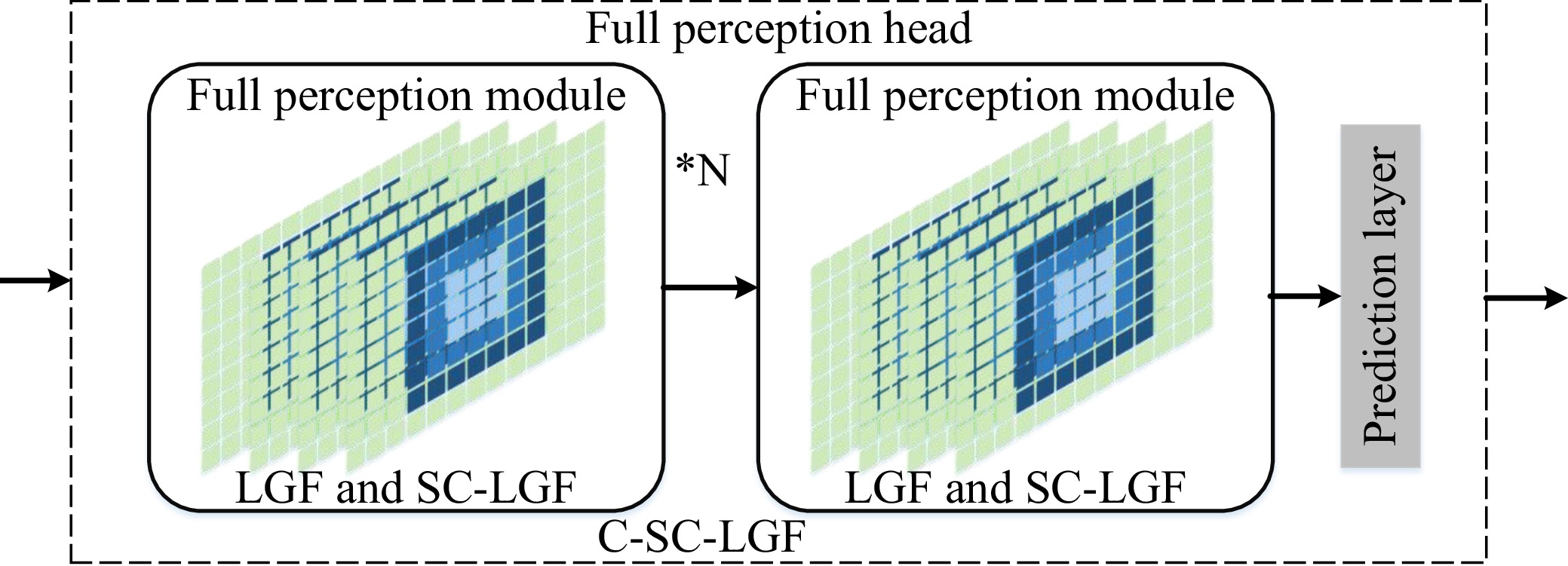
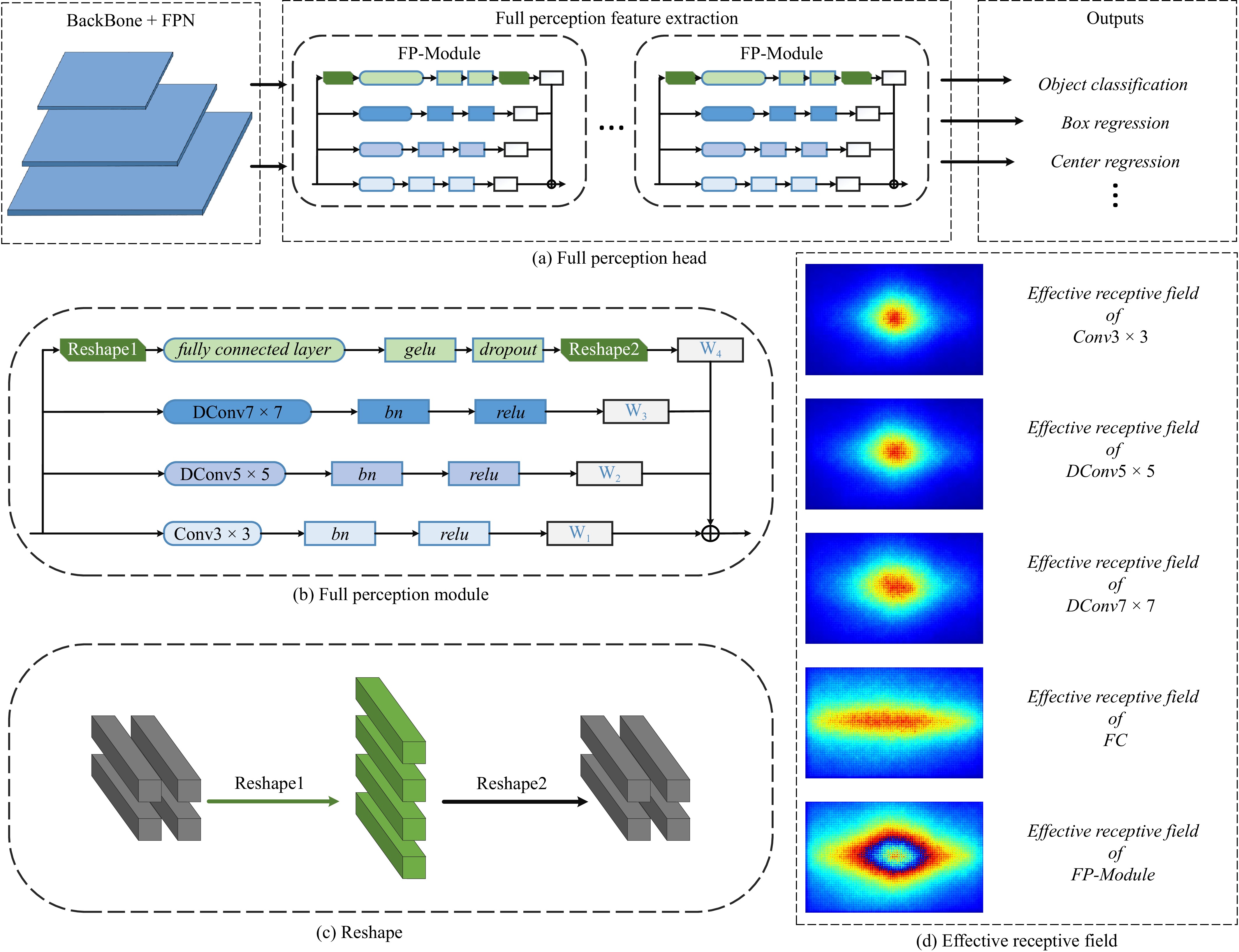
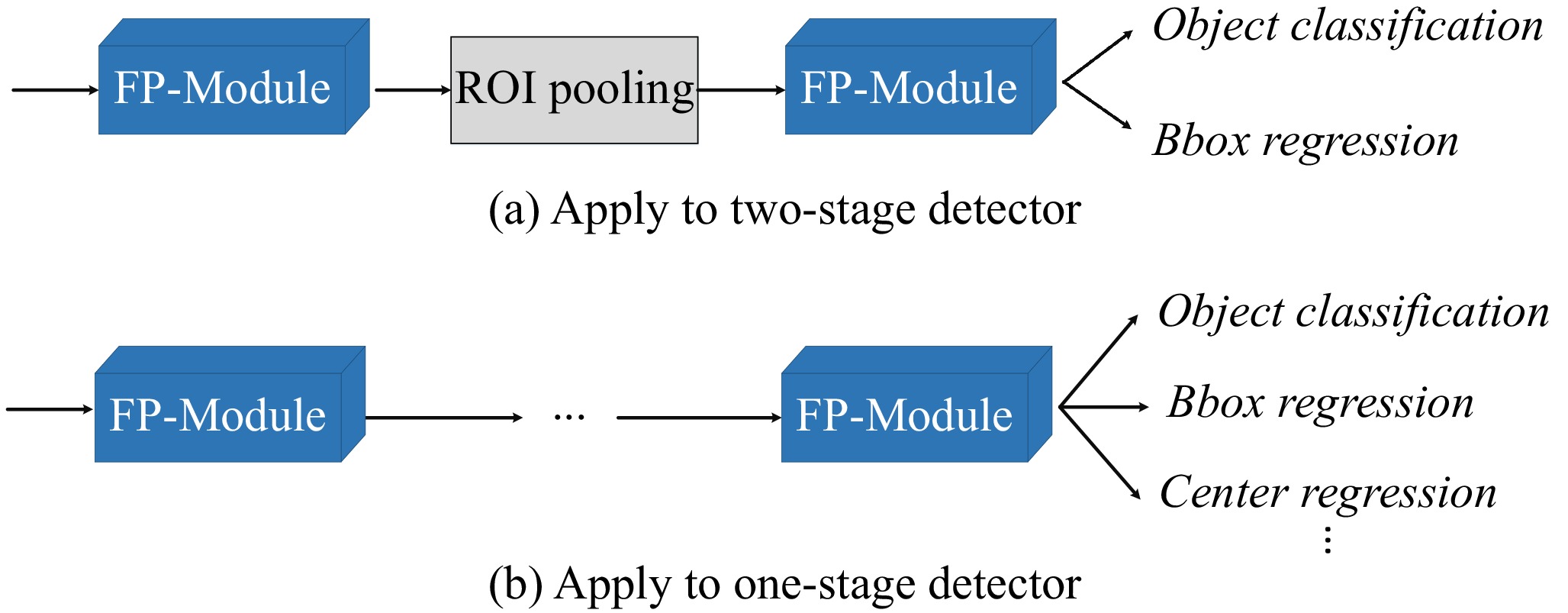
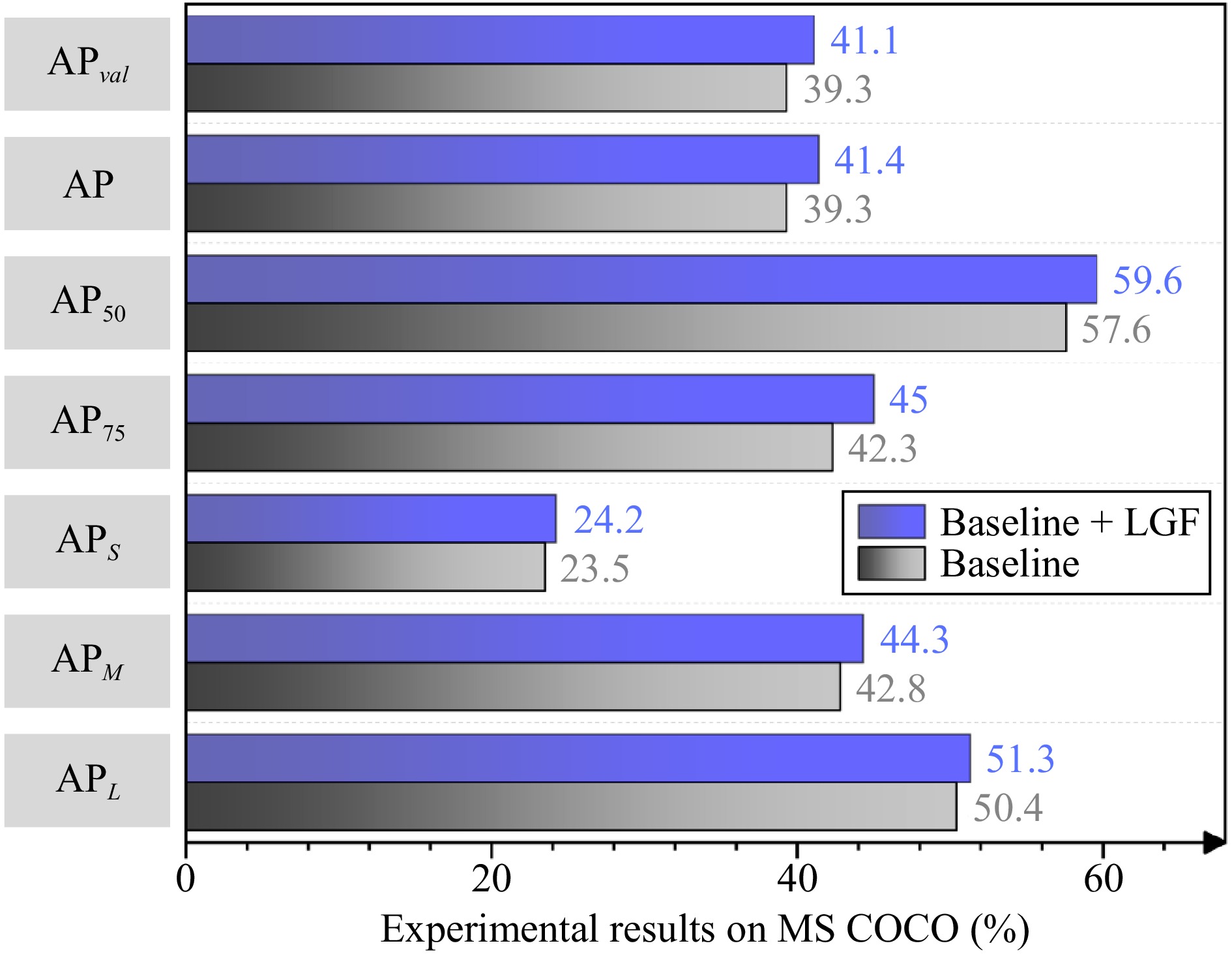
A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation

IEEE/CAA Journal of Automatica Sinica
| Citation: | J. Hua, Z. Wang, X. Tian, Q. Zou, J. Xiao, and J. Ma, “Full perception head: Bridging the gap between local and global features,” IEEE/CAA J. Autom. Sinica, 2025. doi: 10.1109/JAS.2025.125333

|

| [1] |
C. Pan, J. Peng, and Z. Zhang, “Depth-guided vision transformer with normalizing flows for monocular 3d object detection,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 3, pp. 673–689, 2024. doi: 10.1109/JAS.2023.123660
|
| [2] |
S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li, “Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 9759–9768.
|
| [3] |
I. Ahmed, S. Din, G. Jeon, F. Piccialli, and G. Fortino, “Towards collaborative robotics in top view surveillance: A framework for multiple object tracking by detection using deep learning,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 7, pp. 1253–1270, 2021. doi: 10.1109/JAS.2020.1003453
|
| [4] |
Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 11 966–11 976.
|
| [5] |
N. Zeng, X. Li, P. Wu, H. Li, and X. Luo, “A novel tensor decomposition-based efficient detector for low-altitude aerial objects with knowledge distillation scheme,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 2, pp. 487–501, 2024. doi: 10.1109/JAS.2023.124029
|
| [6] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. Adv. Neural Inform. Process. Syst., 2017, p. 6000–6010.
|
| [7] |
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in Proc. Int. Conf. Learn. Represent., 2021.
|
| [8] |
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou, “Training data-efficient image transformers & distillation through attention,” in ICML, 2021, pp. 10347–10357.
|
| [9] |
Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 9992–10002.
|
| [10] |
Z. Liu, H. Hu, Y. Lin, Z. Yao, Z. Xie, Y. Wei, J. Ning, Y. Cao, Z. Zhang, L. Dong, F. Wei, and B. Guo, “Swin transformer V2: scaling up capacity and resolution,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 11999–12009.
|
| [11] |
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 548–558.
|
| [12] |
I. O. Tolstikhin, N. Houlsby, A. Kolesnikov, L. Beyer, X. Zhai, T. Unterthiner, J. Yung, A. Steiner, D. Keysers, J. Uszkoreit, M. Lucic, and A. Dosovitskiy, “Mlp-mixer: An all-mlp architecture for vision,” in Proc. Adv. Neural Inform. Process. Syst., 2021, pp. 24261–24272.
|
| [13] |
X. Ding, H. Chen, X. Zhang, J. Han, and G. Ding, “RepMLPNet: Hierarchical vision MLP with re-parameterized locality,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 568–577.
|
| [14] |
H. Touvron, P. Bojanowski, M. Caron, M. Cord, A. El-Nouby, E. Grave, G. Izacard, A. Joulin, G. Synnaeve, J. Verbeek, and H. Jégou, “ResMLP: Feedforward networks for image classification with data-efficient training,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 4, pp. 5314–5321, 2023. doi: 10.1109/TPAMI.2022.3206148
|
| [15] |
X. Pan, C. Ge, R. Lu, S. Song, G. Chen, Z. Huang, and G. Huang, “On the integration of self-attention and convolution,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 805–815.
|
| [16] |
Z. Peng, W. Huang, S. Gu, L. Xie, Y. Wang, J. Jiao, and Q. Ye, “Conformer: Local features coupling global representations for visual recognition,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 357–366.
|
| [17] |
H. Wu, B. Xiao, N. Codella, M. Liu, X. Dai, L. Yuan, and L. Zhang, “CvT: Introducing convolutions to vision transformers,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 22–31.
|
| [18] |
J. Li, A. Hassani, S. Walton, and H. Shi, “ConvMLP: Hierarchical convolutional mlps for vision,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2023, pp. 6307–6316.
|
| [19] |
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 770–778.
|
| [20] |
J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei, “Deformable convolutional networks,” in Proc. Int. Conf. Comput. Vis., 2017, pp. 764–773.
|
| [21] |
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Proc. Int. Conf. Learn. Represent., 2015.
|
| [22] |
S. Xie, R. B. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 5987–5995.
|
| [23] |
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 2261–2269.
|
| [24] |
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2015, pp. 1–9.
|
| [25] |
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML, 2015, pp. 448–456.
|
| [26] |
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 2818–2826.
|
| [27] |
C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi, “Inception-v4, inception-resnet and the impact of residual connections on learning,” in AAAI, 2017, pp. 4278–4284.
|
| [28] |
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv: 1704.04861, 2017.
|
| [29] |
M. Sandler, A. G. Howard, M. Zhu, A. Zhmoginov, and L. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 4510–4520.
|
| [30] |
A. Howard, M. Sandler, B. Chen, W. Wang, L.-C. Chen, M. Tan, G. Chu, V. Vasudevan, Y. Zhu, R. Pang, H. Adam, and Q. Le, “Searching for MobileNetV3,” in Proc. Int. Conf. Comput. Vis., 2019, pp. 1314–1324.
|
| [31] |
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 779–788.
|
| [32] |
J. Redmon and A. Farhadi, “Yolo9000: Better, faster, stronger,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 6517–6525.
|
| [33] |
R. Joseph and F. Ali, “Yolov3: An incremental improvement,” arXiv preprint arXiv: 1804.02767, 2018.
|
| [34] |
A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv: 2004.10934, 2020.
|
| [35] |
C. Li, L. Li, H. Jiang, K. Weng, Y. Geng, L. Li, Z. Ke, Q. Li, M. Cheng, W. Nie et al., “Yolov6: A single-stage object detection framework for industrial applications,” arXiv preprint arXiv: 2209.02976, 2022.
|
| [36] |
C. Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, “Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” arXiv preprint arXiv: 2207.02696, 2022.
|
| [37] |
Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “Yolox: Exceeding yolo series in 2021,” arXiv preprint arXiv: 2107.08430, 2021.
|
| [38] |
Q. Hou, C. Lu, M. Cheng, and J. Feng, “Conv2former: A simple transformer-style convnet for visual recognition,” arXiv preprint arXiv: 2211.11943, 2022.
|
| [39] |
Y. Rao, W. Zhao, Z. Zhu, J. Lu, and J. Zhou, “Global filter networks for image classification,” in Proc. Adv. Neural Inform. Process. Syst., 2021, pp. 980–993.
|
| [40] |
D. W. Romero, R. Bruintjes, J. M. Tomczak, E. J. Bekkers, M. Hoogendoorn, and J. C. van Gemert, “Flexconv: Continuous kernel convolutions with differentiable kernel sizes,” in Proc. Int. Conf. Learn. Represent., 2022.
|
| [41] |
X. Ding, X. Zhang, J. Han, and G. Ding, “Scaling up your kernels to 31×31: Revisiting large kernel design in cnns,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 11953–11965.
|
| [42] |
S. Liu, T. Chen, X. Chen, X. Chen, Q. Xiao, B. Wu, T. Kärkkäinen, M. Pechenizkiy, D. C. Mocanu, and Z. Wang, “More convnets in the 2020s: Scaling up kernels beyond 51x51 using sparsity,” in Proc. Int. Conf. Learn. Represent., 2023.
|
| [43] |
S. E. Finder, R. Amoyal, E. Treister, and O. Freifeld, “Wavelet convolutions for large receptive fields,” in Proc. Eur. Conf. Comput. Vis., vol. 15112, 2024, pp. 363–380.
|
| [44] |
F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” in Proc. Int. Conf. Learn. Represent., 2016.
|
| [45] |
X. Zhu, H. Hu, S. Lin, and J. Dai, “Deformable convnets v2: More deformable, better results,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2019, pp. 9300–9308.
|
| [46] |
K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask R-CNN,” in Proc. Int. Conf. Comput. Vis., 2017, pp. 2980–2988.
|
| [47] |
M.-H. Guo, Z.-N. Liu, T.-J. Mu, and S.-M. Hu, “Beyond self-attention: External attention using two linear layers for visual tasks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 5, pp. 5436–5447, 2023.
|
| [48] |
S. Chen, E. Xie, C. Ge, R. Chen, D. Liang, and P. Luo, “CycleMLP: A mlp-like architecture for dense prediction,” in Proc. Int. Conf. Learn. Represent., 2022.
|
| [49] |
D. Lian, Z. Yu, X. Sun, and S. Gao, “AS-MLP: an axial shifted MLP architecture for vision,” in Proc. Int. Conf. Learn. Represent., 2022.
|
| [50] |
W. Zaremba, I. Sutskever, and O. Vinyals, “Recurrent neural network regularization,” arXiv preprint arXiv: 1409.2329, 2014.
|
| [51] |
T. Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 936–944.
|
| [52] |
X. Dong, J. Bao, D. Chen, W. Zhang, N. Yu, L. Yuan, D. Chen, and B. Guo, “CSWin Transformer: A general vision transformer backbone with cross-shaped windows,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 12114–12124.
|
| [53] |
B. Heo, S. Yun, D. Han, S. Chun, J. Choe, and S. J. Oh, “Rethinking spatial dimensions of vision transformers,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 11916–11925.
|
| [54] |
Y. Li, C. Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vision transformers for classification and detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 4794–4804.
|
| [55] |
W. Wang, E. Xie, X. Li, D. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 548–558.
|
| [56] |
J. Yang, C. Li, P. Zhang, X. Dai, B. Xiao, L. Yuan, and J. Gao, “Focal self-attention for local-global interactions in vision transformers,” arXiv preprint arXiv: 2107.00641, 2021.
|
| [57] |
L. Yuan, Q. Hou, Z. Jiang, J. Feng, and S. Yan, “VOLO: vision outlooker for visual recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 5, pp. 6575–6586, 2023.
|
| [58] |
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” vol. abs/2312.00752, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.00752
|
| [59] |
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,” in ICML, 2024.
|
| [60] |
M. Zhang, Y. Yu, S. Jin, L. Gu, T. Lin, and X. Tao, “VM-UNET-V2: rethinking vision mamba unet for medical image segmentation,” in Bioinformatics Research and Applications, W. Peng, Z. Cai, and P. Skums, Eds., vol. 14954, 2024, pp. 335–346.
|
| [61] |
Z. Xing, T. Ye, Y. Yang, G. Liu, and L. Zhu, “Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation,” in Medical Image Computing and Computer Assisted Intervention, vol. 15008, 2024, pp. 578–588.
|
| [62] |
T. Huang, X. Pei, S. You, F. Wang, C. Qian, and C. Xu, “Localmamba: Visual state space model with windowed selective scan,” vol. abs/2403.09338, 2024.
|
| [63] |
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S. Xia, “Mambair: A simple baseline for image restoration with state-space model,” in Proc. Eur. Conf. Comput. Vis., vol. 15076, 2024, pp. 222–241.
|
| [64] |
J. Guo, K. Han, H. Wu, Y. Tang, X. Chen, Y. Wang, and C. Xu, “CMT: Convolutional neural networks meet vision transformers,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 12165–12175.
|
| [65] |
C. Liu, W. Wei, B. Liang, X. Liu, W. Shang, and J. Li, “ConvMLP-Mixer based real-time stereo matching network towards autonomous driving,” IEEE Trans. Veh. Technol., vol. 72, no. 2, pp. 2581–2586, 2023. doi: 10.1109/TVT.2022.3206612
|
| [66] |
X. Kang, H. Yin, and P. Duan, “Global-local feature fusion network for visible-infrared vehicle detection,” IEEE Geoscience and Remote Sensing Letters, vol. 21, pp. 1–5, 2024.
|
| [67] |
J. Shen, Y. Chen, Y. Liu, X. Zuo, H. Fan, and W. Yang, “Icafusion: Iterative cross-attention guided feature fusion for multispectral object detection,” Pattern Recognit., vol. 145, p. 109913, 2024. doi: 10.1016/j.patcog.2023.109913
|
| [68] |
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in Proc. Eur. Conf. Comput. Vis., 2020, pp. 213–229.
|
| [69] |
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: Deformable transformers for end-to-end object detection,” in Proc. Int. Conf. Learn. Represent., 2021.
|
| [70] |
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y. Shum, “DINO: DETR with improved denoising anchor boxes for end-to-end object detection,” in Proc. Int. Conf. Learn. Represent., 2023.
|
| [71] |
L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 4, pp. 834–848, 2018. doi: 10.1109/TPAMI.2017.2699184
|
| [72] |
S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1137–1149, 2017. doi: 10.1109/TPAMI.2016.2577031
|
| [73] |
Z. Shao, W. Wu, Z. Wang, W. Du, and C. Li, “SeaShips: A large-scale precisely annotated dataset for ship detection,” IEEE Trans. Multimedia, vol. 20, no. 10, pp. 2593–2604, 2018. doi: 10.1109/TMM.2018.2865686
|
| [74] |
J. Fritsch, T. Kuehnl, and A. Geiger, “A new performance measure and evaluation benchmark for road detection algorithms,” in Int. Conf. on Intelligent Transportation Systems, 2013.
|
| [75] |
Y. P. Loh and C. S. Chan, “Getting to know low-light images with the exclusively dark dataset,” Comput. Vis. Image Underst., vol. 178, pp. 30–42, 2019. doi: 10.1016/j.cviu.2018.10.010
|
| [76] |
C. Sakaridis, D. Dai, S. Hecker, and L. V. Gool, “Model adaptation with synthetic and real data for semantic dense foggy scene understanding,” in Proc. Eur. Conf. Comput. Vis., vol. 11217, 2018, pp. 707–724.
|
| [77] |
T. Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 2, pp. 318–327, 2020. doi: 10.1109/TPAMI.2018.2858826
|
| [78] |
Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: Fully convolutional one-stage object detection,” in Proc. Int. Conf. Comput. Vis., 2019, pp. 9626–9635.
|
| [79] |
N. Wang, Y. Gao, H. Chen, P. Wang, Z. Tian, C. Shen, and Y. Zhang, “NAS-FCOS: fast neural architecture search for object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 11940–11948.
|
| [80] |
Y. Wu, Y. Chen, L. Yuan, Z. Liu, L. Wang, H. Li, and Y. Fu, “Rethinking classification and localization for object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 10183–10192.
|
| [81] |
T. Kong, F. Sun, H. Liu, Y. Jiang, L. Li, and J. Shi, “Foveabox: Beyound anchor-based object detection,” IEEE Trans. Image Process., vol. 29, pp. 7389–7398, 2020. doi: 10.1109/TIP.2020.3002345
|
| [82] |
H. Zhang, Y. Wang, F. Dayoub, and N. Sünderhauf, “Varifocalnet: An iou-aware dense object detector,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2021, pp. 8514–8523.
|
| [83] |
D. Meng, X. Chen, Z. Fan, G. Zeng, H. Li, Y. Yuan, L. Sun, and J. Wang, “Conditional DETR for fast training convergence,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 3631–3640.
|
| [84] |
S. Liu, F. Li, H. Zhang, X. Yang, X. Qi, H. Su, J. Zhu, and L. Zhang, “DAB-DETR: Dynamic anchor boxes are better queries for DETR,” in Proc. Int. Conf. Learn. Represent., 2022.
|
| [85] |
X. Li, C. Lv, W. Wang, G. Li, L. Yang, and J. Yang, “Generalized focal loss: Towards efficient representation learning for dense object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 3, pp. 3139–3153, 2023.
|
| [86] |
P. Sun, R. Zhang, Y. Jiang, T. Kong, C. Xu, W. Zhan, M. Tomizuka, L. Li, Z. Yuan, C. Wang, and P. Luo, “Sparse R-CNN: end-to-end object detection with learnable proposals,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2021, pp. 14454–14463.
|
| [87] |
P. Sun, R. Zhang, Y. Jiang, T. Kong, C. Xu, W. Zhan, M. Tomizuka, Z. Yuan, and P. Luo, “Sparse r-cnn: An end-to-end framework for object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, p. 12, 2023.
|
| [88] |
K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang, C. C. Loy, and D. Lin, “Hybrid task cascade for instance segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2019, pp. 4969–4978.
|
| [89] |
X. Dai, Y. Chen, B. Xiao, D. Chen, M. Liu, L. Yuan, and L. Zhang, “Dynamic Head: Unifying object detection heads with attentions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2021, pp. 7373–7382.
|
| [90] |
H. Wang, Q. Wang, H. Zhang, Q. Hu, and W. Zuo, “CrabNet: Fully task-specific feature learning for one-stage object detection,” IEEE Trans. Image Process., vol. 31, pp. 2962–2974, 2022. doi: 10.1109/TIP.2022.3162099
|
| [91] |
L. Yang, Y. Xu, S. Wang, C. Yuan, Z. Zhang, B. Li, and W. Hu, “PDNet: Toward better one-stage object detection with prediction decoupling,” IEEE Trans. Image Process., vol. 31, pp. 5121–5133, 2022. doi: 10.1109/TIP.2022.3193223
|
| [92] |
Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: A simple and strong anchor-free object detector,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 4, pp. 1922–1933, 2022.
|
| [93] |
Z. Zheng, R. Ye, Q. Hou, D. Ren, P. Wang, W. Zuo, and M.-M. Cheng, “Localization distillation for object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, p. 8, 2023.
|
| [94] |
R. Yao, Y. Rong, Q. Huang, and S. Xiong, “Ctod: Cross-attentive task-alignment for one-stage object detection,” IEEE Trans. Circuit Syst. Video Technol., vol. 34, p. 11, 2024.
|
| [95] |
H. Wang, T. Jia, Q. Wang, and W. Zuo, “Relation knowledge distillation by auxiliary learning for object detection,” IEEE Trans. Image Process., vol. 33, pp. 4796–4810, 2024. doi: 10.1109/TIP.2024.3445740
|
| [96] |
C. Ge, Y. Song, C. Ma, Y. Qi, and P. Luo, “Rethinking attentive object detection via neural attention learning,” IEEE Trans. Image Process., vol. 33, pp. 1726–1739, 2024. doi: 10.1109/TIP.2023.3251693
|
| [97] |
G. Zhang, Z. Luo, Y. Yu, K. Cui, and S. Lu, “Accelerating DETR convergence via semantic-aligned matching,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 939–948.
|
| [98] |
X. Dai, Y. Chen, J. Yang, P. Zhang, L. Yuan, and L. Zhang, “Dynamic detr: End-to-end object detection with dynamic attention,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 2968–2977.
|
| [99] |
T. Chen, S. Saxena, L. Li, D. J. Fleet, and G. E. Hinton, “Pix2seq: A language modeling framework for object detection,” in Proc. Int. Conf. Learn. Represent., 2022.
|
| [100] |
H. Zhang, F. Mao, M. Xue, G. Fang, Z. Feng, J. Song, and M. Song, “Knowledge amalgamation for object detection with transformers,” IEEE Trans. Image Process., vol. 32, pp. 2093–2106, 2023. doi: 10.1109/TIP.2023.3263105
|
| [101] |
H. Zhou, R. Yang, Y. Zhang, H. Duan, Y. Huang, R. Hu, X. Li, and Y. Zheng, “Unihead: Unifying multi-perception for detection heads,” IEEE Trans. Neural Netw. Learn. Syst., pp. 1–12, 2024.
|
| [102] |
X. Xie, C. Lang, S. Miao, G. Cheng, K. Li, and J. Han, “Mutual-assistance learning for object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, p. 12, 2023.
|
| [103] |
F. Li, H. Zhang, S. Liu, J. Guo, L. M. Ni, and L. Zhang, “Dn-detr: Accelerate detr training by introducing query denoising,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 4, pp. 2239–2251, 2024. doi: 10.1109/TPAMI.2023.3335410
|
| [104] |
Y. Chen, Z. Zhang, Y. Cao, L. Wang, S. Lin, and H. Hu, “RepPoints v2: Verification meets regression for object detection,” in Proc. Adv. Neural Inform. Process. Syst., 2020, p. 5621–5631.
|
| [105] |
L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y. Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwang, K.-W. Chang, and J. Gao, “Grounded language-image pre-training,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 10965–10975.
|
| [106] |
R. Li, C. He, S. Li, Y. Zhang, and L. Zhang, “Dynamask: Dynamic mask selection for instance segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2023, pp. 11279–11288.
|
| [107] |
C. Guo, B. Fan, Q. Zhang, S. Xiang, and C. Pan, “Augfpn: Improving multi-scale feature learning for object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 12592–12601.
|
| [108] |
D. Zhang, H. Zhang, J. Tang, M. Wang, X. Hua, and Q. Sun, “Feature pyramid transformer,” in Proc. Eur. Conf. Comput. Vis., vol. 12373, 2020, pp. 323–339.
|
| [109] |
J. Ma and B. Chen, “Dual refinement feature pyramid networks for object detection,” arXiv preprint arXiv: 2012.01733, 2020.
|
| [110] |
G. Zhao, W. Ge, and Y. Yu, “Graphfpn: Graph feature pyramid network for object detection,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 2743–2752.
|
| [111] |
J. Xie, Y. Pang, J. Nie, J. Cao, and J. Han, “Latent feature pyramid network for object detection,” IEEE Trans. Multimedia, vol. 25, pp. 2153–2163, 2023. doi: 10.1109/TMM.2022.3143707
|
| [112] |
L. Zhu, F. Lee, J. Cai, H. Yu, and Q. Chen, “An improved feature pyramid network for object detection,” Neurocomputing, vol. 483, pp. 127–139, 2022. doi: 10.1016/j.neucom.2022.02.016
|
| [113] |
G. Yang, J. Lei, Z. Zhu, S. Cheng, Z. Feng, and R. Liang, “AFPN: asymptotic feature pyramid network for object detection,” in IEEE Int. Conf. on Systems, Man, and Cybernetics, SMC, 2023, pp. 2184–2189.
|
| [114] |
Z. Yang, S. Liu, H. Hu, L. Wang, and S. Lin, “RepPoints: Point set representation for object detection,” in Proc. Int. Conf. Comput. Vis., 2019, pp. 9656–9665.
|

Figures(11) / Tables(10)






 DownLoad:
DownLoad: