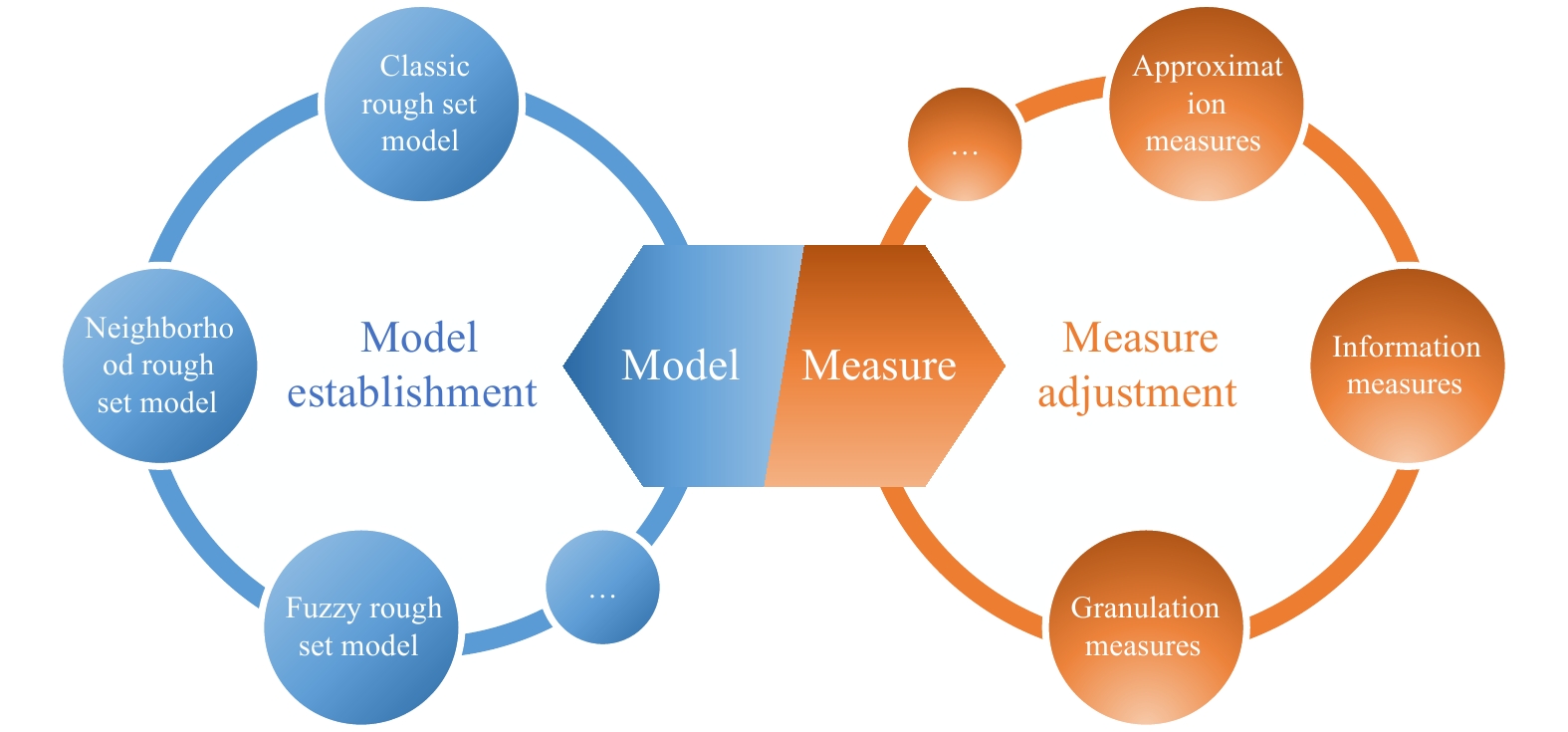
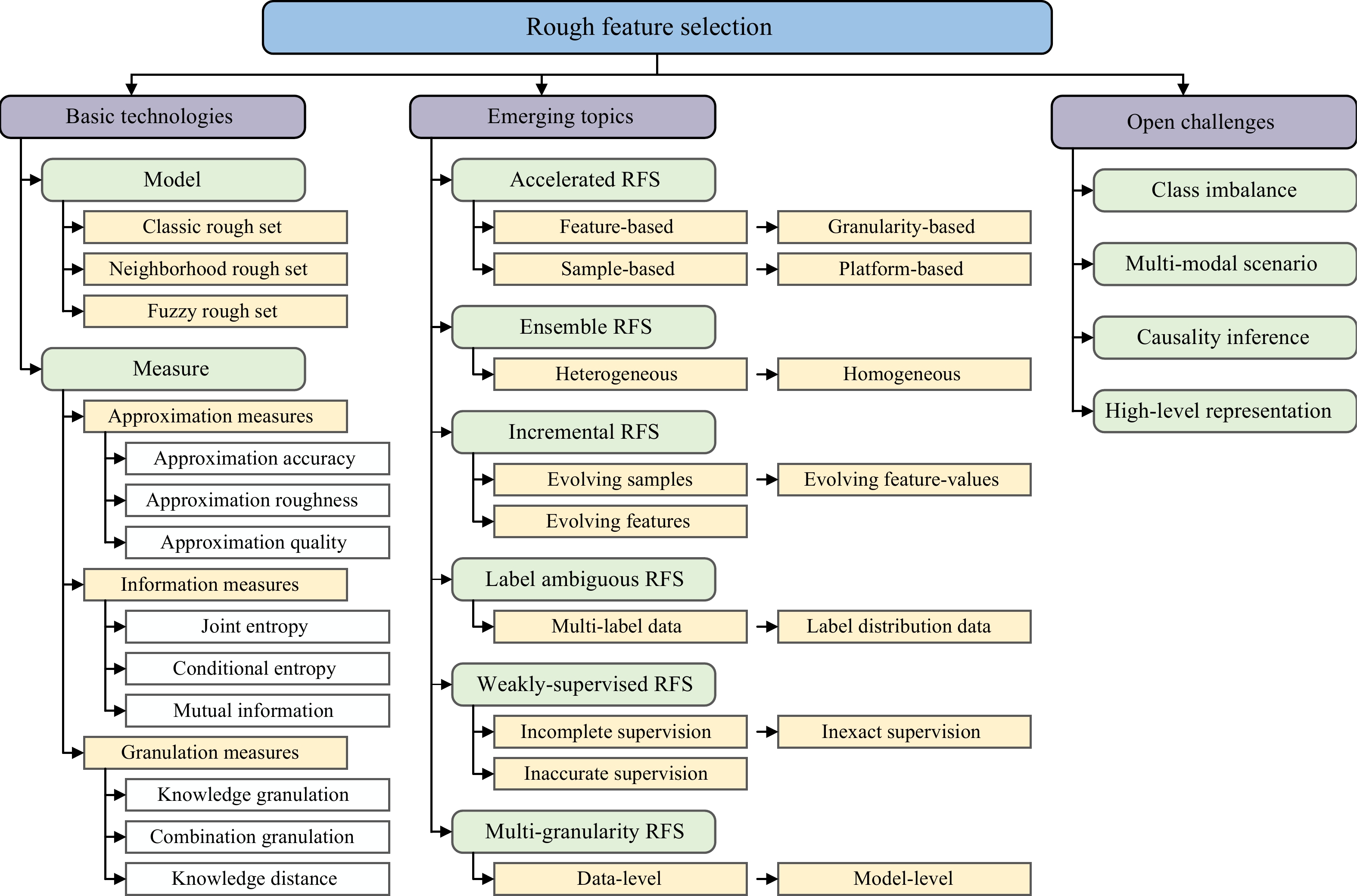
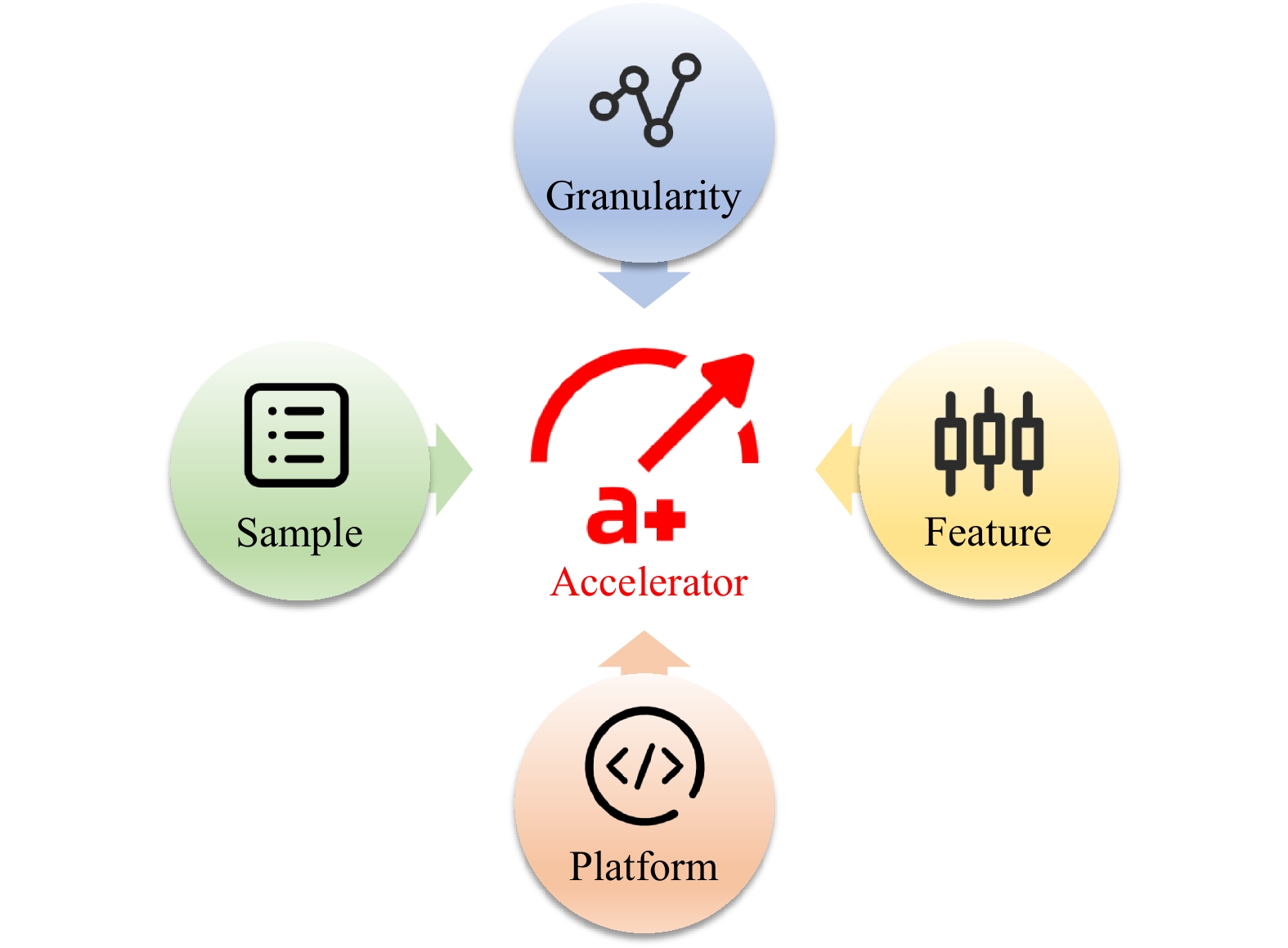
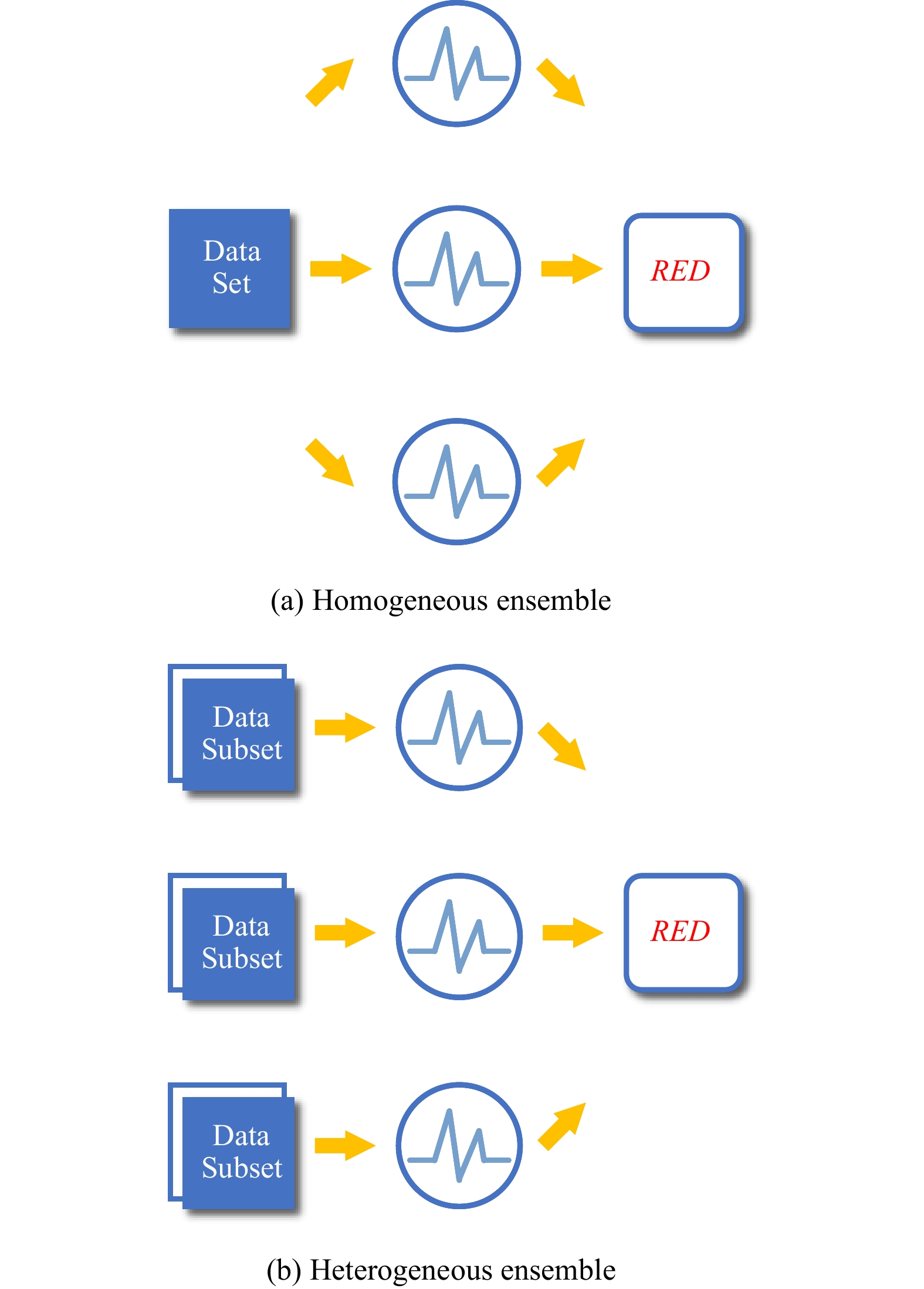
A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation

IEEE/CAA Journal of Automatica Sinica
| Citation: | K. Liu, X. Yang, W. Ding, H. Ju, T. Li, J. Wang, and T. Yin, “A survey on rough feature selection: Recent advances and challenges,” IEEE/CAA J. Autom. Sinica, 2025. doi: 10.1109/JAS.2025.125231

|

| [1] |
Y. Zhai, Y. Ong, and I. Tsang, “The emerging “big dimensionality”,” IEEE Computational Intelligence Magazine, vol. 9, pp. 14–26, 2014. doi: 10.1109/MCI.2014.2326099
|
| [2] |
D. Wu, P. Zhang, Y. He, and X. Luo, “MMLF: Multi-metric latent feature analysis for high-dimensional and incomplete data,” IEEE Trans. Services Computing, vol. 17, no. 2, pp. 575–588, 2024. doi: 10.1109/TSC.2023.3331570
|
| [3] |
X. Song, Y. Zhang, W. Zhang, C. He, Y. Hu, J. Wang, and D. Gong, “Evolutionary computation for feature selection in classification: A comprehensive survey of solutions, applications and challenges,” Swarm and Evolutionary Computation, vol. 90, p. 101661, 2024. doi: 10.1016/j.swevo.2024.101661
|
| [4] |
I. Guyon and A. Elisseeff, “An introduction to variable and feature selection,” Journal of Machine Learning Research, vol. 3, pp. 1157–1182, 2003.
|
| [5] |
Y. Gong, J. Zhou, Q. Wu, M. Zhou, and J. Wen, “A length-adaptive non-dominated sorting genetic algorithm for bi-objective high-dimensional feature selection,” IEEE/CAA Journal of Automatica Sinica, vol. 10, no. 9, pp. 1834–1844, 2023. doi: 10.1109/JAS.2023.123648
|
| [6] |
Z. Pawlak, “Rough sets,” Int. Journal of Computer and Information Sciences, vol. 11, pp. 341–356, 1982. doi: 10.1007/BF01001956
|
| [7] |
G. Yasmin, A. Das, J. Nayak, D. Pelusi, and W. Ding, “Graph based feature selection investigating boundary region of rough set for language identification,” Expert Systems with Applications, vol. 158, p. 113575, 2020. doi: 10.1016/j.eswa.2020.113575
|
| [8] |
Y. Qu, G. Yue, C. Shang, L. Yang, R. Zwiggelaar, and Q. Shen, “Multi-criterion mammographic risk analysis supported with multi-label fuzzy-rough feature selection,” Artificial Intelligence in Medicine, vol. 100, p. 101722, 2019. doi: 10.1016/j.artmed.2019.101722
|
| [9] |
M. Prasad, S. Tripathi, and K. Dahal, “An efficient feature selection based bayesian and rough set approach for intrusion detection,” Applied Soft Computing, vol. 87, p. 105980, 2020. doi: 10.1016/j.asoc.2019.105980
|
| [10] |
J. Wang, A. Hedar, S. Wang, and J. Ma, “Rough set and scatter search metaheuristic based feature selection for credit scoring,” Expert Systems with Applications, vol. 39, pp. 6123–6128, 2012. doi: 10.1016/j.eswa.2011.11.011
|
| [11] |
W. Qian, Y. Li, Q. Ye, S. Xia, J. Huang, and W. Ding, “Confidence-induced granular partial label feature selection via dependency and similarity,” IEEE Trans. Knowledge and Data Engineering, vol. 36, no. 11, pp. 5797–5810, 2024. doi: 10.1109/TKDE.2024.3405489
|
| [12] |
C. Wang, C. Wang, Y. Qian, and Q. Leng, “Feature selection based on weighted fuzzy rough sets,” IEEE Trans. Fuzzy Systems, vol. 32, no. 7, pp. 4027–4037, 2024. doi: 10.1109/TFUZZ.2024.3387571
|
| [13] |
C. Luo, S. Wang, T. Li, H. Chen, J. Lv, and Z. Yi, “Large-scale meta-heuristic feature selection based on bpso assisted rough hypercuboid approach,” IEEE Trans. Neural Networks and Learning Systems, vol. 34, no. 12, pp. 10 889–10 903, 2023. doi: 10.1109/TNNLS.2022.3171614
|
| [14] |
L. Kuncheva and Z. Hoare, “Error-dependency relationships for the naive bayes classifier with binary features,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 30, no. 4, pp. 735–740, 2008. doi: 10.1109/TPAMI.2007.70845
|
| [15] |
M. Banerjee and N. Pal, “Unsupervised feature selection with controlled redundancy (UFeSCoR),” IEEE Trans. Knowledge and Data Engineering, vol. 27, no. 12, pp. 3390–3403, 2015. doi: 10.1109/TKDE.2015.2455509
|
| [16] |
Y. Wang and L. Feng, “Hybrid feature selection using component co-occurrence based feature relevance measurement,” Expert Systems with Applications, vol. 102, pp. 83–99, 2018. doi: 10.1016/j.eswa.2018.01.041
|
| [17] |
Z. Zeng, H. Zhang, J. Zhang, and C. Yin, “A novel feature selection method considering feature interaction,” Pattern Recognition, vol. 48, pp. 2656–2666, 2015. doi: 10.1016/j.patcog.2015.02.025
|
| [18] |
A. Skowron and D. Ślȩzak, “Rough sets turn 40: From information systems to intelligent systems,” in Proc. the 17th Conf. on Computer Science and Intelligence Systems, 2022, pp. 23–34.
|
| [19] |
I. Düntsch and G. Gediga, “Uncertainty measures of rough set prediction,” Artificial Intelligence, vol. 106, pp. 109–137, 1998. doi: 10.1016/S0004-3702(98)00091-5
|
| [20] |
J. Guan and D. Bell, “Rough computational methods for information systems,” Artificial Intelligence, vol. 105, pp. 77–103, 1998. doi: 10.1016/S0004-3702(98)00090-3
|
| [21] |
J. Cai, J. Luo, S. Wang, and S. Yang, “Feature selection in machine learning: A new perspective,” Neurocomputing, vol. 300, pp. 70–79, 2018. doi: 10.1016/j.neucom.2017.11.077
|
| [22] |
L. Dash and H. Liu, “Feature selection for classification,” Intelligent data analysis, vol. 1, pp. 131–156, 1997. doi: 10.3233/IDA-1997-1302
|
| [23] |
G. Chandrashekar and F. Sahin, “A survey on feature selection methods,” Computers and Electrical Engineering, vol. 40, pp. 16–28, 2014. doi: 10.1016/j.compeleceng.2013.11.024
|
| [24] |
J. Ang, A. Mirzal, H. Haron, and H. Hamed, “Supervised, unsupervised, and semi-supervised feature selection: A review on gene selection,” IEEE/ACM Trans. Computational Biology and Bioinformatics, vol. 13, no. 5, pp. 971–989, 2016. doi: 10.1109/TCBB.2015.2478454
|
| [25] |
J. Li, K. Cheng, S. Wang, F. Morstatter, R. Trevino, J. Tang, and H. Liu, “Feature selection: A data perspective,” ACM Computing Surveys, vol. 50, p. 94, 2017.
|
| [26] |
B. Xue, M. Zhang, W. Browne, and X. Yao, “A survey on evolutionary computation approaches to feature selection,” IEEE Trans. Evolutionary Computation, vol. 20, no. 4, pp. 606–626, 2016. doi: 10.1109/TEVC.2015.2504420
|
| [27] |
R. Zhang, F. Nie, X. Li, and X. Wei, “Feature selection with multi-view data: A survey,” Information Fusion, vol. 50, pp. 158–167, 2019. doi: 10.1016/j.inffus.2018.11.019
|
| [28] |
T. Dokeroglu, A. Deniz, and H. Kiziloz, “A comprehensive survey on recent metaheuristics for feature selection,” Neurocomputing, vol. 494, pp. 269–296, 2022. doi: 10.1016/j.neucom.2022.04.083
|
| [29] |
W. Wei and J. Liang, “Information fusion in rough set theory: An overview,” Information Fusion, vol. 48, pp. 107–118, 2019. doi: 10.1016/j.inffus.2018.08.007
|
| [30] |
P. Zhang, T. Li, G. Wang, C. Luo, H. Chen, J. Zhang, D. Wang, and Z. Yu, “Multi-source information fusion based on rough set theory: A review,” Information Fusion, vol. 68, pp. 85–117, 2021. doi: 10.1016/j.inffus.2020.11.004
|
| [31] |
D. Liu, X. Yang, and T. Li, “Three-way decisions: Beyond rough sets and granular computing,” Int. Journal of Machine Learning and Cybernetics, vol. 11, pp. 989–1002, 2020. doi: 10.1007/s13042-020-01095-6
|
| [32] |
A. Skowron and S. Dutta, “Rough sets: Past, present, and future,” Natural Computing, vol. 17, pp. 855–876, 2018. doi: 10.1007/s11047-018-9700-3
|
| [33] |
D. Acharjya and A. Abraham, “Rough computing–A review of abstraction, hybridization and extent of applications,” Engineering Applications of Artificial Intelligence, vol. 96, p. 103924, 2020. doi: 10.1016/j.engappai.2020.103924
|
| [34] |
K. Thangavel and A. Pethalakshmi, “Dimensionality reduction based on rough set theory: A review,” Applied Soft Computing, vol. 9, pp. 1–12, 2009. doi: 10.1016/j.asoc.2008.05.006
|
| [35] |
R. Swiniarski and A. Skowron, “Rough set methods in feature selection and recognition,” Pattern Recognition Letters, vol. 24, pp. 833–849, 2003. doi: 10.1016/S0167-8655(02)00196-4
|
| [36] |
Z. Yuan, H. Chen, P. Xie, P. Zhang, J. Liu, and T. Li, “Attribute reduction methods in fuzzy rough set theory: An overview, comparative experiments, and new directions,” Applied Soft Computing, vol. 107, p. 107353, 2021. doi: 10.1016/j.asoc.2021.107353
|
| [37] |
Y. Yao and S. Wong, “A decision theoretic framework for approximating concepts,” Int. Journal of Man-Machine Studies, vol. 37, no. 6, pp. 793–809, 1992. doi: 10.1016/0020-7373(92)90069-W
|
| [38] |
F. Feng, X. Liu, V. Leoreanu-Fotea, and Y. Jun, “Soft sets and soft rough sets,” Information Sciences, vol. 181, no. 6, pp. 1125–1137, 2011. doi: 10.1016/j.ins.2010.11.004
|
| [39] |
N. Azam and J. Yao, “Interpretation of equilibria in game-theoretic rough sets,” Information Sciences, vol. 295, pp. 586–599, 2015. doi: 10.1016/j.ins.2014.10.046
|
| [40] |
S. Greco, B. Matarazzo, and R. Slowinski, “Parameterized rough set model using rough membership and bayesian confirmation measures,” Int. Journal of Approximate Reasoning, vol. 49, no. 2, pp. 285–300, 2008. doi: 10.1016/j.ijar.2007.05.018
|
| [41] |
C. Liu, D. Miao, and N. Zhang, “Graded rough set model based on two universes and its properties,” Knowledge-Based Systems, vol. 33, pp. 65–72, 2012. doi: 10.1016/j.knosys.2012.02.012
|
| [42] |
B. Davvaz, “A short note on algebraic t-rough sets,” Information Sciences, vol. 178, no. 16, pp. 3247–3252, 2008. doi: 10.1016/j.ins.2008.03.014
|
| [43] |
T. Niu, Z. Wang, W. Li, K. Li, Y. Li, G. Xu, and B. Li, “Learning trustworthy model from noisy labels based on rough set for surface defect detection,” Applied Soft Computing, vol. 165, p. 112138, 2024. doi: 10.1016/j.asoc.2024.112138
|
| [44] |
W. Zhu and F. Wang, “On three types of covering-based rough sets,” IEEE Trans. Knowledge and Data Engineering, vol. 19, no. 8, pp. 1131–1144, 2007. doi: 10.1109/TKDE.2007.1044
|
| [45] |
W. Li, H. Zhou, W. Xu, X. Wang, and W. Pedrycz, “Interval dominance-based feature selection for interval-valued ordered data,” IEEE Trans. Neural Networks and Learning Systems, vol. 34, no. 10, pp. 6898–6912, 2023. doi: 10.1109/TNNLS.2022.3184120
|
| [46] |
W. Ziarko, “Variable precision rough set model,” Journal of Computer and System Sciences, vol. 46, pp. 39–59, 1993. doi: 10.1016/0022-0000(93)90048-2
|
| [47] |
Q. Hu, D. Yu, and Z. Xie, “Neighborhood classifiers,” Expert Systems with Applications, vol. 34, pp. 866–876, 2008. doi: 10.1016/j.eswa.2006.10.043
|
| [48] |
S. An, X. Guo, C. Wang, G. Guo, and J. Dai, “A soft neighborhood rough set model and its applications,” Information Sciences, vol. 624, pp. 185–199, 2023. doi: 10.1016/j.ins.2022.12.074
|
| [49] |
M. Hu, E. Tsang, Y. Guo, D. Chen, and W. Xu, “A novel approach to attribute reduction based on weighted neighborhood rough sets,” Knowledge-Based Systems, vol. 220, p. 106908, 2021. doi: 10.1016/j.knosys.2021.106908
|
| [50] |
H. Ju, W. Ding, Z. Shi, J. Huang, J. Yang, and X. Yang, “Attribute reduction with personalized information granularity of nearest mutual neighbors,” Information Sciences, vol. 613, pp. 114–138, 2022. doi: 10.1016/j.ins.2022.09.006
|
| [51] |
G. Lin, Y. Qian, and J. Li, “NMGRS: Neighborhood-based multigranulation rough sets,” Int. Journal of Approximate Reasoning, vol. 53, no. 7, pp. 1080–1093, 2012. doi: 10.1016/j.ijar.2012.05.004
|
| [52] |
K. Liu, X. Yang, H. Yu, H. Fujita, X. Chen, and D. Liu, “Supervised information granulation strategy for attribute reduction,” Int. Journal of Machine Learning and Cybernetics, vol. 11, pp. 2149–2163, 2020. doi: 10.1007/s13042-020-01107-5
|
| [53] |
T. Thuy and S. Wongthanavasu, “A novel feature selection method for high-dimensional mixed decision tables,” IEEE Trans. Neural Networks and Learning Systems, vol. 33, no. 7, pp. 3024–3037, 2022. doi: 10.1109/TNNLS.2020.3048080
|
| [54] |
C. Wang, Y. Shi, X. Fan, and M. Shao, “Attribute reduction based on k-nearest neighborhood rough sets,” Int. Journal of Approximate Reasoning, vol. 106, pp. 18–31, 2019. doi: 10.1016/j.ijar.2018.12.013
|
| [55] |
S. Xia, H. Zhang, W. Li, G. Wang, E. Giem, and Z. Chen, “GBNRS: A novel rough set algorithm for fast adaptive attribute reduction in classification,” IEEE Trans. Knowledge and Data Engineering, vol. 34, no. 3, pp. 1231–1242, 2022. doi: 10.1109/TKDE.2020.2997039
|
| [56] |
X. Yang, S. Liang, H. Yu, S. Gao, and Y. Qian, “Pseudo-label neighborhood rough set: Measures and attribute reductions,” Int. Journal of Approximate Reasoning, vol. 105, pp. 112–129, 2019. doi: 10.1016/j.ijar.2018.11.010
|
| [57] |
X. Yang, H. Chen, T. Li, J. Wan, and B. Sang, “Neighborhood rough sets with distance metric learning for feature selection,” Knowledge-Based Systems, vol. 224, p. 107076, 2021. doi: 10.1016/j.knosys.2021.107076
|
| [58] |
D. Dubois and H. Prade, “Rough fuzzy sets and fuzzy rough sets,” Int. Journal of General Systems, vol. 17, pp. 191–209, 1990. doi: 10.1080/03081079008935107
|
| [59] |
D. Chen and Y. Yang, “Attribute reduction for heterogeneous data based on the combination of classical and fuzzy rough set models,” IEEE Trans. Fuzzy Systems, vol. 22, pp. 1325–1334, 2014. doi: 10.1109/TFUZZ.2013.2291570
|
| [60] |
J. Chen, Y. Lin, J. Mi, S. Li, and W. Ding, “A spectral feature selection approach with kernelized fuzzy rough sets,” IEEE Trans. Fuzzy Systems, vol. 30, no. 8, pp. 2886–2901, 2022. doi: 10.1109/TFUZZ.2021.3096212
|
| [61] |
J. Dai, X. Zou, and W. Wu, “Novel fuzzy β-covering rough set models and their applications,” Information Sciences, vol. 608, pp. 286–312, 2022. doi: 10.1016/j.ins.2022.06.060
|
| [62] |
P. Maji and P. Garai, “It2 fuzzy-rough sets and max relevance-max significance criterion for attribute selection,” IEEE Trans. Cybernetics, vol. 45, no. 8, pp. 1657–1668, 2015. doi: 10.1109/TCYB.2014.2357892
|
| [63] |
J. Yang, X. Qin, G. Wang, Q. Zhang, and D. Wu, “Attribute reduction for hierarchical classification based on improved fuzzy rough set,” Information Sciences, vol. 677, p. 120900, 2024. doi: 10.1016/j.ins.2024.120900
|
| [64] |
A. Theerens, O. Lenz, and C. Cornelis, “Choquet-based fuzzy rough sets,” Int. Journal of Approximate Reasoning, vol. 146, pp. 62–78, 2022. doi: 10.1016/j.ijar.2022.04.006
|
| [65] |
N. Thuy and S. Wongthanavasu, “Hybrid filter-wrapper attribute selection with alpha-level fuzzy rough sets,” Expert Systems With Applications, vol. 193, p. 116428, 2022. doi: 10.1016/j.eswa.2021.116428
|
| [66] |
P. Jain, A. Tiwari, and T. Som, “A fitting model based intuitionistic fuzzy rough feature selection,” Engineering Applications of Artificial Intelligence, vol. 89, p. 103421, 2020. doi: 10.1016/j.engappai.2019.103421
|
| [67] |
C. Wang, Y. Qian, W. Ding, and X. Fan, “Feature selection with fuzzy-rough minimum classification rrror criterion,” IEEE Trans. Fuzzy Systems, vol. 30, no. 8, pp. 2930–2942, 2022. doi: 10.1109/TFUZZ.2021.3097811
|
| [68] |
X. Zhang and J. Jiang, “Measurement, modeling, reduction of decision-theoretic multigranulation fuzzy rough sets based on three-way decisions,” Information Sciences, vol. 607, pp. 1550–1582, 2022. doi: 10.1016/j.ins.2022.05.122
|
| [69] |
M. Aggarwal, “Rough information set and its applications in decision making,” IEEE Trans. Fuzzy Systems, vol. 25, no. 2, pp. 265–276, 2017. doi: 10.1109/TFUZZ.2017.2670551
|
| [70] |
S. An, E. Zhao, C. Wang, G. Guo, S. Zhao, and P. Li, “Relative fuzzy rough approximations for feature selection and classification,” IEEE Trans. Cybernetics, vol. 53, no. 4, pp. 2200–2210, 2023. doi: 10.1109/TCYB.2021.3112674
|
| [71] |
Y. Guo, M. Hu, X. Wang, E. Tsang, D. Chen, and W. Xu, “A robust approach to attribute reduction based on double fuzzy consistency measure,” Knowledge-Based Systems, vol. 253, p. 109585, 2022. doi: 10.1016/j.knosys.2022.109585
|
| [72] |
P. Maji, “A rough hypercuboid approach for feature selection in approximation spaces,” IEEE Trans. Knowledge and Data Engineering, vol. 26, no. 1, pp. 16–29, 2014. doi: 10.1109/TKDE.2012.242
|
| [73] |
Z. Ma, J. Mi, Y. Lin, and J. Li, “Boundary region-based variable precision covering rough set models,” Information Sciences, vol. 608, pp. 1524–1540, 2022. doi: 10.1016/j.ins.2022.07.048
|
| [74] |
F. Jiang, Y. Sui, and L. Zhou, “A relative decision entropy-based feature selection approach,” Pattern Recognition, vol. 48, pp. 2151–2163, 2015. doi: 10.1016/j.patcog.2015.01.023
|
| [75] |
N. Parthalain, Q. Shen, and R. Jensen, “A distance measure approach to exploring the rough set boundary region for attribute reduction,” IEEE Trans. Knowledge and Data Engineering, vol. 22, no. 3, pp. 305–317, 2010. doi: 10.1109/TKDE.2009.119
|
| [76] |
B. Sang, H. Chen, L. Yang, J. Wan, T. Li, and W. Xu, “Feature selection considering multiple correlations based on soft fuzzy dominance rough sets for monotonic classification,” IEEE Trans. Fuzzy Systems, vol. 30, pp. 5181–5195, 2022. doi: 10.1109/TFUZZ.2022.3169625
|
| [77] |
A. Tan, W. Wu, Y. Qian, J. Liang, J. Chen, and J. Li, “Intuitionistic fuzzy rough set-based granular structures and attribute subset selection,” IEEE Trans. Fuzzy Systems, vol. 27, no. 3, pp. 527–539, 2019. doi: 10.1109/TFUZZ.2018.2862870
|
| [78] |
C. Wang, Y. Qi, M. Shao, Q. Hu, D. Chen, Y. Qian, and Y. Lin, “A fitting model for feature selection with fuzzy rough sets,” IEEE Trans. Fuzzy Systems, vol. 25, no. 4, pp. 741–753, 2017. doi: 10.1109/TFUZZ.2016.2574918
|
| [79] |
C. Gao, Z. Lai, J. Zhou, C. Zhao, and D. Miao, “Maximum decision entropy-based attribute reduction in decision-theoretic rough set model,” Knowledge-Based Systems, vol. 143, pp. 179–191, 2018. doi: 10.1016/j.knosys.2017.12.014
|
| [80] |
Y. Huang, K. Guo, X. Yi, Z. Li, and T. Li, “Matrix representation of the conditional entropy for incremental feature selection on multi-source data,” Information Sciences, vol. 591, pp. 263–286, 2022. doi: 10.1016/j.ins.2022.01.037
|
| [81] |
P. Maji and S. Pal, “Fuzzy-rough sets for information measures and selection of relevant genes from microarray data,” IEEE Trans. Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 40, no. 3, pp. 741–752, 2010. doi: 10.1109/TSMCB.2009.2028433
|
| [82] |
J. Pal, S. Ray, S. Cho, and S. Pal, “Fuzzy-rough entropy measure and histogram based patient selection for miRNA ranking in cancer,” IEEE/ACM Trans. Computational Biology and Bioinformatics, vol. 15, no. 2, pp. 659–672, 2018. doi: 10.1109/TCBB.2016.2623605
|
| [83] |
B. Sang, H. Chen, L. Yang, T. Li, and W. Xu, “Incremental feature selection using a conditional entropy based on fuzzy dominance neighborhood rough sets,” IEEE Trans. Fuzzy Systems, vol. 30, pp. 1683–1697, 2022. doi: 10.1109/TFUZZ.2021.3064686
|
| [84] |
J. Wan, H. Chen, T. Li, Z. Yuan, J. Liu, and W. Huang, “Interactive and complementary feature selection via fuzzy multigranularity uncertainty measures,” IEEE Trans. Cybernetics, vol. 53, pp. 1208–1221, 2023. doi: 10.1109/TCYB.2021.3112203
|
| [85] |
W. Xu, K. Yuan, W. Li, and W. Ding, “An emerging fuzzy feature selection method using composite entropy-based uncertainty measure and data distribution,” IEEE Trans. Emerging Topics in Computational Intelligence, vol. 7, pp. 76–88, 2023. doi: 10.1109/TETCI.2022.3171784
|
| [86] |
Z. Yuan, H. Chen, T. Li, X. Zhang, and B. Sang, “Multigranulation relative entropy-based mixed attribute outlier detection in neighborhood systems,” IEEE Trans. Systems, Man, and Cybernetics: Systems, vol. 52, pp. 5175–5187, 2022. doi: 10.1109/TSMC.2021.3119119
|
| [87] |
D. Xia, G. Wang, Q. Zhang, J. Yang, and S. Xia, “Three-way approximations fusion with granular-ball computing to guide multigranularity fuzzy entropy for feature selection,” IEEE Trans. Fuzzy Systems, vol. 32, no. 10, pp. 5963–5977, 2024. doi: 10.1109/TFUZZ.2024.3436086
|
| [88] |
X. Zhang, C. Mei, D. Chen, and J. Li, “Feature selection in mixed data: A method using a novel fuzzy rough set-based information entropy,” Pattern Recognition, vol. 56, pp. 1–15, 2016. doi: 10.1016/j.patcog.2016.02.013
|
| [89] |
J. Liang, Z. Shi, D. Li, and M. Wierman, “The information entropy, rough entropy and knowledge granulation in incomplete information systems,” Int. Journal of General Systems, vol. 35, pp. 641–654, 2006. doi: 10.1080/03081070600687668
|
| [90] |
J. Liang, J. Wang, and Y. Qian, “A new measure of uncertainty based on knowledge granulation for rough sets,” Information Sciences, vol. 179, pp. 458–470, 2009. doi: 10.1016/j.ins.2008.10.010
|
| [91] |
J. Dai and H. Tian, “Entropy measures and granularity measures for set-valued information systems,” Information Sciences, vol. 240, pp. 72–82, 2013. doi: 10.1016/j.ins.2013.03.045
|
| [92] |
Y. Qian, J. Liang, and C. Dang, “Knowledge structure, knowledge granulation and knowledge distance in a knowledge base,” Int. Journal of Approximate Reasoning, vol. 50, pp. 174–188, 2009. doi: 10.1016/j.ijar.2008.08.004
|
| [93] |
Y. Qian and J. Liang, “Combination entropy and combination granulation in rough set theory,” Int. Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, vol. 16, pp. 179–193, 2008. doi: 10.1142/S0218488508005121
|
| [94] |
W. Xu, X. Zhang, and W. Zhang, “Knowledge granulation, knowledge entropy and knowledge uncertainty measure in ordered information systems,” Applied Soft Computing, vol. 9, pp. 1244–1251, 2009. doi: 10.1016/j.asoc.2009.03.007
|
| [95] |
J. Yang, G. Wang, and Q. Zhang, “Knowledge distance measure in multigranulation spaces of fuzzy equivalence relations,” Information Sciences, vol. 448-449, pp. 18–35, 2018. doi: 10.1016/j.ins.2018.03.026
|
| [96] |
D. Xia, G. Wang, J. Yang, Q. Zhang, and S. Li, “Local knowledge distance for rough approximation measure in multi-granularity spaces,” Information Sciences, vol. 605, pp. 413–432, 2022. doi: 10.1016/j.ins.2022.05.003
|
| [97] |
H. Wang and H. Yue, “Entropy measures and granularity measures for interval and set-valued information systems,” Soft Computing, vol. 20, pp. 3489–3495, 2016. doi: 10.1007/s00500-015-1954-4
|
| [98] |
H. Ge and C. Yang, “New measures of uncertainty based on the granularity distribution of approximation sets,” Artificial Intelligence Review, vol. 55, pp. 3801–3831, 2022. doi: 10.1007/s10462-021-10089-x
|
| [99] |
L. Zadeh, “Fuzzy sets,” Information and Control, vol. 8, pp. 338–353, 1965. doi: 10.1016/S0019-9958(65)90241-X
|
| [100] |
R. Jensen and Q. Shen, “Fuzzy-rough sets assisted attribute selection,” IEEE Trans. Fuzzy Systems, vol. 15, no. 1, pp. 73–89, 2007. doi: 10.1109/TFUZZ.2006.889761
|
| [101] |
Y. Yang, D. Chen, Z. Ji, X. Zhang, and L. Dong, “A two-way accelerator for feature selection using a monotonic fuzzy conditional entropy,” Fuzzy Sets and Systems, vol. 483, p. 108916, 2024. doi: 10.1016/j.fss.2024.108916
|
| [102] |
Y. Yang, D. Chen, X. Zhang, Z. Ji, and Y. Zhang, “Incremental feature selection by sample selection and feature-based accelerator,” Applied Soft Computing, vol. 121, p. 108800, 2022. doi: 10.1016/j.asoc.2022.108800
|
| [103] |
P. Maji and S. Paul, “Rough-fuzzy clustering for grouping functionally similar genes from microarray data,” IEEE/ACM Trans. Computational Biology and Bioinformatics, vol. 10, pp. 286–299, 2013. doi: 10.1109/TCBB.2012.103
|
| [104] |
Y. Chen, K. Liu, J. Song, H. Fujita, X. Yang, and Y. Qian, “Attribute group for attribute reduction,” Information Sciences, vol. 535, pp. 64–80, 2020. doi: 10.1016/j.ins.2020.05.010
|
| [105] |
X. Yang, M. Li, H. Fujita, D. Liu, and T. Li, “Incremental rough reduction with stable attribute group,” Information Sciences, vol. 589, pp. 283–299, 2022. doi: 10.1016/j.ins.2021.12.119
|
| [106] |
Y. Qian, J. Liang, W. Pedrycz, and C. Dang, “Positive approximation: An accelerator for attribute reduction in rough set theory,” Artificial Intelligence, vol. 174, pp. 597–618, 2010. doi: 10.1016/j.artint.2010.04.018
|
| [107] |
Y. Liu, W. Huang, Y. Jiang, and Z. Zeng, “Quick attribute reduct algorithm for neighborhood rough set model,” Information Sciences, vol. 271, pp. 65–81, 2014. doi: 10.1016/j.ins.2014.02.093
|
| [108] |
K. Liu, T. Li, X. Yang, X. Yang, D. Liu, P. Zhang, and J. Wang, “Granular cabin: An efficient solution to neighborhood learning in big data,” Information Sciences, vol. 583, pp. 189–201, 2022. doi: 10.1016/j.ins.2021.11.034
|
| [109] |
Y. Fang, X. Cao, X. Wang, and F. Min, “Three-way sampling for rapid attribute reduction,” Information Sciences, vol. 609, pp. 26–45, 2022. doi: 10.1016/j.ins.2022.07.063
|
| [110] |
X. Zhang, C. Mei, D. Chen, and Y. Yang, “A fuzzy rough set-based feature selection method using representative instances,” Knowledge-Based Systems, vol. 151, pp. 216–229, 2018. doi: 10.1016/j.knosys.2018.03.031
|
| [111] |
Y. Lin, J. Li, P. Lin, G. Lin, and J. Chen, “Feature selection via neighborhood multi-granulation fusion,” Knowledge-Based Systems, vol. 67, pp. 162–168, 2014. doi: 10.1016/j.knosys.2014.05.019
|
| [112] |
Z. Jiang, X. Yang, H. Yu, D. Liu, P. Wang, and Y. Qian, “Accelerator for multi-granularity attribute reduction,” Knowledge-Based Systems, vol. 177, pp. 145–158, 2019. doi: 10.1016/j.knosys.2019.04.014
|
| [113] |
K. Liu, X. Yang, H. Fujita, D. Liu, X. Yang, and Y. Qian, “An efficient selector for multi-granularity attribute reduction,” Information Sciences, vol. 505, pp. 457–472, 2019. doi: 10.1016/j.ins.2019.07.051
|
| [114] |
K. Liu, T. Li, X. Yang, H. Ju, X. Yang, and D. Liu, “Hierarchical neighborhood entropy based multi-granularity attribute reduction with application to gene prioritization,” Int. Journal of Approximate Reasoning, vol. 148, pp. 57–67, 2022. doi: 10.1016/j.ijar.2022.05.011
|
| [115] |
X. Rao, K. Liu, J. Song, X. Yang, and Y. Qian, “Gaussian kernel fuzzy rough based attribute reduction: An acceleration approach,” Journal of Intelligent and Fuzzy Systems, vol. 39, pp. 679–695, 2020. doi: 10.3233/JIFS-191633
|
| [116] |
L. Kong, W. Qu, J. Yu, H. Zuo, G. Chen, F. Xiong, S. Pan, S. Lin, and M. Qiu, “Distributed feature selection for big data using fuzzy rough sets,” IEEE Trans. Fuzzy Systems, vol. 28, pp. 846–857, 2020. doi: 10.1109/TFUZZ.2019.2955894
|
| [117] |
Z. Su, Q. Hu, and T. Denoeux, “A distributed rough evidential k-nn classifier: Integrating feature reduction and classification,” IEEE Trans. Fuzzy Systems, vol. 29, pp. 2322–2335, 2021. doi: 10.1109/TFUZZ.2020.2998502
|
| [118] |
C. Luo, S. Wang, T. Li, H. Chen, J. Lv, and Z. Yi, “Spark rough hypercuboid approach for scalable feature selection,” IEEE Trans. Knowledge and Data Engineering, vol. 35, no. 3, pp. 3130–3144, 2023.
|
| [119] |
Y. Chen, W. Ding, H. Ju, J. Huang, and T. Yin, “A distributed attribute reduction based on neighborhood evidential conflict with apache spark,” Information Sciences, vol. 668, p. 120521, 2024. doi: 10.1016/j.ins.2024.120521
|
| [120] |
L. Yin, L. Qin, Z. Jiang, and X. Xu, “A fast parallel attribute reduction algorithm using apache spark,” Knowledge-Based Systems, vol. 212, p. 106582, 2021. doi: 10.1016/j.knosys.2020.106582
|
| [121] |
Y. Chen, X. Yang, J. Li, P. Wang, and Y. Qian, “Fusing attribute reduction accelerators,” Information Sciences, vol. 587, pp. 354–370, 2022. doi: 10.1016/j.ins.2021.12.047
|
| [122] |
J. Liang, J. Mi, W. Wei, and F. Wang, “An accelerator for attribute reduction based on perspective of objects and attributes,” Knowledge-Based Systems, vol. 44, pp. 90–100, 2013. doi: 10.1016/j.knosys.2013.01.027
|
| [123] |
V. Bolón-Canedo and A. Alonso-Betanzos, “Ensembles for feature selection: A review and future trends,” Information Fusion, vol. 52, pp. 1–12, 2019. doi: 10.1016/j.inffus.2018.11.008
|
| [124] |
Q. Hu, D. Yu, Z. Xie, and X. Li, “EROS: Ensemble rough subspaces,” Pattern Recognition, vol. 40, pp. 3728–3739, 2007. doi: 10.1016/j.patcog.2007.04.022
|
| [125] |
P. Zhu, Q. Hu, Y. Han, C. Zhang, and Y. Du, “Combining neighborhood separable subspaces for classification via sparsity regularized optimization,” Information Sciences, vol. 370-371, pp. 270–287, 2016. doi: 10.1016/j.ins.2016.08.004
|
| [126] |
R. Bania and A. Halder, “R-HEFS: Rough set based heterogeneous ensemble feature selection method for medical data classification,” Artificial Intelligence In Medicine, vol. 114, p. 102049, 2021. doi: 10.1016/j.artmed.2021.102049
|
| [127] |
C. Gao, J. Zhou, D. Miao, J. Wen, and X. Yue, “Three-way decision with co-training for partially labeled data,” Information Sciences, vol. 544, pp. 500–518, 2021. doi: 10.1016/j.ins.2020.08.104
|
| [128] |
Y. Guo, L. Jiao, S. Wang, S. Wang, F. Liu, K. Rong, and T. Xiong, “A novel dynamic rough subspace based selective ensemble,” Pattern Recognition, vol. 48, pp. 1638–1652, 2015. doi: 10.1016/j.patcog.2014.11.001
|
| [129] |
D. Chen and S. Zhao, “Local reduction of decision system with fuzzy rough sets,” Fuzzy Sets and Systems, vol. 161, pp. 1871–1883, 2010. doi: 10.1016/j.fss.2009.12.010
|
| [130] |
X. Yang and Y. Yao, “Ensemble selector for attribute reduction,” Applied Soft Computing, vol. 70, pp. 1–11, 2018. doi: 10.1016/j.asoc.2018.05.013
|
| [131] |
D. Ślȩzak, M. Grzegorowski, A. Janusz, M. Kozielski, S. Nguyen, M. Sikora, S. Stawicki, and L. Wróbel, “A framework for learning and embedding multi-sensor forecasting models into a decision support system: A case study of methane concentration in coal mines,” Information Sciences, vol. 451-452, pp. 112–133, 2019.
|
| [132] |
Y. Chen, P. Wang, X. Yang, and H. Yu, “BEE: Towards a robust attribute reduction,” Int. Journal of Machine Learning and Cybernetics, p. 10.1007/s13 042–022–01 633–4, 2022.
|
| [133] |
E. Sivasankar, C. Selvi, and S. Mahalakshmi, “Rough set-based feature selection for credit risk prediction using weight-adjusted boosting ensemble method,” Soft Computing, vol. 24, pp. 3975–3988, 2020. doi: 10.1007/s00500-019-04167-0
|
| [134] |
D. Wu, Y. He, X. Luo, and M. Zhou, “A latent factor analysis-based approach to online sparse streaming feature selection,” IEEE Trans. Systems, Man, and Cybernetics: Systems, vol. 52, no. 11, pp. 6744–6758, 2022. doi: 10.1109/TSMC.2021.3096065
|
| [135] |
D. You, H. Yan, J. Xiao, Z. Chen, D. Wu, L. Shen, and X. Wu, “Online learning for data streams with incomplete features and labels,” IEEE Trans. Knowledge and Data Engineering, vol. 36, no. 9, pp. 4820–4834, 2024. doi: 10.1109/TKDE.2024.3374357
|
| [136] |
R. Xu, D. Wu, and X. Luo, “Online sparse streaming feature selection via decision risk,” in 2023 IEEE Int. Conf. on Systems, Man, and Cybernetics, 2023, pp. 4190–4195.
|
| [137] |
A. Das, S. Sengupta, and S. Bhattacharyya, “A group incremental feature selection for classification using rough set theory based genetic algorithm,” Applied Soft Computing, vol. 65, pp. 400–411, 2018. doi: 10.1016/j.asoc.2018.01.040
|
| [138] |
B. Sang, H. Chen, T. Li, W. Xu, and H. Yu, “Incremental approaches for heterogeneous feature selection in dynamic ordered data,” Information Sciences, vol. 541, pp. 475–501, 2020. doi: 10.1016/j.ins.2020.06.051
|
| [139] |
W. Wei, X. Wu, J. Liang, J. Cui, and Y. Sun, “Discernibility matrix based incremental attribute reduction for dynamic data,” Knowledge-Based Systems, vol. 140, pp. 142–157, 2018. doi: 10.1016/j.knosys.2017.10.033
|
| [140] |
L. Yang, K. Qin, B. Sang, and C. Fu, “A novel incremental attribute reduction by using quantitative dominance-based neighborhood self-information,” Knowledge-Based Systems, vol. 261, p. 110200, 2023. doi: 10.1016/j.knosys.2022.110200
|
| [141] |
C. Zhang, J. Dai, and J. Chen, “Knowledge granularity based incremental attribute reduction for incomplete decision systems,” Int. Journal of Machine Learning and Cybernetics, vol. 11, pp. 1141–1157, 2020. doi: 10.1007/s13042-020-01089-4
|
| [142] |
Y. Lin, Q. Hu, J. Liu, J. Li, and X. Wu, “Streaming feature selection for multilabel learning based on fuzzy mutual information,” IEEE Trans. Fuzzy Systems, vol. 25, pp. 1491–1507, 2017. doi: 10.1109/TFUZZ.2017.2735947
|
| [143] |
J. Liu, Y. Lin, Y. Li, W. Weng, and S. Wu, “Online multi-label streaming feature selection based on neighborhood rough set,” Pattern Recognition, vol. 84, pp. 273–287, 2018. doi: 10.1016/j.patcog.2018.07.021
|
| [144] |
P. Zhou, Y. Zhang, P. Li, and X. Wu, “General assembly framework for online streaming feature selection via rough set models,” Expert Systems With Applications, vol. 204, p. 117520, 2022. doi: 10.1016/j.eswa.2022.117520
|
| [145] |
C. Luo, S. Wang, T. Li, H. Chen, J. Lv, and Z. Yi, “RHDOFS: A distributed online algorithm towards scalable streaming feature selection,” IEEE Trans. Parallel and Distributed Systems, vol. 34, pp. 1830–1847, 2023. doi: 10.1109/TPDS.2023.3265974
|
| [146] |
A. Zeng, T. Li, D. Liu, J. Zhang, and H. Chen, “A fuzzy rough set approach for incremental feature selection on hybrid information systems,” Fuzzy Sets and Systems, vol. 258, pp. 39–60, 2015. doi: 10.1016/j.fss.2014.08.014
|
| [147] |
M. Cai, Q. Li, and J. Ma, “Knowledge reduction of dynamic covering decision information systems caused by variations of attribute values,” Int. Journal of Machine Learning and Cybernetics, vol. 8, pp. 1131–l1144, 2017. doi: 10.1007/s13042-015-0484-9
|
| [148] |
G. Lang, Q. Li, and T. Yang, “An incremental approach to attribute reduction of dynamic set-valued information systems,” Int. Journal of Machine Learning and Cybernetics, vol. 5, pp. 775–788, 2014. doi: 10.1007/s13042-013-0225-x
|
| [149] |
W. Shu and H. Shen, “Incremental feature selection based on rough set in dynamic incomplete data,” Pattern Recognition, vol. 47, pp. 3890–3906, 2014. doi: 10.1016/j.patcog.2014.06.002
|
| [150] |
C. Yang, G. Hao, L. Li, and J. Ding, “A unified incremental reduction with the variations of the object for decision tables,” Soft Computing, vol. 23, pp. 6407–6427, 2019. doi: 10.1007/s00500-018-3296-5
|
| [151] |
X. Xie and X. Qin, “A novel incremental attribute reduction approach for dynamic incomplete decision systems,” Int. Journal of Approximate Reasoning, vol. 93, pp. 443–462, 2018. doi: 10.1016/j.ijar.2017.12.002
|
| [152] |
M. Zhang and Z. Zhou, “A review on multi-label learning algorithms,” IEEE Trans. Knowledge and Data Engineering, vol. 26, pp. 1819–1837, 2014. doi: 10.1109/TKDE.2013.39
|
| [153] |
A. Tan, J. Liang, W. Wu, J. Zhang, L. Sun, and C. Chen, “Fuzzy rough discrimination and label weighting for multi-label feature selection,” Neurocomputing, vol. 465, pp. 128–140, 2021. doi: 10.1016/j.neucom.2021.09.007
|
| [154] |
J. Liu, Y. Lin, Y. Li, W. Weng, and S. Wu, “Online multi-label streaming feature selection based on neighborhood rough set,” Pattern Recognition, vol. 84, pp. 273–287, 2018. doi: 10.1016/j.patcog.2018.07.021
|
| [155] |
S. Xu, X. Yang, H. Yu, D. Yu, J. Yang, and E. Tsang, “Multi-label learning with label-specific feature reduction,” Knowledge-Based Systems, vol. 104, pp. 52–61, 2016. doi: 10.1016/j.knosys.2016.04.012
|
| [156] |
X. Che, D. Chen, and J. Mi, “Label correlation in multi-label classification using local attribute reductions with fuzzy rough sets,” Fuzzy Sets and Systems, vol. 426, pp. 121–144, 2022. doi: 10.1016/j.fss.2021.03.016
|
| [157] |
E. Yao, D. Li, Y. Zhai, and C. Zhang, “Multilabel feature selection based on relative discernibility pair matrix,” IEEE Trans. Fuzzy Systems, vol. 30, pp. 2388–2401, 2022. doi: 10.1109/TFUZZ.2021.3082171
|
| [158] |
X. Geng, “Label distribution learning,” IEEE Trans. Knowledge and Data Engineering, vol. 28, pp. 1734–1748, 2016. doi: 10.1109/TKDE.2016.2545658
|
| [159] |
Y. Wang and J. Dai, “Label distribution feature selection based on mutual information in fuzzy rough set theory,” Int. Joint Conf. on Neural Networks, vol. 28, pp. 1–2, 2019.
|
| [160] |
Z. Deng, T. Li, D. Deng, K. Liu, P. Zhang, S. Zhang, and Z. Luo, “Feature selection for label distribution learning using dual-similarity based neighborhood fuzzy entropy,” Information Sciences, vol. 615, pp. 385–404, 2022. doi: 10.1016/j.ins.2022.10.054
|
| [161] |
W. Qian, F. Xu, J. Huang, and J. Qian, “A novel granular ball computing-based fuzzy rough set for feature selection in label distribution learning,” Knowledge-Based Systems, vol. 278, p. 110898, 2023. doi: 10.1016/j.knosys.2023.110898
|
| [162] |
W. Qian, P. Dong, S. Dai, J. Huang, and Y. Wang, “Incomplete label distribution feature selection based on neighborhood-tolerance discrimination index,” Applied Soft Computing, vol. 130, p. 109693, 2022. doi: 10.1016/j.asoc.2022.109693
|
| [163] |
Z. Deng, T. Li, D. Deng, K. Liu, Z. Luo, and P. Zhang, “Feature selection for handling label ambiguity using weighted label-fuzzy relevancy and redundancy,” IEEE Trans. Fuzzy Systems, vol. 32, no. 8, pp. 4436–4447, 2024. doi: 10.1109/TFUZZ.2024.3399617
|
| [164] |
Z. Zhou, “A brief introduction to weakly supervised learning,” National Science Review, vol. 5, pp. 44–53, 2018. doi: 10.1093/nsr/nwx106
|
| [165] |
C. Zhang, L. Zhu, D. Shi, J. Zheng, H. Chen, and B. Yu, “Semi-supervised feature selection with soft label learning,” IEEE/CAA Journal of Automatica Sinica, 2022, Early access, doi: 10.1109/JAS.2022.106055.
|
| [166] |
D. Qian, K. Liu, X. Yang, and S. Zhang, “Semi-supervised feature selection by minimum neighborhood redundancy and maximum neighborhood relevancy,” Applied Intelligence, vol. 54, pp. 7750–7764, 2024. doi: 10.1007/s10489-024-05578-9
|
| [167] |
J. Dai, Q. Hu, J. Zhang, H. Hu, and N. Zheng, “Attribute selection for partially labeled categorical data by rough set approach,” IEEE Trans. Cybernetics, vol. 47, pp. 2460–2471, 2017. doi: 10.1109/TCYB.2016.2636339
|
| [168] |
K. Liu, X. Yang, H. Yu, J. Mi, P. Wang, and X. Chen, “Rough set based semi-supervised feature selection via ensemble selector,” Knowledge-Based Systems, vol. 165, pp. 282–296, 2019. doi: 10.1016/j.knosys.2018.11.034
|
| [169] |
K. Liu, T. Li, X. Yang, H. Chen, J. Wang, and Z. Deng, “SemiFREE: Semi-supervised feature selection with fuzzy relevance and redundancy,” IEEE Trans. Fuzzy Systems, vol. 31, no. 10, pp. 3384–3396, 2023. doi: 10.1109/TFUZZ.2023.3255893
|
| [170] |
S. An, M. Zhang, C. Wang, and W. Ding, “Robust fuzzy rough approximations with kNN granules for semi-supervised feature selection,” Fuzzy Sets and Systems, vol. 461, p. 108476, 2023. doi: 10.1016/j.fss.2023.01.011
|
| [171] |
J. Dai, W. Huang, W. Wang, and C. Zhang, “Semi-supervised attribute reduction based on label distribution and label irrelevance,” Information Fusion, vol. 100, p. 101951, 2023. doi: 10.1016/j.inffus.2023.101951
|
| [172] |
Q. Hu, L. Zhang, S. An, D. Zhang, and D. Yu, “On robust fuzzy rough set models,” IEEE Trans. Fuzzy Systems, vol. 20, no. 4, pp. 636–651, 2012. doi: 10.1109/TFUZZ.2011.2181180
|
| [173] |
X. Yang, H. Chen, H. Wang, T. Li, Z. Yu, Z. Wang, and C. Luo, “Feature selection with local density-based fuzzy rough set model for noisy data,” IEEE Trans. Fuzzy Systems, vol. 31, pp. 1614–1627, 2023. doi: 10.1109/TFUZZ.2022.3206508
|
| [174] |
J. Wan, H. Chen, T. Li, B. Sang, and Z. Yuan, “Feature grouping and selection with graph theory in robust fuzzy rough approximation space,” IEEE Trans. Fuzzy Systems, vol. 31, pp. 213–225, 2023. doi: 10.1109/TFUZZ.2022.3185285
|
| [175] |
B. Sang, W. Xu, H. Chen, and T. Li, “Active anti-noise fuzzy dominance rough feature selection using adaptive k-nearest neighbors,” IEEE Trans. Fuzzy Systems, vol. 31, no. 11, pp. 3944–3958, 2023. doi: 10.1109/TFUZZ.2023.3272316
|
| [176] |
T. Yin, H. Chen, Z. Yuan, J. Wan, K. Liu, S. Horng, and T. Li, “A robust multilabel feature selection approach based on graph structure considering fuzzy dependency and feature interaction,” IEEE Trans. Fuzzy Systems, vol. 31, no. 12, pp. 4516–4528, 2023. doi: 10.1109/TFUZZ.2023.3287193
|
| [177] |
Y. Lin, H. Liu, H. Zhao, Q. Hu, X. Zhu, and X. Wu, “Hierarchical feature selection based on label distribution learning,” IEEE Trans. Knowledge and Data Engineering, vol. 35, pp. 5964–5976, 2023.
|
| [178] |
J. Liang, F. Wang, C. Dang, and Y. Qian, “An efficient rough feature selection algorithm with a multi-granulation view,” Int. Journal of Approximate Reasoning, vol. 53, pp. 912–926, 2012. doi: 10.1016/j.ijar.2012.02.004
|
| [179] |
W. Wu and Y. Leung, “Theory and applications of granular labelled partitions in multi-scale decision tables,” Information Sciences, vol. 181, pp. 3878–3897, 2011. doi: 10.1016/j.ins.2011.04.047
|
| [180] |
H. Zhao, P. Wang, Q. Hu, and P. Zhu, “Fuzzy rough set based feature selection for large-scale hierarchical classification,” IEEE Trans. Fuzzy Systems, vol. 27, pp. 1891–1903, 2019. doi: 10.1109/TFUZZ.2019.2892349
|
| [181] |
Q. Hu, L. Zhang, Y. Zhou, and W. Pedrycz, “Large-scale multimodality attribute reduction with multi-kernel fuzzy rough sets,” IEEE Trans. Fuzzy Systems, vol. 26, pp. 226–238, 2018. doi: 10.1109/TFUZZ.2017.2647966
|
| [182] |
X. Yang, Y. Li, D. Liu, and T. Li, “Hierarchical fuzzy rough approximations with three-way multigranularity learning,” IEEE Trans. Fuzzy Systems, vol. 30, pp. 3486–3500, 2022. doi: 10.1109/TFUZZ.2021.3117449
|
| [183] |
Y. Qian, J. Liang, Y. Yao, and C. Dang, “MGRS: A multi-granulation rough set,” Information Sciences, vol. 180, pp. 949–970, 2010. doi: 10.1016/j.ins.2009.11.023
|
| [184] |
J. Ba, K. Liu, H. Ju, S. Xu, T. Xu, and X. Yang, “Triple-G: A new MGRS and attribute reduction,” Int. Journal of Machine Learning and Cybernetics, vol. 13, pp. 337–356, 2022. doi: 10.1007/s13042-021-01404-7
|
| [185] |
Y. Li, M. Cai, J. Zhou, and Q. Li, “Accelerated multi-granularity reduction based on neighborhood rough sets,” Applied Intelligence, vol. 52, pp. 17 636–17 651, 2022. doi: 10.1007/s10489-022-03371-0
|
| [186] |
Y. Lin, J. Li, P. Lin, G. Lin, and J. Chen, “Feature selection via neighborhood multi-granulation fusion,” Knowledge-Based Systems, vol. 67, pp. 162–168, 2014. doi: 10.1016/j.knosys.2014.05.019
|
| [187] |
W. Ding, W. Pedrycz, I. Triguero, Z. Cao, and C. Lin, “Multigranulation supertrust model for attribute reduction,” IEEE Trans. Fuzzy Systems, vol. 29, pp. 1395–1408, 2021. doi: 10.1109/TFUZZ.2020.2975152
|
| [188] |
Z. Jiang, H. Dou, J. Song, P. Wang, X. Yang, and Y. Qian, “Data-guided multi-granularity selector for attribute reduction,” Applied Intelligence, vol. 51, pp. 876–888, 2021. doi: 10.1007/s10489-020-01846-6
|
| [189] |
Z. Huang and J. Li, “Feature subset selection with multi-scale fuzzy granulation,” IEEE Trans. Artificial Intelligence, vol. 4, pp. 121–134, 2023. doi: 10.1109/TAI.2022.3144242
|
| [190] |
X. Zhang, Z. He, J. Li, C. Mei, and Y. Yang, “Bi-selection of instances and features based on neighborhood importance degree,” IEEE Trans. Big Data, vol. 10, no. 4, pp. 415–428, 2024. doi: 10.1109/TBDATA.2023.3342643
|
| [191] |
H. Ju, X. Fan, W. Ding, J. Huang, S. Xu, X. Yang, and W. Pedrycz, “Dual-channel fuzzy interaction information fused feature selection with fuzzy sparse and shared granularities,” IEEE Trans. Fuzzy Systems, vol. 32, no. 11, pp. 6056–6068, 2024. doi: 10.1109/TFUZZ.2024.3438364
|
| [192] |
Q. Guo, K. Liu, T. Xu, P. Wang, and X. Yang, “Fuzzy feature factorization machine: Bridging feature interaction, selection, and construction,” Expert Systems with Applications, vol. 255, p. 124600, 2024. doi: 10.1016/j.eswa.2024.124600
|
| [193] |
X. Zou and J. Dai, “Multi-fuzzy β-covering fusion based accuracy and self-information for feature subset selection,” Information Fusion, vol. 110, p. 102486, 2024. doi: 10.1016/j.inffus.2024.102486
|
| [194] |
Y. Chen, W. Ding, H. Ju, J. Huang, and T. Yin, “Cascaded two-stage feature clustering and selection via separability and consistency in fuzzy decision systems,” IEEE Trans. Fuzzy Systems, vol. 32, no. 9, pp. 5320–5333, 2024. doi: 10.1109/TFUZZ.2024.3420963
|
| [195] |
P. Zhang, T. Li, Z. Yuan, C. Luo, K. Liu, and X. Yang, “Heterogeneous feature selection based on neighborhood combination entropy,” IEEE Trans. Neural Networks and Learning Systems, vol. 35, no. 3, pp. 3514–3527, 2024. doi: 10.1109/TNNLS.2022.3193929
|
| [196] |
J. Chen, X. Zhang, and Z. Yuan, “Feature selections based on two-type overlap degrees and three-view granulation measures for k-nearest-neighbor rough sets,” Pattern Recognition, vol. 156, p. 110837, 2024. doi: 10.1016/j.patcog.2024.110837
|
| [197] |
W. Ding, Y. Sun, M. Li, J. Liu, H. Ju, J. Huang, and C. Lin, “A novel Spark-based attribute reduction and neighborhood classification for rough evidence,” IEEE Trans. Cybernetics, vol. 54, no. 3, pp. 1470–1483, 2024. doi: 10.1109/TCYB.2022.3208130
|
| [198] |
Z. Huang and J. Li, “Noise-tolerant discrimination indexes for fuzzy γ covering and feature subset selection,” IEEE Trans. Neural Networks and Learning Systems, vol. 35, no. 1, pp. 609–623, 2024. doi: 10.1109/TNNLS.2022.3175922
|
| [199] |
K. Yuan, D. Miao, W. Pedrycz, W. Ding, and H. Zhang, “Ze-HFS: Zentropy-based uncertainty measure for heterogeneous feature selection and knowledge discovery,” IEEE Trans. Knowledge and Data Engineering, vol. 36, no. 11, pp. 7326–7339, 2024. doi: 10.1109/TKDE.2024.3419215
|
| [200] |
J. Demšar, “Statistical comparisons of classifiers over multiple data sets,” Journal of Machine Learning Research, vol. 7, pp. 1–30, 2006.
|
| [201] |
S. Han, K. Zhu, M. Zhou, H. Alhumade, and A. Abusorrah, “Locating multiple equivalent feature subsets in feature selection for imbalanced classification,” IEEE Trans. Knowledge and Data Engineering, vol. 35, no. 9, pp. 9195–9209, 2023. doi: 10.1109/TKDE.2022.3222047
|
| [202] |
H. Liu, M. Zhou, and Q. Liu, “An embedded feature selection method for imbalanced data classification,” IEEE/CAA Journal of Automatica Sinica, vol. 6, no. 3, pp. 703–715, 2019. doi: 10.1109/JAS.2019.1911447
|
| [203] |
H. Chen, T. Li, X. Fan, and C. Luo, “Feature selection for imbalanced data based on neighborhood rough sets,” Information Sciences, vol. 483, pp. 1–20, 2019. doi: 10.1016/j.ins.2019.01.041
|
| [204] |
L. Sun, S. Si, W. Ding, X. Wang, and J. Xu, “TFSFB: Two-stage feature selection via fusing fuzzy multi-neighborhood rough set with binary whale optimization for imbalanced data,” Information Fusion, vol. 95, pp. 91–108, 2023. doi: 10.1016/j.inffus.2023.02.016
|
| [205] |
T. Baltrušaitis, C. Ahuja, and L. Morency, “Multimodal machine learning: A survey and taxonomy,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 41, pp. 423–443, 2019. doi: 10.1109/TPAMI.2018.2798607
|
| [206] |
J. Dai, W. Chen, and L. Xia, “Feature selection based on neighborhood complementary entropy for heterogeneous data,” Information Sciences, vol. 682, p. 121261, 2024. doi: 10.1016/j.ins.2024.121261
|
| [207] |
Z. Yuan, H. Chen, and T. Li, “Exploring interactive attribute reduction via fuzzy complementary entropy for unlabeled mixed data,” Pattern Recognition, vol. 127, p. 108651, 2022. doi: 10.1016/j.patcog.2022.108651
|
| [208] |
P. Zhang, T. Li, Z. Yuan, C. Luo, G. Wang, J. Liu, and S. Du, “A data-level fusion model for unsupervised attribute selection in multi-source homogeneous data,” Information Fusion, vol. 80, pp. 87–103, 2022. doi: 10.1016/j.inffus.2021.10.017
|
| [209] |
K. Yu, X. Guo, L. Liu, J. Li, and X. Wu, “Causality-based feature selection: Methods and evaluations,” ACM Computing Surveys, vol. 53, pp. 111: 1–111: 36, 2020.
|
| [210] |
Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 35, pp. 1798–1828, 2013. doi: 10.1109/TPAMI.2013.50
|

Figures(11) / Tables(2)






 DownLoad:
DownLoad: