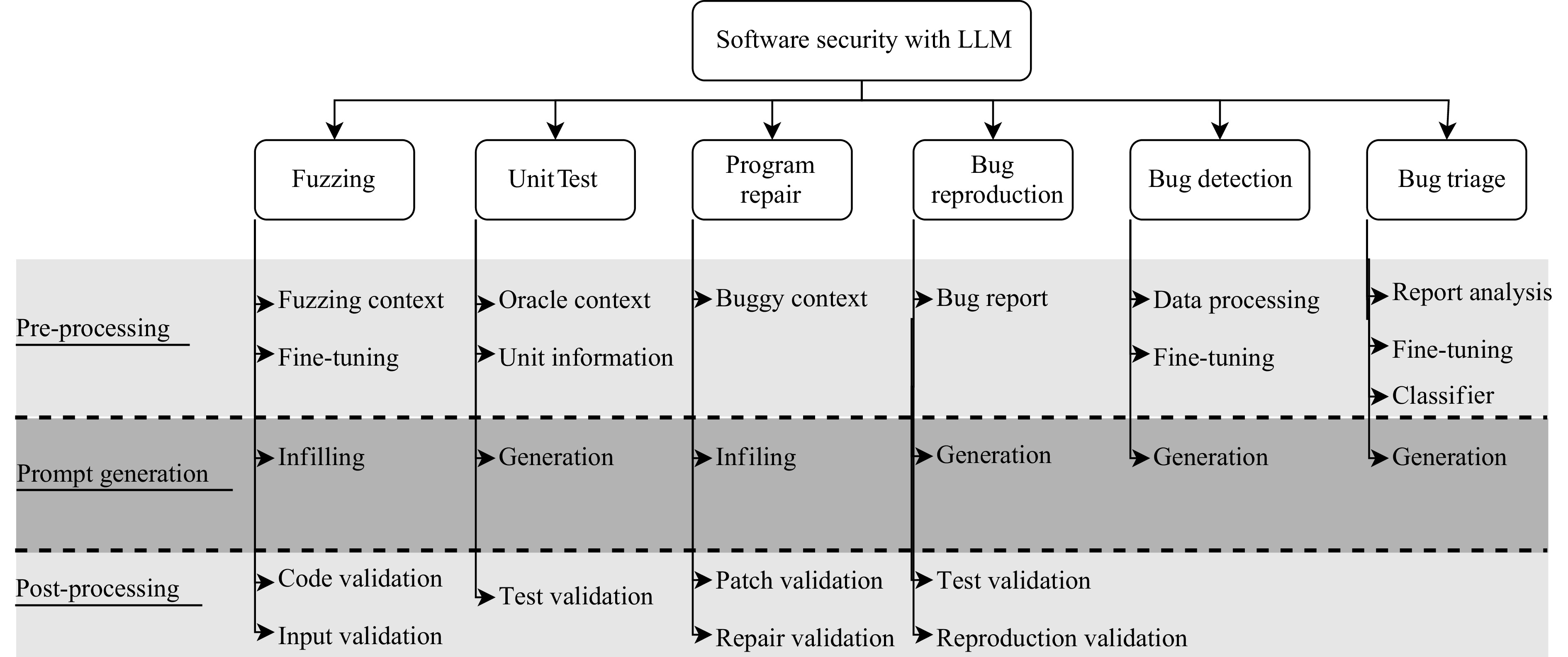
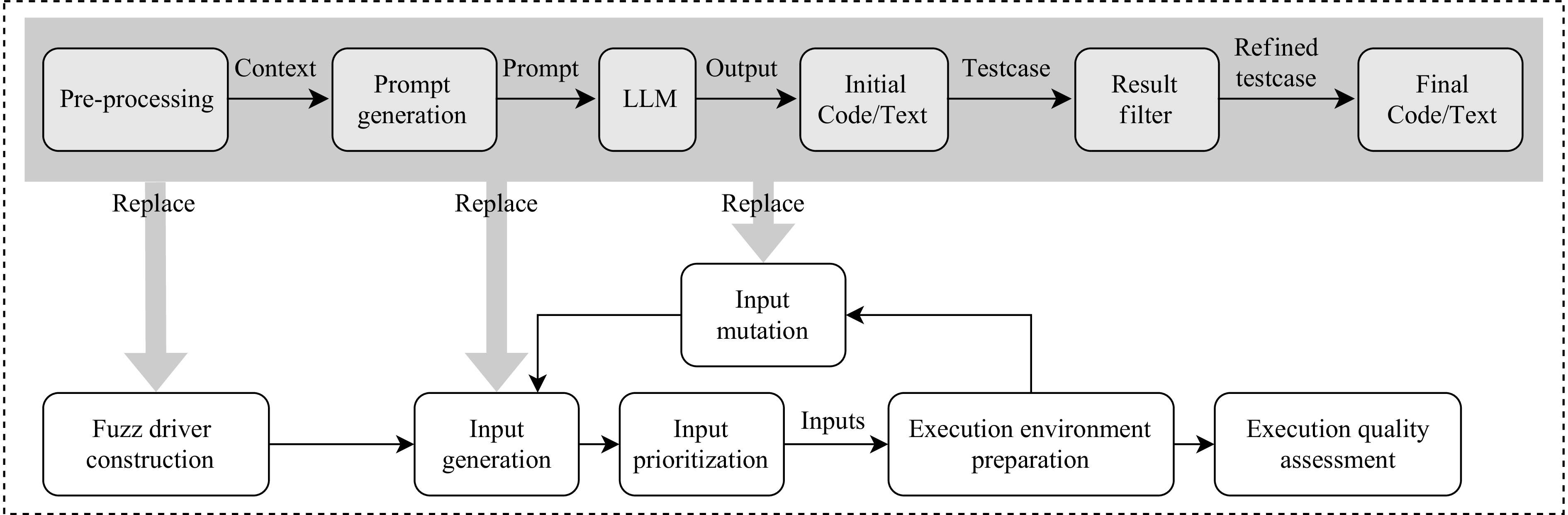
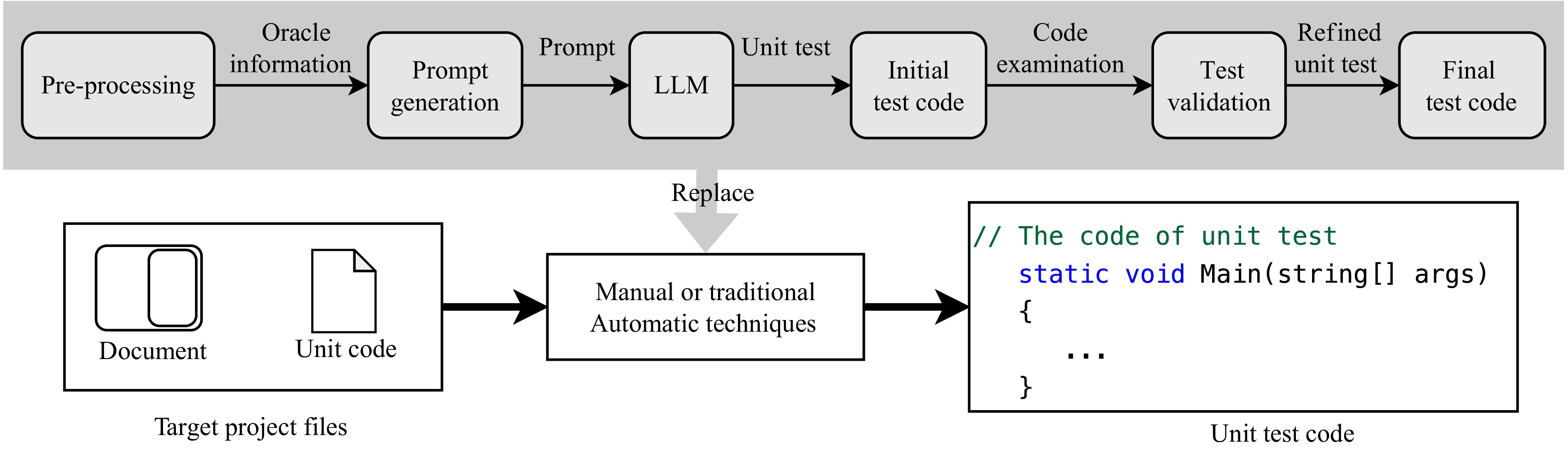
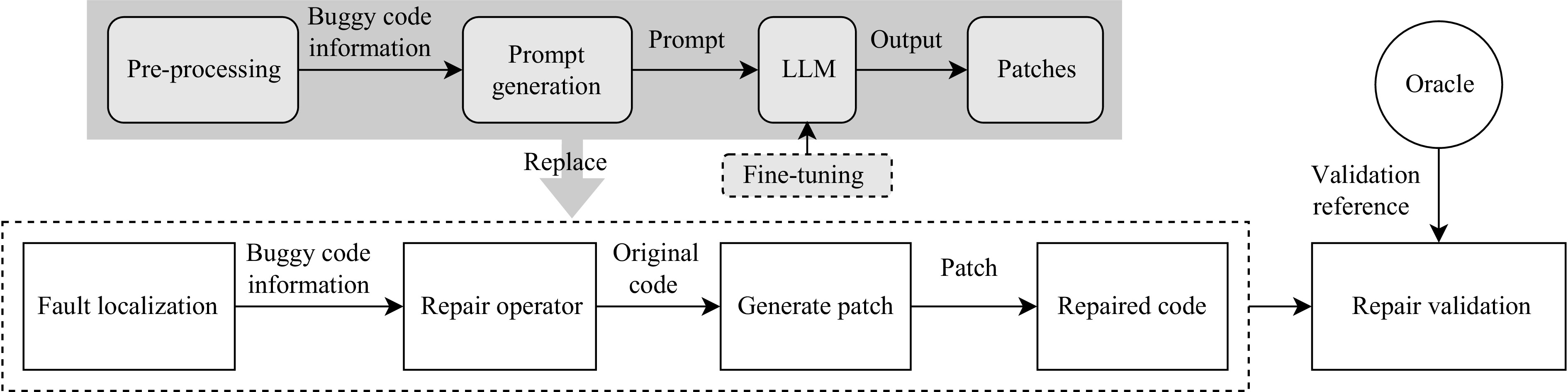
A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation

IEEE/CAA Journal of Automatica Sinica
| Citation: | X. Zhu, W. Zhou, Q.-L. Han, W. Ma, S. Wen, and Y. Xiang, “When software security meets large language models: A survey,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 2, pp. 317–334, Feb. 2025. doi: 10.1109/JAS.2024.124971

|

| [1] |
H. Shahriar and M. Zulkernine, “Mitigating program security vulnerabilities: Approaches and challenges,” ACM Comput. Surv., vol. 44, no. 3, p. 11, Jun. 2012.
|
| [2] |
P. Achimugu, A. Selamat, R. Ibrahim, and M. N. Mahrin, “A systematic literature review of software requirements prioritization research,” Inf. Software Technol., vol. 56, no. 6, pp. 568–585, Jun. 2014. doi: 10.1016/j.infsof.2014.02.001
|
| [3] |
C. Zhang and D. Budgen, “What do we know about the effectiveness of software design patterns?,” IEEE Trans. Software Eng., vol. 38, no. 5, pp. 1213–1231, Sep.–Oct. 2012. doi: 10.1109/TSE.2011.79
|
| [4] |
M. Jorgensen and M. Shepperd, “A systematic review of software development cost estimation studies,” IEEE Trans. Software Eng., vol. 33, no. 1, pp. 33–53, Jan. 2007. doi: 10.1109/TSE.2007.256943
|
| [5] |
X. Zhu, S. Wen, S. Camtepe, and Y. Xiang, “Fuzzing: A survey for roadmap,” ACM Comput. Surv., vol. 54, no. 11s, p. 230, Sep. 2022.
|
| [6] |
J. K. Siow, C. Gao, L. Fan, S. Chen, and Y. Liu, “CORE: Automating review recommendation for code changes,” in Proc. IEEE 27th Int. Conf. Software Analysis, Evolution and Reengineering, London, Canada, 2020, pp. 284–295.
|
| [7] |
2024 Must-Know Cyber Attack Statistics and Trends. [Online]. Available: https://www.embroker.com/blog/cyber-attack-statistics. Accessed on: Sep. 2024.
|
| [8] |
J. J. Gutiérrez, M. Escalona, and M. Mejías, “A Model-Driven approach for functional test case generation,” J. Syst. Software, vol. 109, pp. 214–228, Nov. 2015. doi: 10.1016/j.jss.2015.08.001
|
| [9] |
K. Zhang, X. Xiao, X. Zhu, R. Sun, M. Xue, and S. Wen, “Path transitions tell more: Optimizing fuzzing schedules via runtime program states,” in Proc. 44th Int. Conf. Software Engineering, Pittsburgh, USA, 2022, pp. 1658–1668.
|
| [10] |
G. Lin, S. Wen, Q.-L. Han, J. Zhang, and Y. Xiang, “Software vulnerability detection using deep neural networks: A survey,” Proc. IEEE, vol. 108, no. 10, pp. 1825–1848, Oct. 2020. doi: 10.1109/JPROC.2020.2993293
|
| [11] |
Y. Wei, Y. Pei, C. A. Furia, L. S. Silva, S. Buchholz, B. Meyer, and A. Zeller, “Automated fixing of programs with contracts,” in Proc. 19th Int. Symp. Software Testing and Analysis, Trento, Italy, 2010, pp. 61–72.
|
| [12] |
Y. Zhao, T. Yu, T. Su, Y. Liu, W. Zheng, J. Zhang, and W. G. J. Halfond, “ReCDroid: Automatically reproducing android application crashes from bug reports,” in Proc. IEEE/ACM 41st Int. Conf. Software Engineering, Montreal, Canada, 2019, pp. 128–139.
|
| [13] |
Z. Li, D. Zou, S. Xu, X. Ou, H. Jin, S. Wang, Z. Deng, and Y. Zhong, “VulDeePecker: A deep learning-based system for vulnerability detection,” in Proc. 25th Annu. Network and Distributed System Security Symp., San Diego, USA, 2018.
|
| [14] |
I. Alazzam, A. Aleroud, Z. Al Latifah, and G. Karabatis, “Automatic bug triage in software systems using graph neighborhood relations for feature augmentation,” IEEE Trans. Comput. Soc. Syst., vol. 7, no. 5, pp. 1288–1303, Oct. 2020. doi: 10.1109/TCSS.2020.3017501
|
| [15] |
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, May 2015. doi: 10.1038/nature14539
|
| [16] |
Y. Yang, X. Xia, D. Lo, and J. Grundy, “A survey on deep learning for software engineering,” ACM Comput. Surv., vol. 54, no. 10s, p. 206, Sep. 2022.
|
| [17] |
P. Godefroid, H. Peleg, and R. Singh, “Learn&Fuzz: Machine learning for input fuzzing,” in Proc. 32nd IEEE/ACM Int. Conf. Automated Software Engineering, Urbana, USA, 2017, pp. 50–59.
|
| [18] |
N. Jiang, T. Lutellier, and L. Tan, “CURE: Code-aware neural machine translation for automatic program repair,” in Proc. IEEE/ACM 43rd Int. Conf. Software Engineering, Madrid, Spain, 2021, pp. 1161–1173.
|
| [19] |
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, Y. Du, C. Yang, Y. Chen, Z. Chen, J. Jiang, R. Ren, Y. Li, X. Tang, Z. Liu, P. Liu, J.-Y. Nie, and J.-R. Wen, “A survey of large language models,” arXiv preprint arXiv: 2303.18223, 2023.
|
| [20] |
Y. Deng, C. S. Xia, H. Peng, C. Yang, and L. Zhang, “Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,” in Proc. 32nd ACM SIGSOFT Int. Symp. Software Testing and Analysis, Seattle, USA, 2023.
|
| [21] |
H. Pearce, B. Tan, B. Ahmad, R. Karri, and B. Dolan-Gavitt, “Examining zero-shot vulnerability repair with large language models,” in Proc. IEEE Symp. Security and Privacy, San Francisco, USA, 2023, pp. 1–18.
|
| [22] |
C. S. Xia and L. Zhang, “Less training, more repairing please: Revisiting automated program repair via zero-shot learning,” in Proc. 30th ACM Joint European Software Engineering Conf. Symp. Foundations of Software Engineering, Singapore, Singapore, 2022, pp. 959–971.
|
| [23] |
J. Zhang, L. Pan, Q.-L. Han, C. Chen, S. Wen, and Y. Xiang, “Deep learning based attack detection for cyber-physical system cybersecurity: A survey,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 3, pp. 377–391, Mar. 2022. doi: 10.1109/JAS.2021.1004261
|
| [24] |
H. Xu, S. Wang, N. Li, K. Wang, Y. Zhao, K. Chen, T. Yu, Y. Liu, and H. Wang, “Large language models for cyber security: A systematic literature review,” arXiv preprint arXiv: 2405.04760, 2024.
|
| [25] |
T. Wu, S. He, J. Liu, S. Sun, K. Liu, Q.-L. Han, and Y. Tang, “A brief overview of ChatGPT: The history, status quo and potential future development,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 5, pp. 1122–1136, May 2023. doi: 10.1109/JAS.2023.123618
|
| [26] |
J. Wang, Y. Huang, C. Chen, Z. Liu, S. Wang, and Q. Wang, “Software testing with large language models: Survey, landscape, and vision,” IEEE Trans. Software Eng., vol. 50, no. 4, pp. 911–936, Apr. 2024. doi: 10.1109/TSE.2024.3368208
|
| [27] |
S. Kang, J. Yoon, and S. Yoo, “Large language models are few-shot testers: Exploring LLM-based general bug reproduction,” in Proc. 45th IEEE/ACM Int. Conf. Software Engineering, Melbourne, Australia, 2023.
|
| [28] |
R. Natella, D. Cotroneo, J. A. Duraes, and H. S. Madeira, “On fault representativeness of software fault injection,” IEEE Trans. Software Eng., vol. 39, no. 1, pp. 80–96, Jan. 2013. doi: 10.1109/TSE.2011.124
|
| [29] |
R. Baldoni, E. Coppa, D. C. D’elia, C. Demetrescu, and I. Finocchi, “A survey of symbolic execution techniques,” ACM Comput. Surv., vol. 51, no. 3, p. 50, May 2018.
|
| [30] |
X. Liu, X. Li, R. Prajapati, and D. Wu, “DeepFuzz: Automatic generation of syntax valid c programs for fuzz testing,” in Proc. 33rd AAAI Conf. Artificial Intelligence, Honolulu, USA, 2019, pp. 1044–1051.
|
| [31] |
J. Wen, T. Mahmud, M. Che, Y. Yan, and G. Yang, “Intelligent constraint classification for symbolic execution,” in Proc. IEEE Int. Conf. Software Analysis, Evolution and Reengineering, Taipa, China, 2023, pp. 144–154.
|
| [32] |
OpenAI, “Introducing ChatGPT,” [Online]. Available: https://openai.com/blog/chatgpt. Accessed on: Nov. 30, 2022.
|
| [33] |
B. Rozière, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y. Adi, J. Liu, R. Sauvestre, T. Remez, J. Rapin, A. Kozhevnikov, I. Evtimov, J. Bitton, M. Bhatt, C. C. Ferrer, A. Grattafiori, W. Xiong, A. Défossez, J. Copet, F. Azhar, H. Touvron, L. Martin, N. Usunier, T. Scialom, and G. Synnaeve, “Code llama: Open foundation models for code,” arXiv preprint arXiv: 2308.12950, 2023.
|
| [34] |
J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, E. H. Chi, T. Hashimoto, O. Vinyals, P. Liang, J. Dean, and W. Fedus, “Emergent abilities of large language models,” arXiv preprint arXiv: 2206.07682, 2022.
|
| [35] |
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Kureger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” Proc. 34th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2020, pp. 1877–1901.
|
| [36] |
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” in Proc. 36th Int. Conf. Machine Learning, Long Beach, USA, 2019, pp. 2790–2799.
|
| [37] |
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” in Proc. 59th Annu. Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. Natural Language Processing, 2021, pp. 4582–4597.
|
| [38] |
J. Lee, K. Han, and H. Yu, “A light bug triage framework for applying large pre-trained language model,” in Proc. 37th IEEE/ACM Int. Conf. Automated Software Engineering, Rochester, USA, 2022, pp. 3.
|
| [39] |
G. Ye, Z. Tang, S. H. Tan, S. Huang, D. Fang, X. Sun, L. Bian, H. Wang, and Z. Wang, “Automated conformance testing for JavaScript engines via deep compiler fuzzing,” in Proc. 42nd ACM SIGPLAN Int. Conf. Programming Language Design and Implementation, Canada, 2021, pp. 435–450.
|
| [40] |
C. Thapa, S. I. Jang, M. E. Ahmed, S. Camtepe, J. Pieprzyk, and S. Nepal, “Transformer-based language models for software vulnerability detection,” in Proc. 38th Annu. Computer Security Applications Conf., Austin, USA, 2022, pp. 481–496.
|
| [41] |
C. Lemieux, J. P. Inala, S. K. Lahiri, and S. Sen, “CODAMOSA: Escaping coverage plateaus in test generation with pre-trained large language models,” in Proc. 45th IEEE/ACM Int. Conf. Software Engineering, Melbourne, Australia, 2023.
|
| [42] |
Z. Liu, C. Chen, J. Wang, X. Che, Y. Huang, J. Hu, and Q. Wang, “Fill in the blank: Context-aware automated text input generation for mobile GUI testing,” in Proc. 45th IEEE/ACM Int. Conf. Software Engineering, Melbourne, Australia, 2023.
|
| [43] |
N. Jiang, K. Liu, T. Lutellier, and L. Tan, “Impact of code language models on automated program repair,” in Proc. IEEE/ACM 45th Int. Conf. Software Engineering, Melbourne, Australia, 2023.
|
| [44] |
C. S. Xia, Y. Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” in Proc. IEEE/ACM 45th Int. Conf. Software Engineering, Melbourne, Australia, 2023.
|
| [45] |
V. H. S. Durelli, R. S. Durelli, S. S. Borges, A. T. Endo, M. M. Eler, D. R. C. Dias, and M. P. Guimarães, “Machine learning applied to software testing: A systematic mapping study,” IEEE Trans. Rel., vol. 68, no. 3, pp. 1189–1212, Sep. 2019. doi: 10.1109/TR.2019.2892517
|
| [46] |
X. Zhu and M. Böhme, “Regression greybox fuzzing,” in Proc. ACM SIGSAC Conf. Computer and Communications Security, Republic of Korea, 2021, pp. 2169–2182.
|
| [47] |
X. Feng, X. Zhu, Q.-L. Han, W. Zhou, S. Wen, and Y. Xiang, “Detecting vulnerability on IoT device firmware: A survey,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 1, pp. 25–41, Jan. 2023. doi: 10.1109/JAS.2022.105860
|
| [48] |
X. Zhu, X. Feng, T. Jiao, S. Wen, Y. Xiang, S. Camtepe, and J. Xue, “A feature-oriented corpus for understanding, evaluating and improving fuzz testing,” in Proc. ACM Asia Conf. Computer and Communications Security, Auckland, New Zealand, 2019, pp. 658–663.
|
| [49] |
E. T. Barr, M. Harman, P. Mcminn, M. Shahbaz, and S. Yoo, “The oracle problem in software testing: A survey,” IEEE Trans. Software Eng., vol. 41, no. 5, pp. 507–525, May 2015. doi: 10.1109/TSE.2014.2372785
|
| [50] |
Y. Jia and M. Harman, “An analysis and survey of the development of mutation testing,” IEEE Trans. Software Engineering, vol. 37, no. 5, pp. 649–678, Sep.–Oct. 2011. doi: 10.1109/TSE.2010.62
|
| [51] |
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” Openai Blog, vol. 1, no. 8, p. 9, 2019.
|
| [52] |
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba, “Evaluating large language models trained on code,” arXiv preprint arXiv: 2107.03374, 2021.
|
| [53] |
B. Deka, Z. Huang, C. Franzen, J. Hibschman, D. Afergan, Y. Li, J. Nichols, and R. Kumar, “Rico: A mobile app dataset for building data-driven design applications,” in Proc. 30th Annu. ACM Symp. User Interface Software and Technology, Québec City, Canada, 2017, pp. 845–854.
|
| [54] |
K. Kuznetsov, C. Fu, S. Gao, D. N. Jansen, L. Zhang, and A. Zeller, “Frontmatter: Mining Android user interfaces at scale,” in Proc. 29th ACM Joint Meeting on European Software Engineering Conf. Symp. Foundations of Software Engineering, Athens, Greece, 2021, pp. 1580–1584.
|
| [55] |
D. Fried, A. Aghajanyan, J. Lin, S. Wang, E. Wallace, F. Shi, R. Zhong, W.-T. Yih, L. Zettlemoyer, and M. Lewis, “InCoder: A generative model for code infilling and synthesis,” arXiv preprint arXiv: 2204.05999, 2022.
|
| [56] |
R. Meng, M. Mirchev, M. Böhme, and A. Roychoudhury, “Large language model guided protocol fuzzing,” in Proc. 31st Annu. Network and Distributed System Security Symp., San Diego, USA, 2024.
|
| [57] |
P. Bareiß, B. Souza, M. d’Amorim, and M. Pradel, “Code generation tools (almost) for free? A study of few-shot, pre-trained language models on code,” arXiv preprint arXiv: 2206.01335, 2022.
|
| [58] |
Z. Xie, Y. Chen, C. Zhi, S. Deng, and J. Yin, “ChatUniTest: A ChatGPT-based automated unit test generation tool,” arXiv preprint arXiv: 2305.04764v1, 2023.
|
| [59] |
M. Schäfer, S. Nadi, A. Eghbali, and F. Tip, “An empirical evaluation of using large language models for automated unit test generation,” IEEE Trans. Software Eng., vol. 50, no. 1, pp. 85–105, Jan. 2024. doi: 10.1109/TSE.2023.3334955
|
| [60] |
N. Rao, K. Jain, U. Alon, C. Le Goues, and V. J. Hellendoorn, “CAT-LM training language models on aligned code and tests,” in Proc. 38th IEEE/ACM Int. Conf. Automated Software Engineering, Echternach, Luxembourg, 2023, pp. 409–420.
|
| [61] |
X. Feng, R. Sun, X. Zhu, M. Xue, S. Wen, D. Liu, S. Nepal, and Y. Xiang, “Snipuzz: Black-box fuzzing of IoT firmware via message snippet inference,” in Proc. ACM SIGSAC Conf. Computer and Communications Security, Republic of Korea, 2021, pp. 337–350.
|
| [62] |
X. Zhu, X. Feng, X. Meng, S. Wen, S. Camtepe, Y. Xiang, and K. Ren, “CSI-Fuzz: Full-speed edge tracing using coverage sensitive instrumentation,” IEEE Trans. Dependable Secure Comput., vol. 19, no. 2, pp. 912–923, Mar.–Apr. 2022.
|
| [63] |
D. Babić, S. Bucur, Y. Chen, F. Ivančić, T. King, M. Kusano, C. Lemieux, L. Szekeres, and W. Wang, “FUDGE: Fuzz driver generation at scale,” in Proc. 27th ACM Joint Meeting on European Software Engineering Conf. Symp. Foundations of Software Engineering, Tallinn, Estonia, 2019, pp. 975–985.
|
| [64] |
N. Jain, S. Vaidyanath, A. Iyer, N. Natarajan, S. Parthasarathy, S. Rajamani, and R. Sharma, “Jigsaw: Large language models meet program synthesis,” in Proc. IEEE/ACM 44th Int. Conf. Software Engineering, Pittsburgh, USA, 2022, pp. 1219–1231.
|
| [65] |
H. Strobelt, A. Webson, V. Sanh, B. Hoover, J. Beyer, H. Pfister, and A. M. Rush, “Interactive and visual prompt engineering for ad-hoc task adaptation with large language models,” IEEE Trans. Vis. Comput. Graph., vol. 29, no. 1, pp. 1146–1156, Jan. 2023.
|
| [66] |
B. Jeong, J. Jang, H. Yi, J. Moon, J. Kim, I. Jeon, T. Kim, W. C. Shim, and Y. H. Hwang, “UTOPIA: Automatic generation of fuzz driver using unit tests,” in Proc. IEEE Symp. Security and Privacy, San Francisco, USA, 2023, pp. 746–762.
|
| [67] |
L. Williams, G. Kudrjavets, and N. Nagappan, “On the effectiveness of unit test automation at microsoft,” in Proc. 20th Int. Symp. Software Reliability Engineering, Mysuru, India, 2009, pp. 81–89.
|
| [68] |
G. Fraser and A. Arcuri, “EvoSuite: Automatic test suite generation for object-oriented software,” in Proc. 19th ACM SIGSOFT Symp. 13th European Conf. Foundations of Software Engineering, Szeged, Hungary, 2011, pp. 416–419.
|
| [69] |
C. Pacheco and M. D. Ernst, “Randoop: Feedback-directed random testing for Java,” in Proc. 22nd ACM SIGPLAN Conf. Object-Oriented Programming Systems and Applications Companion, Montreal, Canada, 2007, pp. 815–816.
|
| [70] |
M. M. Almasi, H. Hemmati, G. Fraser, A. Arcuri, and J. Benefelds, “An industrial evaluation of unit test generation: Finding real faults in a financial application,” in Proc. IEEE/ACM 39th Int. Conf. Software Engineering: Software Engineering in Practice Track, Buenos Aires, Argentina, 2017, pp. 263–272.
|
| [71] |
F. E. Allen, “Control flow analysis,” ACM SIGPLAN Not., vol. 5, no. 7, pp. 1–19, Jul. 1970. doi: 10.1145/390013.808479
|
| [72] |
L. D. Fosdick and L. J. Osterweil, “Data flow analysis in software reliability,” ACM Comput. Surv., vol. 8, no. 3, pp. 305–330, Sep. 1976. doi: 10.1145/356674.356676
|
| [73] |
J. Zhang, X. Wang, H. Zhang, H. Sun, K. Wang, and X. Liu, “A novel neural source code representation based on abstract syntax tree,” in Proc. IEEE/ACM 41st Int. Conf. Software Engineering, Montreal, Canada, 2019, pp. 783–794.
|
| [74] |
J. A. Prenner and R. Robbes, “Automatic program repair with OpenAI’s codex: Evaluating QuixBugs,” arXiv preprint arXiv: 2111.03922, 2021.
|
| [75] |
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou, “CodeBERT: A pre-trained model for programming and natural languages,” in Proc. Findings of the Association for Computational Linguistics, 2020, pp. 1536–1547.
|
| [76] |
J. Zhang, J. Cambronero, S. Gulwani, V. Le, R. Piskac, G. Soares, and G. Verbruggen, “Repairing bugs in python assignments using large language models,” arXiv preprint arXiv: 2209.14876, 2022.
|
| [77] |
M. Fu, C. Tantithamthavorn, T. Le, V. Nguyen, and D. Phung, “VulRepair: A t5-based automated software vulnerability repair,” in Proc. 30th ACM Joint European Software Engineering Conf. Symp. Foundations of Software Engineering, Singapore, Singapore, 2022, pp. 935–947.
|
| [78] |
N. Tihanyi, R. Jain, Y. Charalambous, M. A. Ferrag, Y. Sun, and L. C. Cordeiro, “A new era in software security: Towards self-healing software via large language models and formal verification,” arXiv preprint arXiv: 2305.14752, 2023.
|
| [79] |
Y. Wang, W. Wang, S. Joty, and S. C. H. Hoi, “CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,” in Proc. Conf. Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021, pp. 8696–8708.
|
| [80] |
Z. Fan, X. Gao, M. Mirchev, A. Roychoudhury, and S. H. Tan, “Automated repair of programs from large language models,” in Proc. IEEE/ACM 45th Int. Conf. Software Engineering, Melbourne, Australia, 2023.
|
| [81] |
AI21, “Announcing ai21 studio and jurassic-1 language models,” [Online]. Available: https://www.ai21.com/blog/announcing-ai21-studio-and-jurassic-1. Accessed on: Jul., 2023.
|
| [82] |
F. F. Xu, U. Alon, G. Neubig, and V. J. Hellendoorn, “A systematic evaluation of large language models of code,” in Proc. 6th ACM SIGPLAN Int. Symp. Machine Programming, San Diego, USA, 2022, pp. 1–10.
|
| [83] |
W. Ahmad, S. Chakraborty, B. Ray, and K.-W. Chang, “Unified pre-training for program understanding and generation,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021, pp. 2655–2668.
|
| [84] |
E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y. Zhou, S. Savarese, and C. Xiong, “CodeGen: An open large language model for code with multi-turn program synthesis,” in Proc. 11th Int. Conf. Learning Representations, Kigali, Rwanda, 2023.
|
| [85] |
Y. Wu, N. Jiang, H. V. Pham, T. Lutellier, J. Davis, L. Tan, P. Babkin, and S. Shah, “How effective are neural networks for fixing security vulnerabilities,” in Proc. 32nd ACM SIGSOFT Int. Symp. Software Testing and Analysis, Seattle, USA, 2023.
|
| [86] |
N. Nashid, M. Sintaha, and A. Mesbah, “Retrieval-based prompt selection for code-related few-shot learning,” in Proc. IEEE/ACM 45th Int. Conf. Software Engineering, Melbourne, Australia, 2023, pp. 2450–2462.
|
| [87] |
K. Huang, X. Meng, J. Zhang, Y. Liu, W. Wang, S. Li, and Y. Zhang, “An empirical study on fine-tuning large language models of code for automated program repair,” in Proc. 38th IEEE/ACM Int. Conf. Automated Software Engineering, Luxembourg, Luxembourg, 2023, pp. 1162–1174.
|
| [88] |
D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, L. Zhou, N. Duan, A. Svyatkovskiy, S. Fu, M. Tufano, S. K. Deng, C. B. Clement, D. Drain, N. Sundaresan, J. Yin, D. Jiang, and M. Zhou, “GraphcodeBERT: Pre-training code representations with data flow,” in Proc. 9th Int. Conf. Learning Representations, Austria, 2021.
|
| [89] |
Y. Wei, C. S. Xia, and L. Zhang, “Copiloting the copilots: Fusing large language models with completion engines for automated program repair,” in Proc. 31st ACM Joint European Software Engineering Conf. Symp. Foundations of Software Engineering, San Francisco, USA, 2023, pp. 172–184.
|
| [90] |
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-Lm: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv: 1909.08053, 2019.
|
| [91] |
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “RoBERTa: A robustly optimized BERT pretraining approach,” arXiv preprint arXiv: 1907.11692, 2019.
|
| [92] |
M. R. Taesiri, F. Macklon, Y. Wang, H. Shen, and C.-P. Bezemer, “Large language models are pretty good zero-shot video game bug detectors,” arXiv preprint arXiv: 2210.02506, 2022.
|
| [93] |
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 2011.
|
| [94] |
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer, “OPT: Open pre-trained transformer language models,” arXiv preprint arXiv: 2205.01068, 2022.
|
| [95] |
A. Cheshkov, P. Zadorozhny, and R. Levichev, “Evaluation of ChatGPT model for vulnerability detection,” arXiv preprint arXiv: 2304.07232, 2023.
|
| [96] |
M. Monperrus, “Automatic software repair: A bibliography,” ACM Comput. Surv., vol. 51, no. 1, p. 17, Jan. 2019.
|
| [97] |
H. Zhong and Z. Su, “An empirical study on real bug fixes,” in Proc. IEEE/ACM 37th IEEE Int. Conf. Software Engineering, Florence, Italy, 2015, pp. 913–923.
|
| [98] |
W. E. Wong, R. Gao, Y. Li, R. Abreu, and F. Wotawa, “A survey on software fault localization,” IEEE Trans. Software Eng., vol. 42, no. 8, pp. 707–740, Aug. 2016. doi: 10.1109/TSE.2016.2521368
|
| [99] |
S. D. Kolak, R. Martins, C. Le Goues, and V. J. Hellendoorn, “Patch generation with language models: Feasibility and scaling behavior,” in Proc. Deep Learning for Code Workshop, 2022.
|
| [100] |
B. Ahmad, S. Thakur, B. Tan, R. Karri, and H. Pearce, “Fixing hardware security bugs with large language models,” arXiv preprint arXiv: 2302.01215, 2023.
|
| [101] |
D. Lin, J. Koppel, A. Chen, and A. Solar-Lezama, “QuixBugs: A multi-lingual program repair benchmark set based on the quixey challenge,” in Proc. ACM SIGPLAN Int. Conf. Systems, Programming, Languages, and Applications: Software for Humanity, Vancouver, Canada, 2017, pp. 55–56.
|
| [102] |
“Common weakness enumeration: A community-developed list of software and hardware weakness types,” [Online]. Available: https://cwe.mitre.org/. Accessed on: Jul., 2023.
|
| [103] |
A. Biere, A. Cimatti, E. M. Clarke, O. Strichman, and Y. Zhu, “Bounded model checking,” Handbook Satisfiability, vol. 185, no. 99, pp. 457–481, Feb. 2009.
|
| [104] |
M. Gordon, “The semantic challenge of Verilog HDL,” in Proc. 10th Annu. IEEE Symp. Logic in Computer Science, San Deigo, USA, 1995, pp. 136–145.
|
| [105] |
M. Fazzini, M. Prammer, M. d’Amorim, and A. Orso, “Automatically translating bug reports into test cases for mobile apps,” in Proc. 27th ACM SIGSOFT Int. Symp. Software Testing and Analysis, Amsterdam, Netherlands, 2018, pp. 141–152.
|
| [106] |
N. Chen and S. Kim, “STAR: Stack trace based automatic crash reproduction via symbolic execution,” IEEE Trans. Software Eng., vol. 41, no. 2, pp. 198–220, Feb. 2015. doi: 10.1109/TSE.2014.2363469
|
| [107] |
S. Artzi, S. Kim, and M. D. Ernst, “ReCrash: Making software failures reproducible by preserving object states,” in Proc. 22nd European Conf. Paphos, Cyprus, 2008, pp. 542–565.
|
| [108] |
W. Jin and A. Orso, “BugRedux: Reproducing field failures for in-house debugging,” in Proc. 34th Int. Conf. Software Engineering, Zurich, Switzerland, 2012, pp. 474–484.
|
| [109] |
Z. Li, D. Zou, S. Xu, H. Jin, Y. Zhu, and Z. Chen, “SySeVR: A framework for using deep learning to detect software vulnerabilities,” IEEE Trans. Dependable Secure Comput., vol. 19, no. 4, pp. 2244–2258, 2022. doi: 10.1109/TDSC.2021.3051525
|
| [110] |
G. Grieco, G. L. Grinblat, L. Uzal, S. Rawat, J. Feist, and L. Mounier, “Toward large-scale vulnerability discovery using machine learning,” in Proc. 6th ACM Conf. Data and Application Security and Privacy, New Orleans, USA, 2016, pp. 85–96.
|
| [111] |
T. Le, T. V. Nguyen, T. Le, D. Phung, P. Montague, O. De Vel, and L. Qu, “Maximal divergence sequential auto-encoder for binary software vulnerability detection,” in Proc. Int. Conf. Learning Representations, La Jolla, USA, 2019.
|
| [112] |
R. Russell, L. Kim, L. Hamilton, T. Lazovich, J. Harer, O. Ozdemir, P. Ellingwood, and M. McConley, “Automated vulnerability detection in source code using deep representation learning,” in Proc. 17th IEEE Int. Conf. Machine Learning and Applications, Orlando, USA, 2018, pp. 757–762.
|
| [113] |
J. Xuan, H. Jiang, Y. Hu, Z. Ren, W. Zou, Z. Luo, and X. Wu, “Towards effective bug triage with software data reduction techniques,” IEEE Trans. Knowl. Data Eng., vol. 27, no. 1, pp. 264–280, Jan. 2015. doi: 10.1109/TKDE.2014.2324590
|
| [114] |
S. Mani, A. Sankaran, and R. Aralikatte, “DeepTriage: Exploring the effectiveness of deep learning for bug triaging,” in Proc. ACM India Joint Int. Conf. Data Science and Management of Data, Kolkata, India, 2019, pp. 171–179.
|
| [115] |
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv: 1503.02531, 2015.
|
| [116] |
N. Zeng, P. Wu, Z. Wang, H. Li, W. Liu, and X. Liu, “A small-sized object detection oriented multi-scale feature fusion approach with application to defect detection,” IEEE Trans. Instrum. Meas., vol. 71, p. 3507014, Feb. 2022.
|
| [117] |
N. Zeng, P. Wu, Y. Zhang, H. Li, J. Mao, and Z. Wang, “DPMSN: A dual-pathway multiscale network for image forgery detection,” IEEE Trans. Industr. Inform., vol. 20, no. 5, pp. 7665–7674, May 2024. doi: 10.1109/TII.2024.3359454
|
| [118] |
K. M. Yoo, D. Park, J. Kang, S.-W. Lee, and W. Park, “GPT3Mix: Leveraging large-scale language models for text augmentation,” in Proc. Findings of the Association for Computational Linguistics, Punta Cana, Dominican Republic, 2021, pp. 2225–2239.
|
| [119] |
L. Bonifacio, H. Abonizio, M. Fadaee, and R. Nogueira, “InPars: Data augmentation for information retrieval using large language models,” arXiv preprint arXiv: 2202.05144, 2022.
|
| [120] |
G. Sahu, P. Rodriguez, I. Laradji, P. Atighehchian, D. Vazquez, and D. Bahdanau, “Data augmentation for intent classification with off-the-shelf large language models,” in Proc. 4th Workshop on NLP for Conversational AI, Dublin, Ireland, 2022.
|
| [121] |
X. Chen, C. Li, D. Wang, S. Wen, J. Zhang, S. Nepal, Y. Xiang, and K. Ren, “Android HIV: A study of repackaging malware for evading machine-learning detection,” IEEE Trans. Inf. Forensics Secur., vol. 15, pp. 987–1001, Jul. 2020. doi: 10.1109/TIFS.2019.2932228
|
| [122] |
J. Zhao, A. Albarghouthi, V. Rastogi, S. Jha, and D. Octeau, “Neural-augmented static analysis of android communication,” in Proc. 26th ACM Joint Meeting on European Software Engineering Conf. Symp. Foundations of Software Engineering, Lake Buena Vista, USA, 2018, pp. 342–353.
|
| [123] |
Y. Li, S. Ji, Y. Chen, S. Liang, W.-H. Lee, Y. Chen, C. Lyu, C. Wu, R. Beyah, P. Cheng, K. Lu, and T. Wang, “UNIFUZZ: A holistic and pragmatic Metrics-Driven platform for evaluating fuzzers,” in Proc. 30th USENIX Security Symp., 2021, pp. 2777–2794.
|
| [124] |
M. Bohme, C. Cadar, and A. Roychoudhury, “Fuzzing: Challenges and reflections,” IEEE Software, vol. 38, no. 3, pp. 79–86, May-Jun. 2021. doi: 10.1109/MS.2020.3016773
|
| [125] |
K. Jesse, T. Ahmed, P. T. Devanbu, and E. Morgan, “Large language models and simple, stupid bugs,” in Proc. IEEE/ACM 20th Int. Conf. Mining Software Repositories, Melbourne, Australia, 2023.
|
| [126] |
S. Wang, T. Liu, and L. Tan, “Automatically learning semantic features for defect prediction,” in Proc. 38th Int. Conf. Software Engineering, Austin, USA, 2016, pp. 297–308.
|
| [127] |
X. Huo, F. Thung, M. Li, D. Lo, and S.-T. Shi, “Deep transfer bug localization,” IEEE Trans. Software Eng., vol. 47, no. 7, pp. 1368–1380, Jul. 2021. doi: 10.1109/TSE.2019.2920771
|
| [128] |
X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural network-based graph embedding for cross-platform binary code similarity detection,” in Proc. ACM SIGSAC Conf. Computer and Communications Security, Dallas, USA, 2017, pp. 363–376.
|
| [129] |
H. Pearce, B. Tan, P. Krishnamurthy, F. Khorrami, R. Karri, and B. Dolan-Gavitt, “Pop quiz! Can a large language model help with reverse engineering?” arXiv preprint arXiv: 2202.01142, 2022.
|
| [130] |
S. Kim, S. Woo, H. Lee, and H. Oh, “VUDDY: A scalable approach for vulnerable code clone discovery,” in Proc. IEEE Symp. Security and Privacy, San Jose, USA, 2017, pp. 595–614.
|
| [131] |
M. White, M. Tufano, C. Vendome, and D. Poshyvanyk, “Deep learning code fragments for code clone detection,” in Proc. 31st IEEE/ACM Int. Conf. Automated Software Engineering, Singapore, Singapore, 2016, pp. 87–98.
|
Figures(8) / Tables(2)






 DownLoad:
DownLoad: