A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 10
Volume 11
Issue 10
IEEE/CAA Journal of Automatica Sinica
| Citation: | Z. Qiu, S. Wang, D. You, and M. C. Zhou, “Bridge bidding via deep reinforcement learning and belief Monte Carlo search,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 10, pp. 2111–2122, Oct. 2024. doi: 10.1109/JAS.2024.124488

|
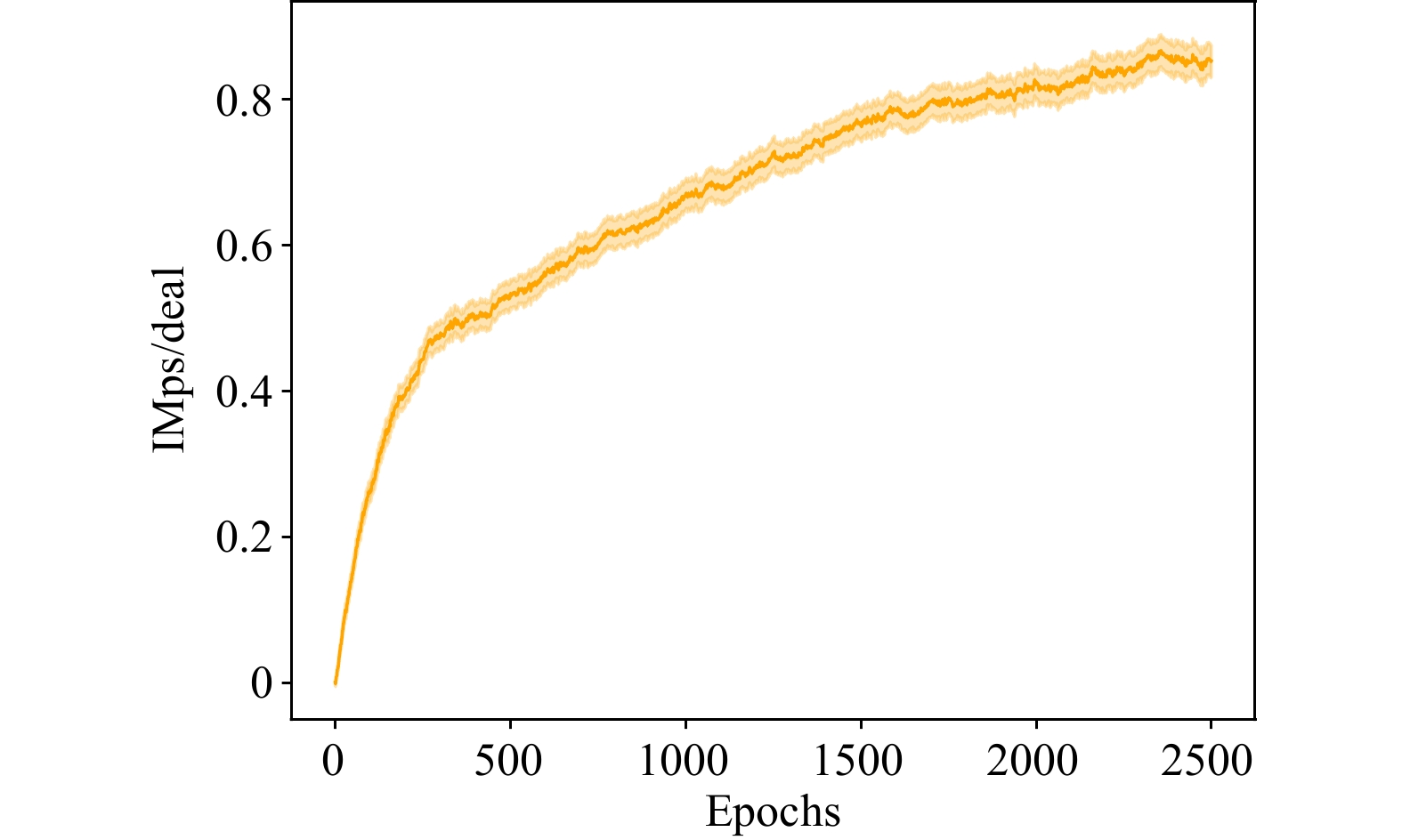
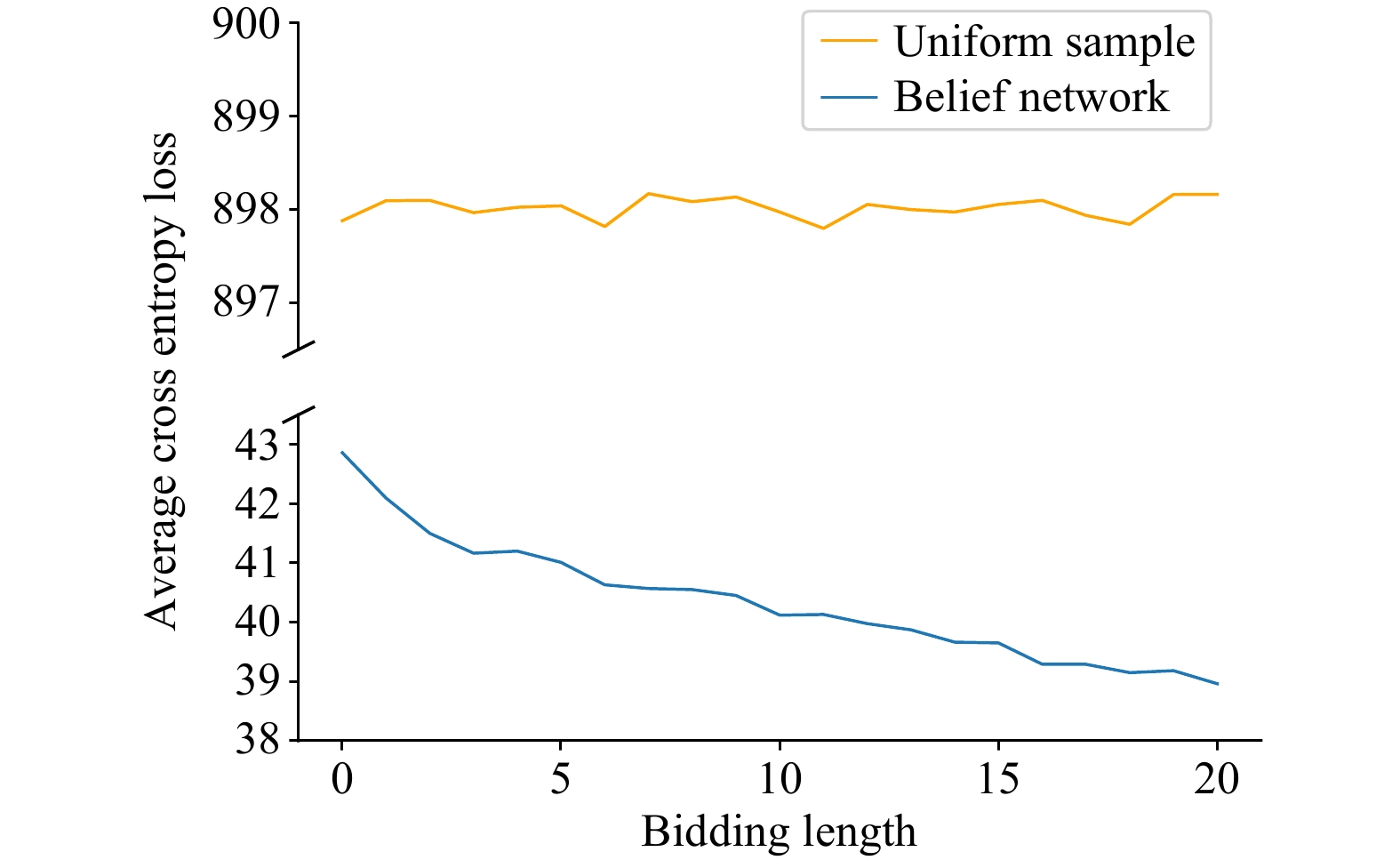
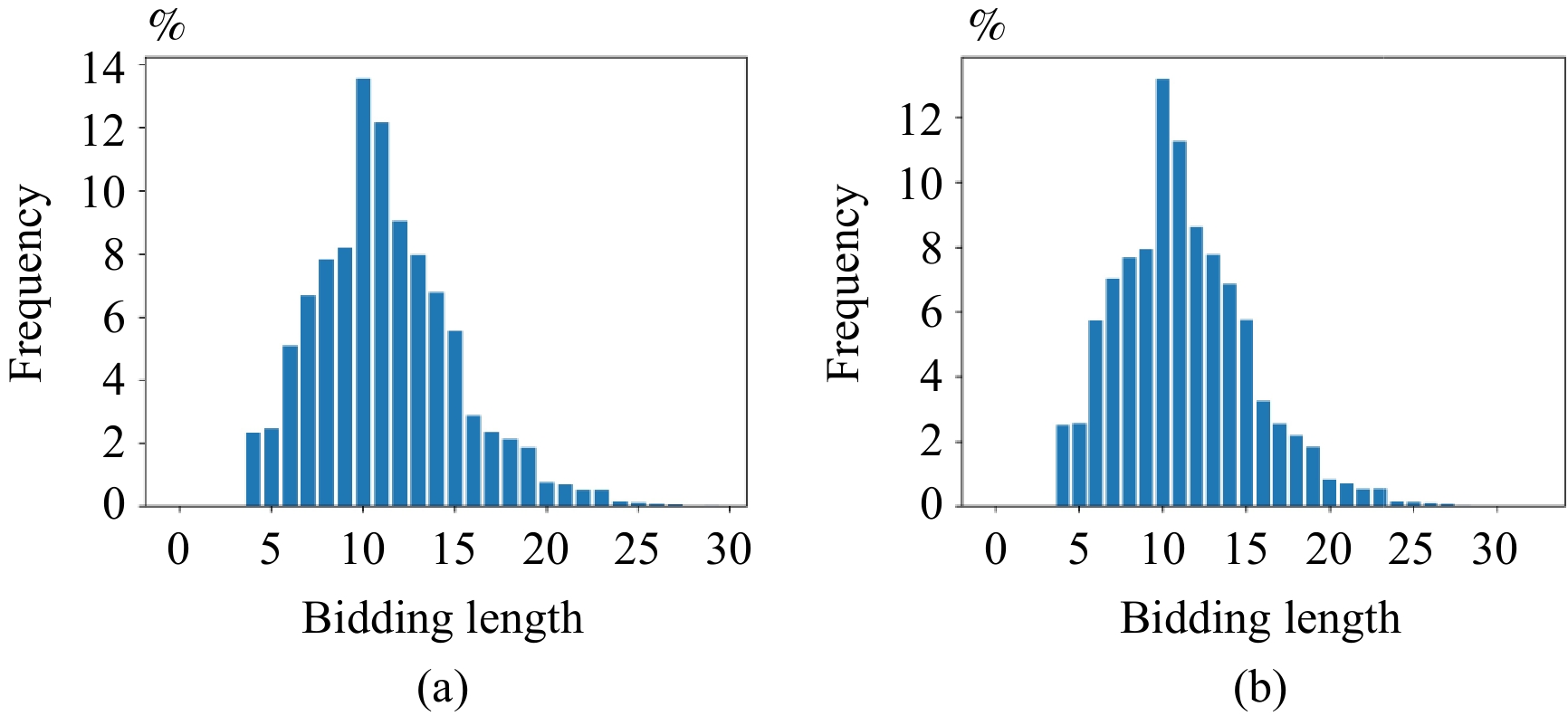
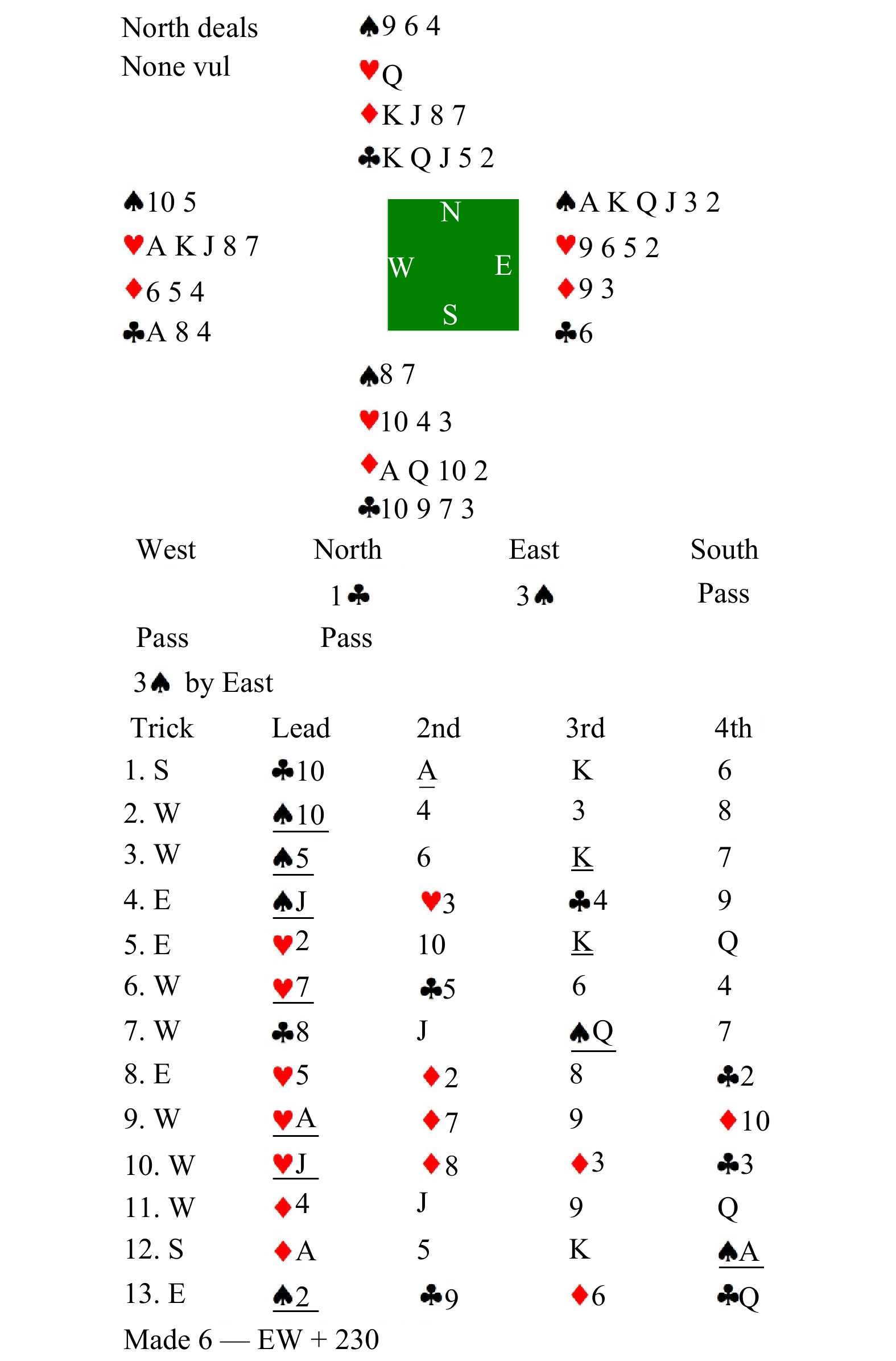
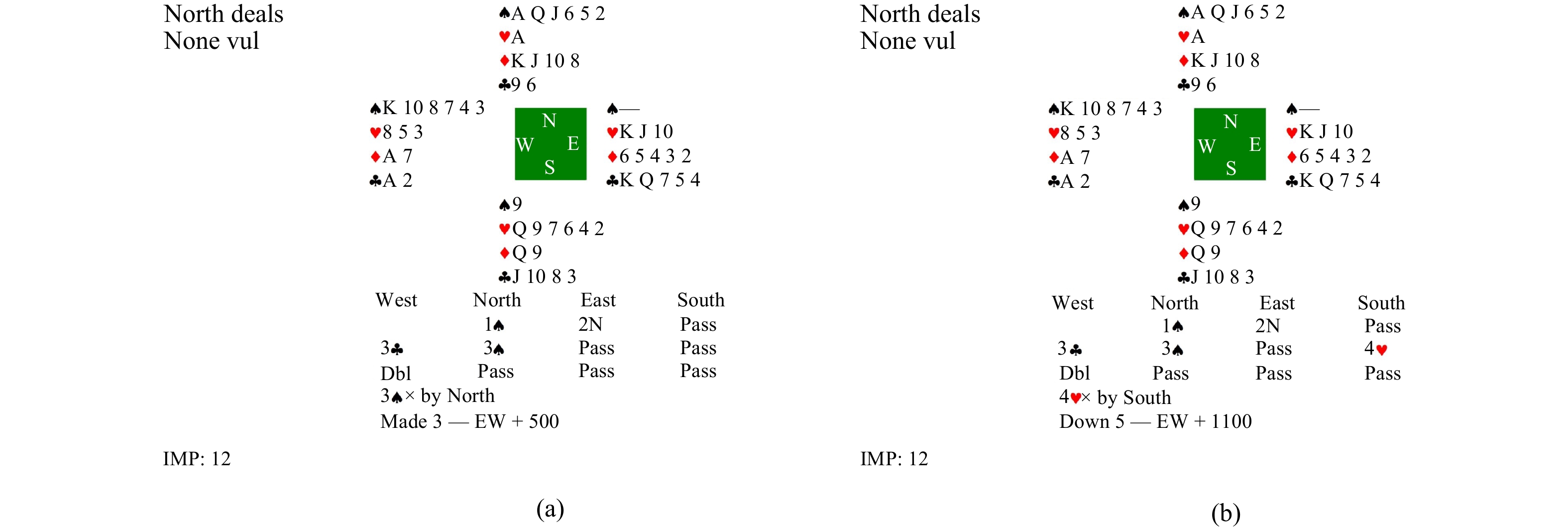
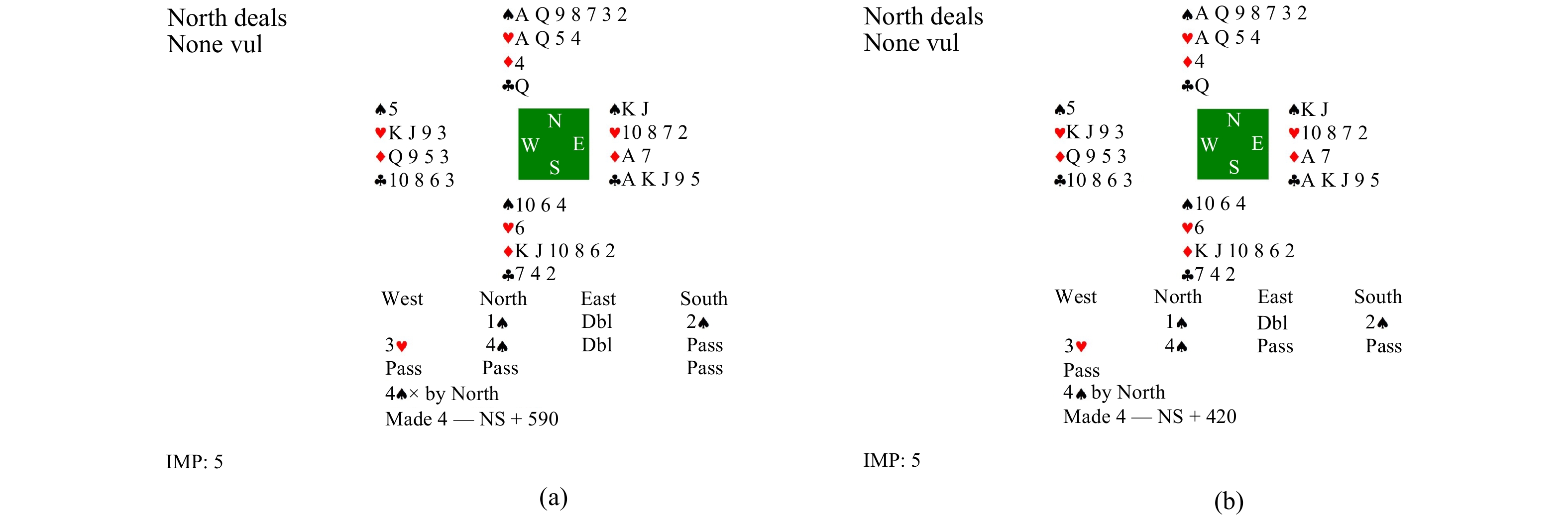
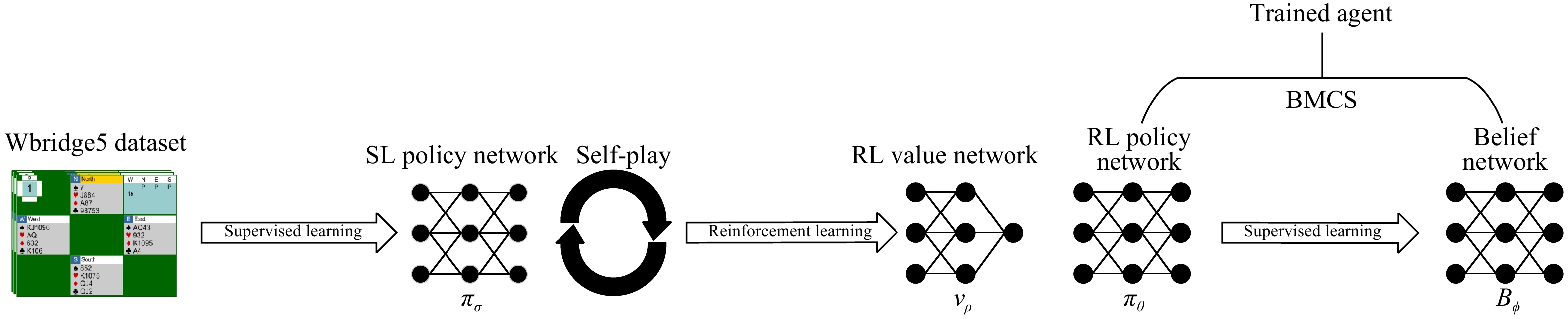
Contract Bridge, a four-player imperfect information game, comprises two phases: bidding and playing. While computer programs excel at playing, bidding presents a challenging aspect due to the need for information exchange with partners and interference with communication of opponents. In this work, we introduce a Bridge bidding agent that combines supervised learning, deep reinforcement learning via self-play, and a test-time search approach. Our experiments demonstrate that our agent outperforms WBridge5, a highly regarded computer Bridge software that has won multiple world championships, by a performance of 0.98 IMPs (international match points) per deal over
deals, with a much cost-effective approach. The performance significantly surpasses previous state-of-the-art (0.85 IMPs per deal). Note 0.1 IMPs per deal is a significant improvement in Bridge bidding.

| [1] |
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, et al., “Mastering the game of Go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484–489, 2016. doi: 10.1038/nature16961
|
| [2] |
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, et al., “Mastering the game of Go without human knowledge,” Nature, vol. 550, no. 7676, pp. 354–359, 2017. doi: 10.1038/nature24270
|
| [3] |
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, et al., “A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play,” Science, vol. 362, no. 6419, pp. 1140–1144, 2018. doi: 10.1126/science.aar6404
|
| [4] |
J. Li, S. Koyamada, Q. Ye, G. Liu, C. Wang, R. Yang, L. Zhao, T. Qin, T.-Y. Liu, and H.-W. Hon, “Suphx: Mastering Mahjong with deep reinforcement learning,” arXiv preprint arXiv: 2003.13590, 2020.
|
| [5] |
N. Brown and T. Sandholm, “Superhuman AI for heads-up no-limit poker: Libratus beats top professionals,” Science, vol. 359, no. 6374, pp. 418–424, 2018. doi: 10.1126/science.aao1733
|
| [6] |
N. Brown and T. Sandholm, “Superhuman AI for multiplayer poker,” Science, vol. 365, no. 6456, pp. 885–890, 2019.
|
| [7] |
D. Zha, J. Xie, W. Ma, S. Zhang, X. Lian, X. Hu, and J. Liu, “Douzero: Mastering Doudizhu with self-play deep reinforcement learning,” in Proc. Int. Conf. Machine Learning. PMLR, 2021, pp. 12333–12344.
|
| [8] |
G. Yang, M. Liu, W. Hong, W. Zhang, F. Fang, G. Zeng, and Y. Lin, “Perfectdou: Dominating Doudizhu with perfect information distillation,” Advances in Neural Information Processing Systems, vol. 35, pp. 34954–34965, 2022.
|
| [9] |
A. Lerer, H. Hu, J. Foerster, and N. Brown, “Improving policies via search in cooperative partially observable games,” in Proc. AAAI Conf. Artificial Intelligence, vol. 34, no. 05, 2020, pp. 7187–7194.
|
| [10] |
H. Hu, A. Lerer, N. Brown, and J. Foerster, “Learned belief search: Efficiently improving policies in partially observable settings,” arXiv preprint arXiv: 2106.09086, 2021.
|
| [11] |
N. Brown, A. Bakhtin, A. Lerer, and Q. Gong, “Combining deep reinforcement learning and search for imperfect-information games,” Advances in Neural Information Processing Systems, vol. 33, pp. 17057–17069, 2020.
|
| [12] |
M. Mazouchi, M. B. Naghibi-Sistani, and S. K. H. Sani, “A novel distributed optimal adaptive control algorithm for nonlinear multi-agent differential graphical games,” IEEE/CAA J. Autom. Sinica, vol. 5, no. 1, pp. 331–341, 2018. doi: 10.1109/JAS.2017.7510784
|
| [13] |
J. Wang, Y. Hong, J. Wang, J. Xu, Y. Tang, Q.-L. Han, and J. Kurths, “Cooperative and competitive multi-agent systems: From optimization to games,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 5, pp. 763–783, 2022. doi: 10.1109/JAS.2022.105506
|
| [14] |
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y. Wang, A. Bayen, and Y. Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,” Advances in Neural Information Processing Systems, vol. 35, pp. 24611–24624, 2022.
|
| [15] |
M. L. Ginsberg, “GIB: Steps toward an expert-level bridge-playing program,” in Proc. Int. Joint Conferences Artificial Intelligence. Citeseer, 1999, pp. 584–593.
|
| [16] |
H. Kuijf, W. Heemskerk, and M. Pattenier, “Jack bridge,” [online]. Available: https://www.jackbridge.com, 2006.
|
| [17] |
Y. Costel, “WBridge5,” [online]. Available: http://www.wbridge5.com, 2014.
|
| [18] |
A. Levy, “World computer-bridge championship,” [online]. Available: https://bridgebotchampionship.com/, 2017.
|
| [19] |
NukkAI, “Nook,” [online]. Available: https://nukk.ai, 2022.
|
| [20] |
E. Lockhart, N. Burch, N. Bard, S. Borgeaud, T. Eccles, L. Smaira, and R. Smith, “Human-agent cooperation in Bridge bidding,” arXiv preprint arXiv: 2011.14124, 2020.
|
| [21] |
V. Ventos, Y. Costel, O. Teytaud, and S. Thépaut Ventos, “Boosting a bridge artificial intelligence,” in Proc. IEEE 29th Int. Conf. Tools with Artificial Intelligence, 2017, pp. 1280–1287.
|
| [22] |
J. Rong, T. Qin, and B. An, “Competitive Bridge bidding with deep neural networks,” in Proc. 18th Int. Conf. Autonomous Agents and MultiAgent Systems, 2019, pp. 16–24.
|
| [23] |
Y. Tian, Q. Gong, and Y. Jiang, “Joint policy search for multi-agent collaboration with imperfect information,” Advances in Neural Inform ation Processing Systems, vol. 33, pp. 19931–19942, 2020.
|
| [24] |
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),” arXiv preprint arXiv: 1606.08415, 2016.
|
| [25] |
R. S. Sutton, D. McAllester, S. Singh, and Y. Mansour, “Policy gradient methods for reinforcement learning with function approximation,” Advances in Neural Information Processing Systems, vol. 12, 1999.
|
| [26] |
Q. Gong, Y. Jiang, and Y. Tian, “Simple is better: Training an end-to-end Contract Bridge bidding agent without human knowledge,” [online]. Available: https://openreview.net/forum?id=SklViCEFPH, 2020.
|
| [27] |
B. Haglund, “Double dummy solver,” [online]. Available: https://github.com/dds-bridge/dds, 2018.
|
| [28] |
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, et al., “Grandmaster level in StarCraft Ⅱ using multi-agent reinforcement learning,” Nature, vol. 575, no. 7782, pp. 350–354, 2019. doi: 10.1038/s41586-019-1724-z
|
| [29] |
T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” arXiv preprint arXiv: 1511.05952, 2015.
|
| [30] |
V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in Proc. Int. Conf. Machine Learning. PMLR, 2016, pp. 1928–1937.
|
| [31] |
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv: 1412.6980, 2014.
|
| [32] |
P. Zhang, S. Shu, and M. Zhou, “An online fault detection model and strategies based on SVM-grid in clouds,” IEEE/CAA J. Autom. Sinica, vol. 5, no. 2, pp. 445–456, 2018. doi: 10.1109/JAS.2017.7510817
|
| [33] |
X. Xie, P. Zhou, H. Li, Z. Lin, and S. Yan, “Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models,” arXiv preprint arXiv: 2208.06677, 2022.
|
| [34] |
M. Lanctot, E. Lockhart, J.-B. Lespiau, V. Zambaldi, S. Upadhyay, J. Pérolat, S. Srinivasan, F. Timbers, K. Tuyls, S. Omidshafiei et al., “Openspiel: A framework for reinforcement learning in games,” arXiv preprint arXiv: 1908.09453, 2019.
|
Figures(10) / Tables(6)






 DownLoad:
DownLoad: