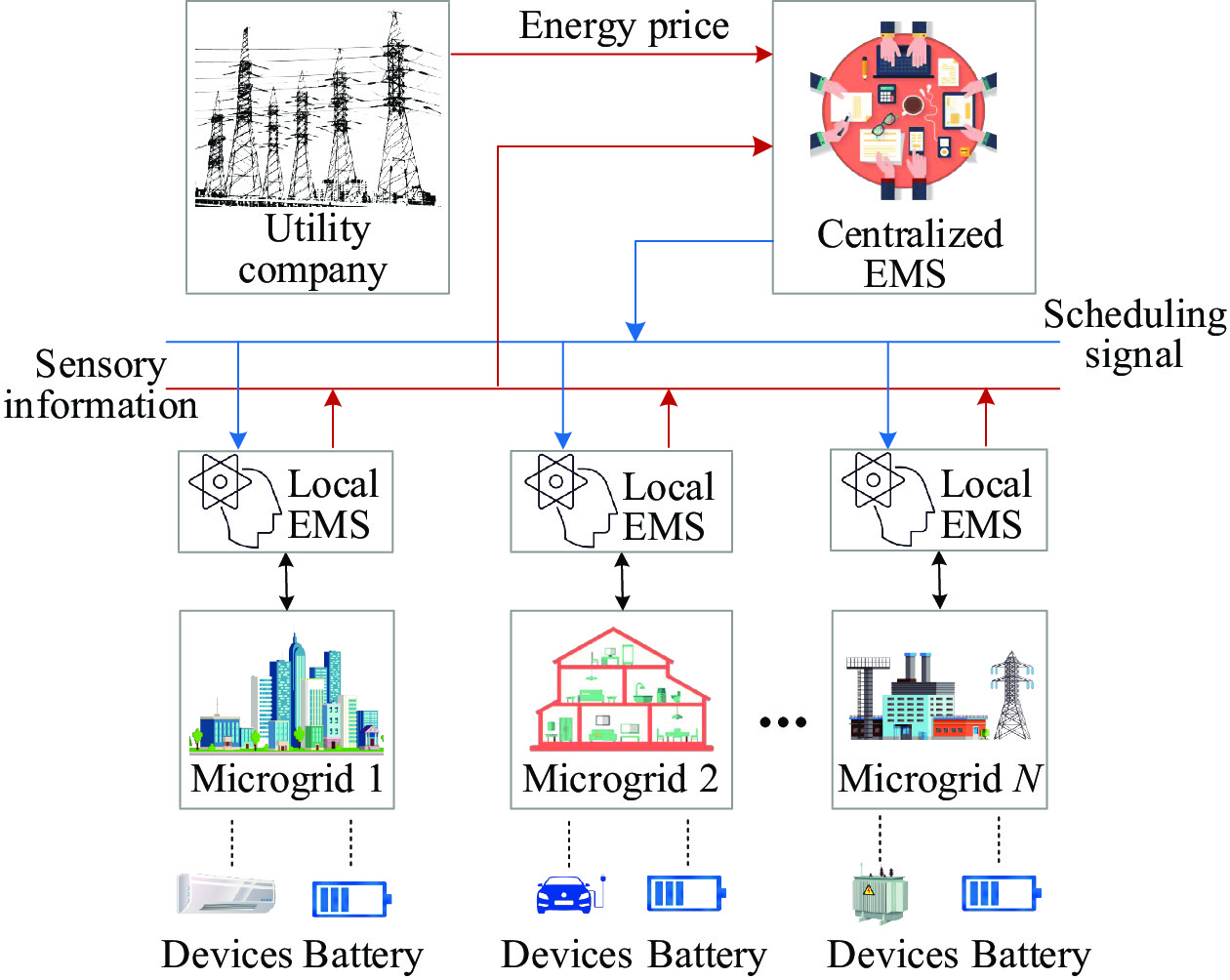
 DownLoad:
DownLoad:
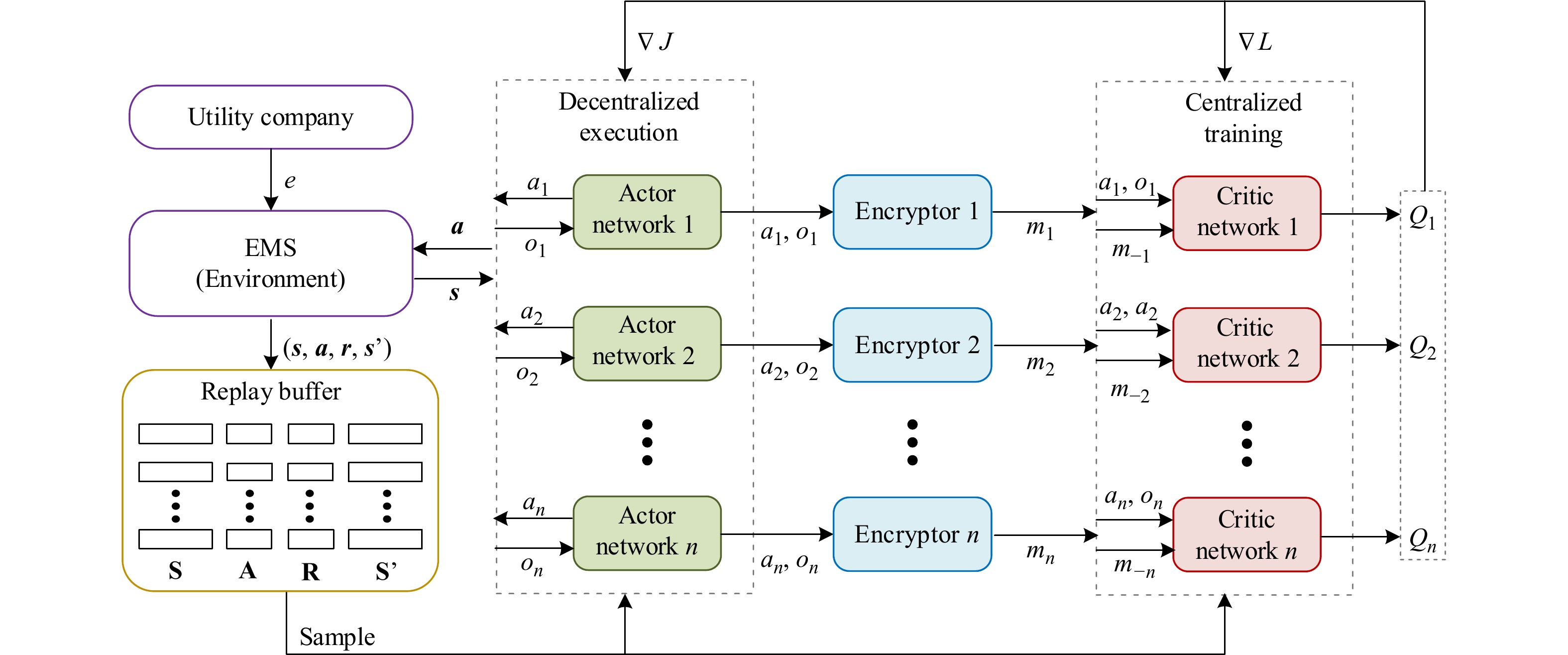
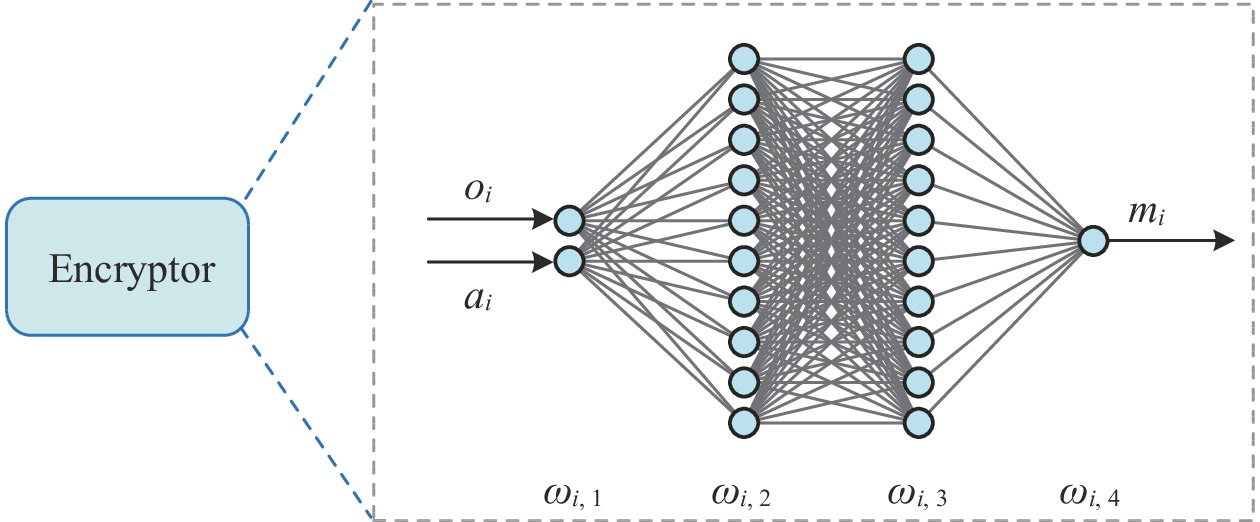
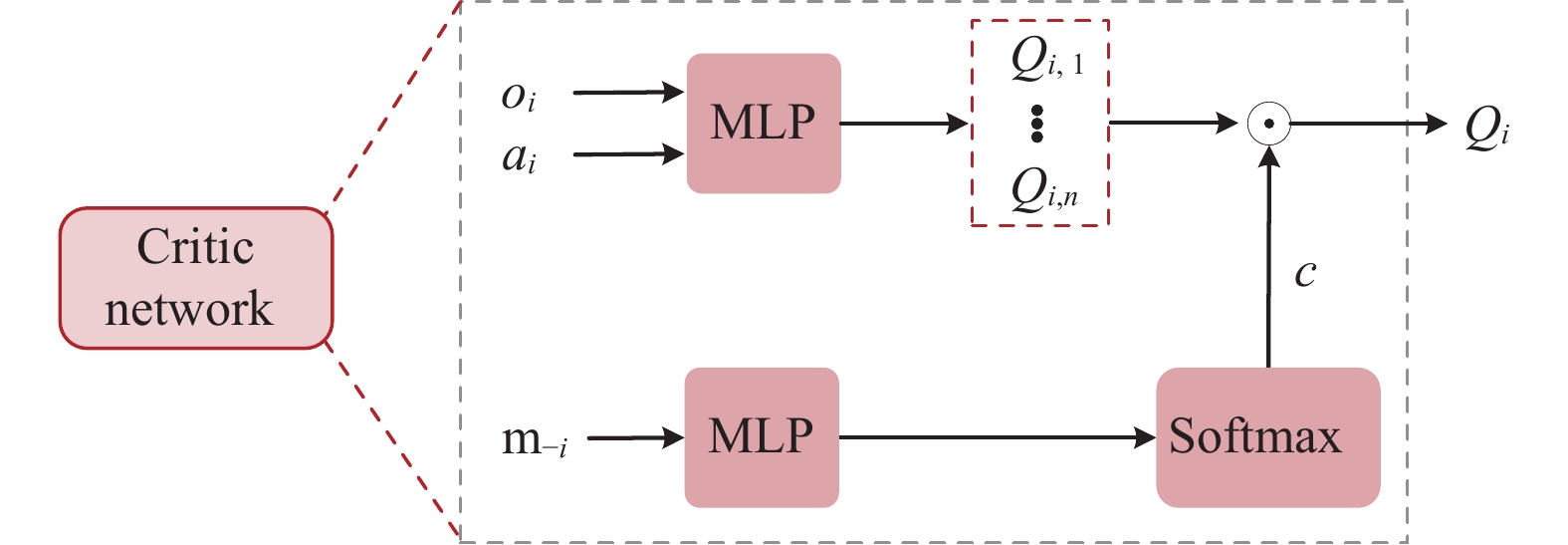
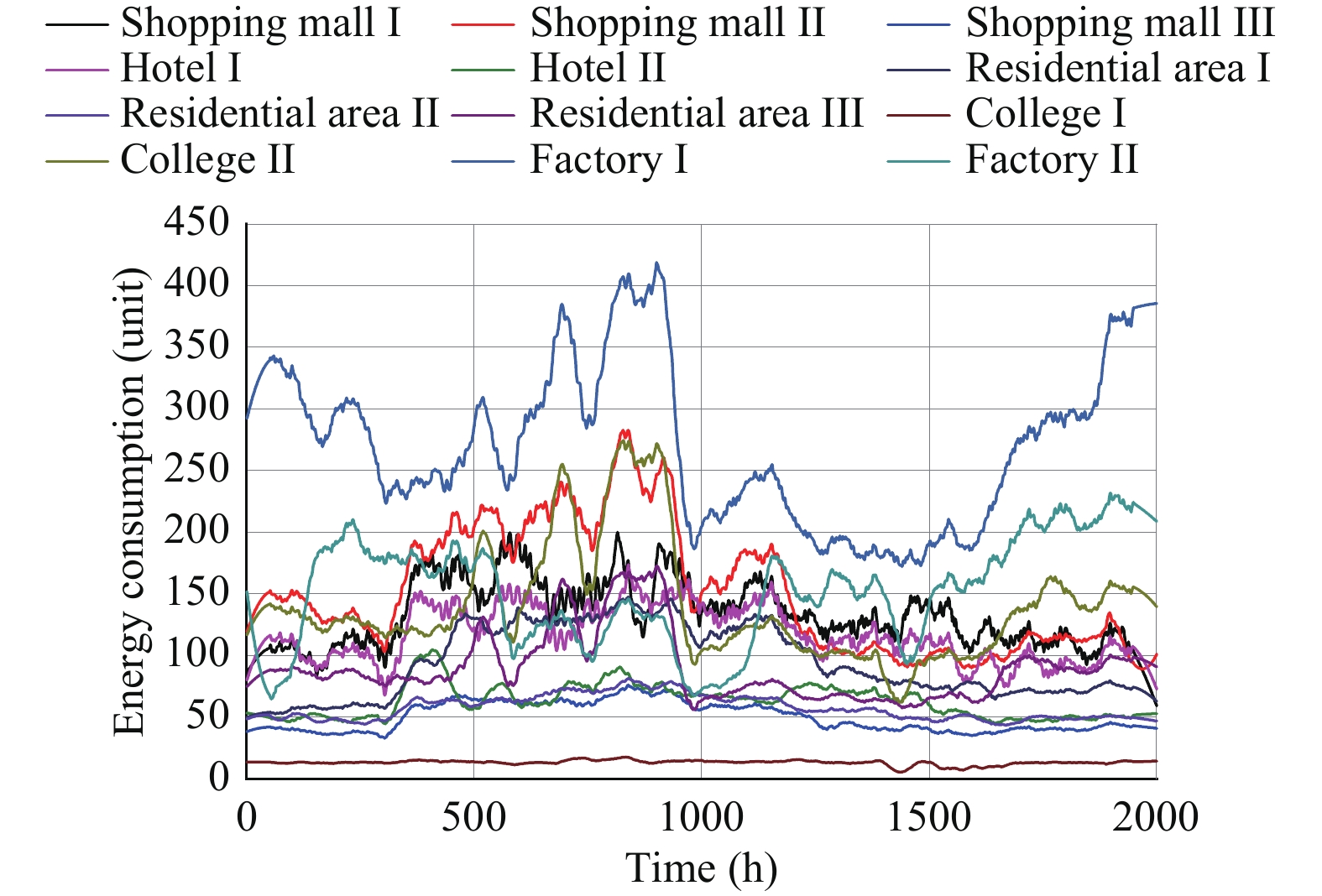
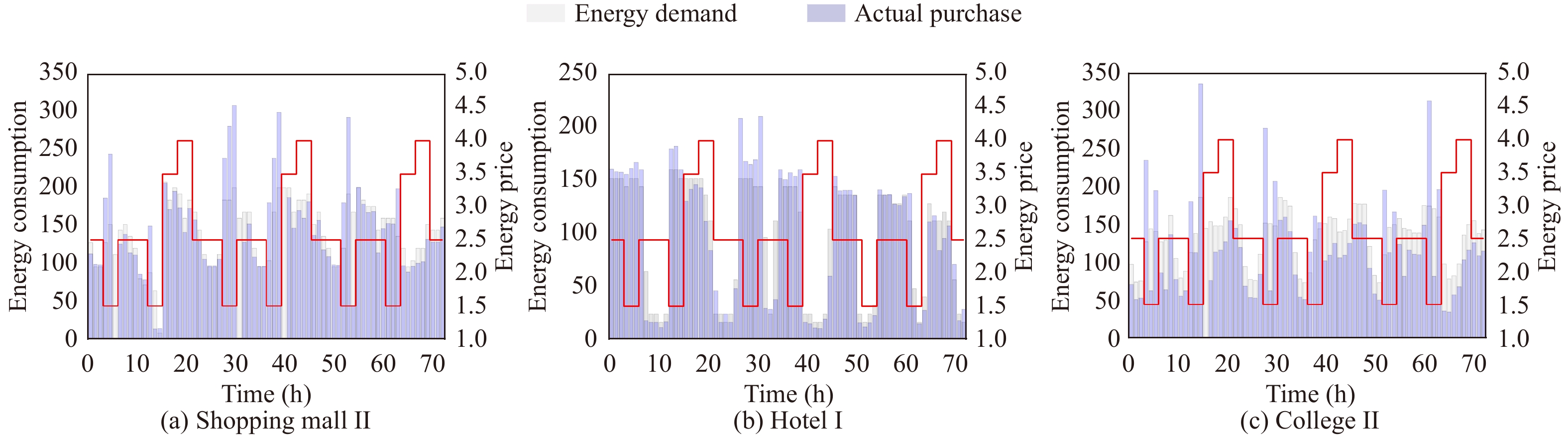
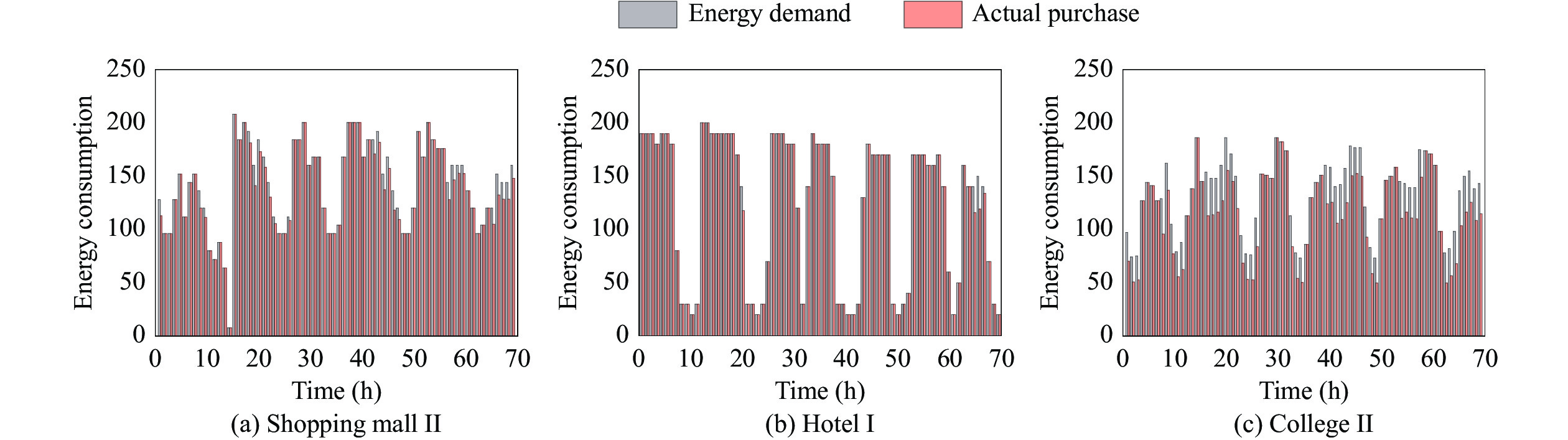
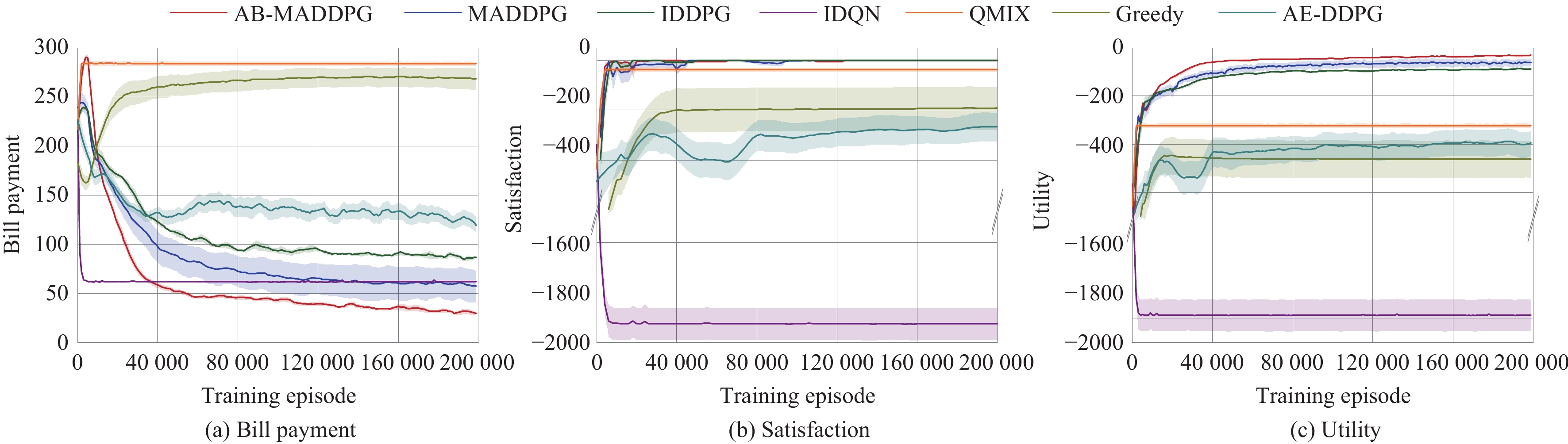
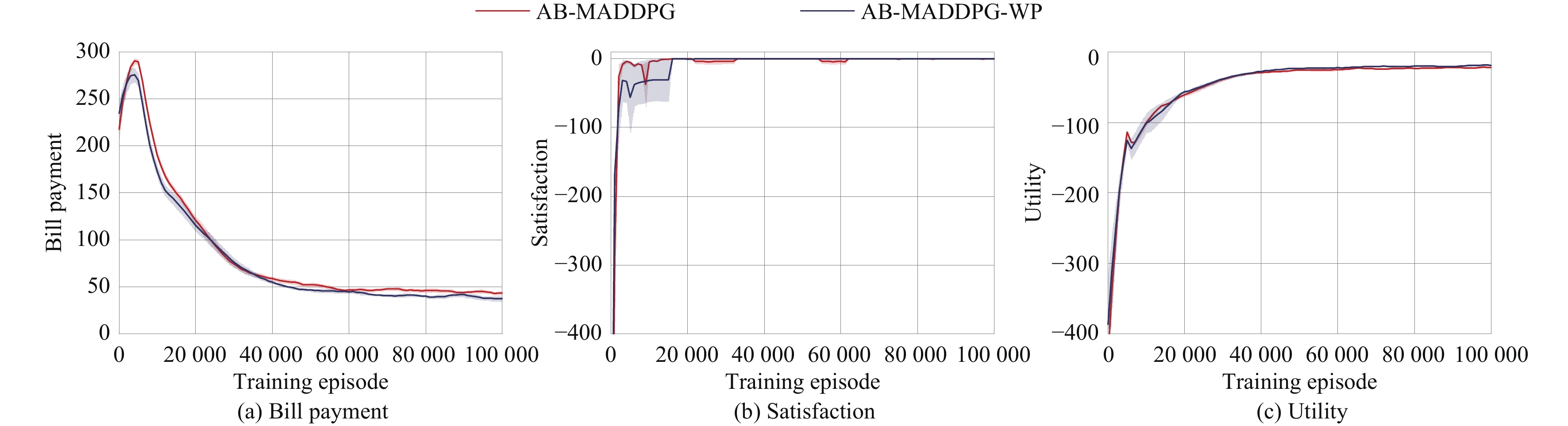

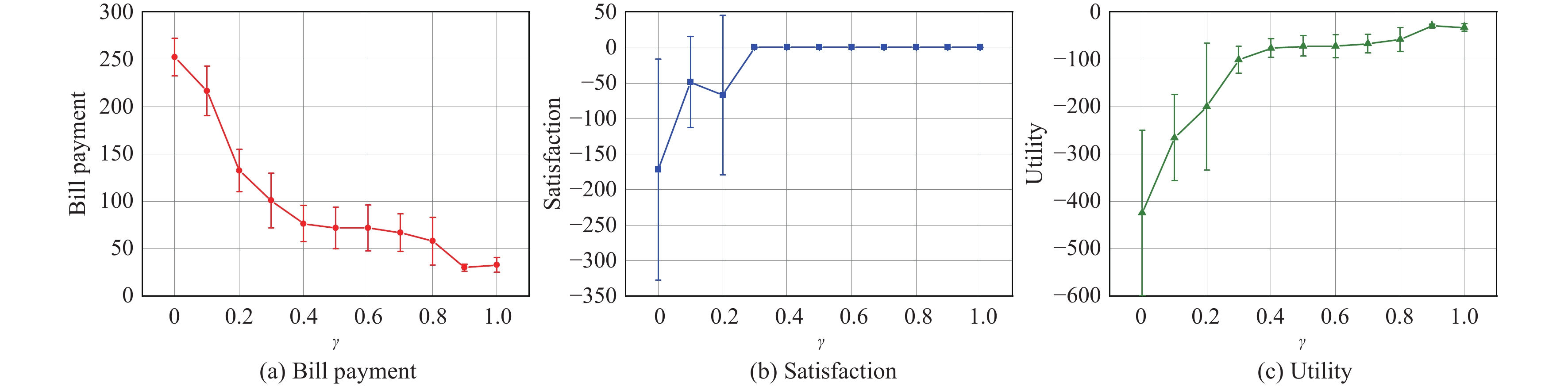

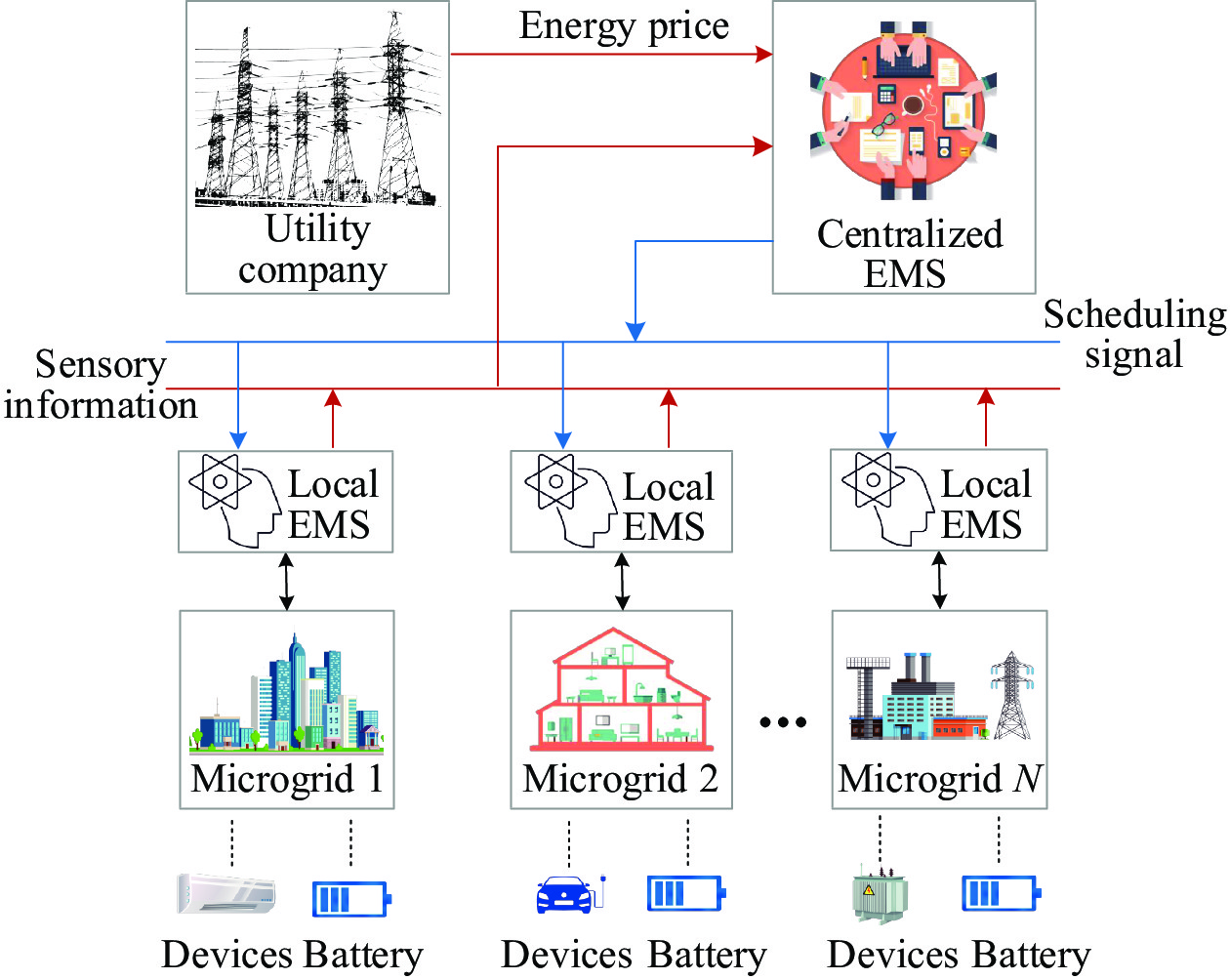




 DownLoad:
DownLoad:









