A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
Zhiming Lv, Linqing Wang, Zhongyang Han, Jun Zhao and Wei Wang, "Surrogate-Assisted Particle Swarm Optimization Algorithm With Pareto Active Learning for Expensive Multi-Objective Optimization," IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 838-849, May 2019. doi: 10.1109/JAS.2019.1911450
Citation:
Zhiming Lv, Linqing Wang, Zhongyang Han, Jun Zhao and Wei Wang, "Surrogate-Assisted Particle Swarm Optimization Algorithm With Pareto Active Learning for Expensive Multi-Objective Optimization," IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 838-849, May 2019. doi: 10.1109/JAS.2019.1911450
Zhiming Lv, Linqing Wang, Zhongyang Han, Jun Zhao and Wei Wang, "Surrogate-Assisted Particle Swarm Optimization Algorithm With Pareto Active Learning for Expensive Multi-Objective Optimization," IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 838-849, May 2019. doi: 10.1109/JAS.2019.1911450
Citation:
Zhiming Lv, Linqing Wang, Zhongyang Han, Jun Zhao and Wei Wang, "Surrogate-Assisted Particle Swarm Optimization Algorithm With Pareto Active Learning for Expensive Multi-Objective Optimization," IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 838-849, May 2019. doi: 10.1109/JAS.2019.1911450
Funds:
This work was supported by the National Natural Sciences Foundation of China (61603069, 61533005, 61522304, U1560102) and the National Key Research and Development Program of China (2017YFA0700300)
Zhiming Lv graduated from Shenyang University of Chemical Technology, China, in 2006. He received the M.S. degree from Shenyang University of Chemical Technology in 2010. He is currently working toward Ph.D. degree at the School of Control Science and Engineering, Dalian University of Technology, Dalian, China. His research interests include industrial process modeling, optimization scheduling, and intelligent optimization algorithm
Linqing Wang graduated from Northeastern University (NEU), China, in 2007. She received the M.S. degree and Ph.D. degree from NEU in 2010 and 2014, respectively. She is currently a Senior Lecturer at the School of Control Sciences and Engineering, Dalian University of Technology. Her research interests include the prediction algorithm, industrial optimization, and intelligent algorithm
Zhongyang Han graduated from City Institute, Dalian University of Technology, China, in 2010. He received the Ph.D. degree from Dalian University of Technology, China, in 2016. He is currently engaging in the postdoctoral research with the School of Control Science and Engineering, Dalian University of Technology, Dalian, China. His research interests include computer integrated manufacturing systems, artificial intelligence, data mining, and machine learning
Jun Zhao (M’10) graduated from Dalian Jiaotong University, China, in 2003. He received the Ph.D. degree in engineering from Dalian University of Technology, in 2008. He is currently a Professor with the School of Control Science and Engineering, Dalian University of Technology. His current research interests include industrial production scheduling, computer integrated manufacturing, intelligent optimization, and machine learning
Wei Wang (SM’13) received the B.S., M.S., and Ph.D. degrees from Northeastern University, Shenyang, China, in 1982, 1986, and 1988, respectively, all in industrial automation. He was a postdoctoral fellow with the Division of Engineering Cybernetics, Norwegian Science and Technology University, Trondheim, Norway, from 1990 to 1992, a Professor and Vice Director of the National Engineering Research Center of Metallurgical Automation of China, China, from 1995 to 1999, and a Research Fellow with the Department of Engineering Science, University of Oxford, Oxford, UK, from 1998 to 1999. He is currently a Professor with the School of Control Sciences and Engineering, Dalian University of Technology, China. His current research interests include adaptive controls, computer integrated manufacturing, and computer controls of industrial processes
Corresponding author:
All the authors are with the Faculty of Electronics Information and Electrical Engineering, Dalian University of Technology, Dalian 116024, China (e-mail: lv_zhiming@126.com; wanglinqing@dlut.edu.cn; hzydut@mail.dlut.edu.cn; zhaoj@dlut.edu.cn; wangwei@dlut.edu.cn)
For multi-objective optimization problems, particle swarm optimization (PSO) algorithm generally needs a large number of fitness evaluations to obtain the Pareto optimal solutions. However, it will become substantially time-consuming when handling computationally expensive fitness functions. In order to save the computational cost, a surrogate-assisted PSO with Pareto active learning is proposed. In real physical space (the objective functions are computationally expensive), PSO is used as an optimizer, and its optimization results are used to construct the surrogate models. In virtual space, objective functions are replaced by the cheaper surrogate models, PSO is viewed as a sampler to produce the candidate solutions. To enhance the quality of candidate solutions, a hybrid mutation sampling method based on the simulated evolution is proposed, which combines the advantage of fast convergence of PSO and implements mutation to increase diversity. Furthermore, ε-Pareto active learning (ε-PAL) method is employed to pre-select candidate solutions to guide PSO in the real physical space. However, little work has considered the method of determining parameter ε. Therefore, a greedy search method is presented to determine the value of ε where the number of active sampling is employed as the evaluation criteria of classification cost. Experimental studies involving application on a number of benchmark test problems and parameter determination for multi-input multi-output least squares support vector machines (MLSSVM) are given, in which the results demonstrate promising performance of the proposed algorithm compared with other representative multi-objective particle swarm optimization (MOPSO) algorithms.
MULTI-OBJECTIVE optimization problems are co mmonly encountered in real world [1], e.g., drug design [2], aerodynamic configuration optimization [3] and hyper-parameter optimization for machine learning models [4]. However, the analytic objective or constraints functions in the above cases are difficult to express accurately. Thus, it is a challenge to implement the optimization only based on data collected from physical experiments, real events, or complex numerical simulations [5]. In these cases, it is essential to obtain the desired outcome within a small number of evaluations. Generally, the multi-objective optimization problem can be generalized as follows:
miny=f(x)=(f1(x),f2(x),…,fm(x))
(1)
s.t.x⊂S
(2)
where x∈Rn represents a vector of n decision variables; S⊂Rn indicates the feasible region which is typically specified as a set of constraints on the decision variables; f∈Rm is made of m objective functions which need to be jointly minimized; y is an m-dimensional objective vector.
Considering the high convergence speed and simple implementation, multi-objective particle swarm optimization (MOPSO) attracts great attention which gives rise to a series of variants in the existing literature [6]. Generally, they can be classified into two categories. One is based on the Pareto sorting strategy [7]–[9], and the other employs the decomposition strategy [10], [11]. Although the variants of MOPSO algorithm above have been proved to be with the satisfactory convergence, they require thousands of fitness evaluations to obtain satisfied solutions. As a result, applying MOPSO on computationally expensive problems becomes impractical when a single exact fitness evaluation exhibits a high computational cost. To enhance the performance of most traditional PSOs in solving multi-objective optimization problems, a number of approaches have been proposed [12].
Surrogate-assisted PSO algorithms (SAPSOs) have be found very effective in handling computationally expensive multi-objective optimization problems [13], [14]. Some employ single or multiple surrogates to approximate the fitness function. For instance, a study presented in [15] took use of a response surface model (RSM) rather than finite-element analysis. The Kriging model is applied to gain error compensation function between the approximated values obtained by RSM and the actual measured values in [16]. While others typically estimates the degree of uncertainty to choose certified candidates for re-evaluation, e.g., the Kriging model was combined with MOPSO method to predict the expected improvements of each particle in [17]. Reference [18] captured the uncertainty with the hypervolume to pre-select promising particles for re-evaluation. All of the above studies have shown the effectiveness of SAPSO on reducing the number of fitness function evaluations.
Furthermore, as indicated in [5], [14], surrogate model management is critical for the performance of SAPSOs [19]. A typical strategy is to employ the generation-based method, in which the expensive fitness evaluations are replaced by computationally cheap approximating models [20]. But it is not practical for many extremely expensive problems because a large number of expensive fitness evaluations were needed for an accurate surrogate model [14]. Another known as individual-based model management focus on the determination of individuals demanding evaluation for each generation. Three criteria, such as minimizing the predicted fitness [21], minimizing the prediction uncertainty [18] and a combination of the previous two [22] are normally used to select new candidate solutions to be evaluated. However, it is difficult to strike a proper balance between exploration and exploitation [19]. Besides, active learning (AL) is a commonly deployed alternative for model management. In such a case, the new training data are actively queried for efficiently improving the approximation quality of the current model without significantly increasing the size of training dataset. Also, AL terminates when any additional training data have no effect on the information gain [23].
As already shown in [24], AL-based methods can also be used for solving the multi-objective optimization problem. For example, an active learning method of the Pareto front was reported in [23], in which a surrogate model was constructed to approximate the Pareto front. A PSO assisted by the active learning method based on the committee was presented in [19], but it only considered the single objective problem with the high computational cost. In [25], a Pareto active learning (PAL) method was proposed to predict the Pareto optimal solutions. In comparison to the state-of-the-art algorithm PAL, a ε-Pareto active learning (ε-PAL) was presented in [26] to reduce computational complexity. However, how to select ε for achieving a satisfied tradeoff between prediction accuracy and classification cost is a challenge.
In this paper, we assume that the optimization algorithm is allowed to evaluate a small number of selected solutions during optimization. It should be noted that we focus on developing a surrogate-assisted PSO with Pareto active leaning so as to effectively accelerate the convergence process. The main contributions of this work can be highlighted as follows:
1) A mixed mutation sampling method based on simulated evolution is proposed to enhance the quality of the candidate solutions. Based on the advantage of fast convergence of PSO, the evolution of the swarm is simulated with the surrogate model rather than the true fitness function. And the particles which are beyond the Pareto front and locate at the sparse part of the Pareto front are carried out the mutation operation to promote the diversity of the population. Then the positions of the offspring are considered as the candidate solutions.
2) A classification strategy using the improved ε-PAL is employed to identify candidate solutions that are Pareto-optimal and not Pareto-optimal. It is wellknown that the prediction accuracy and classification cost are controlled by parameter ε. However, the mathematical relationship between parameter ε, prediction accuracy and classification cost are not clear. This poses a challenge for determining the value of ε. Therefore, a greedy search method is suggested to select ε where the number of active sampling is employed as the evaluation criteria of the classification cost.
3) A surrogate-assisted PSO with Pareto active learning is proposed to solve the computationally expensive optimization problems with multiple objectives. The Pareto-optimal solutions obtained by ε-PAL are used to guide the global search of the swarm, while the history information of PSO is employed to update the surrogate models.
The rest of this paper is organized as follows. Section II presents a brief introduction to PSO, Gauss process modeling and ε-PAL. Then, a surrogate-assisted PSO with Pareto active learning is proposed in Section III. In Section IV, the results obtained from the numerical studies on eight benchmark test problems and two MLSSVM model optimization problems with the proposed algorithm are discussed. Finally, Section V draws the conclusions for this study.
II.
Preliminaries
A
Particle Swarm Optimization
PSO [27] adopts experiences from both individuals and swarms to guide the direction of evolution. Assuming the population size is known as NP, the velocity and the location of the ith particle at t generation are updated as follows:
where ω indicates the inertia weight; c1 and c2 are the learning rate; r1 and r2 represent the random numbers which are belong to (0,1); pi(t) and pg(t) stand for the personal best and the global best at t generation, respectively.
B
Gaussian Process Modelling
Gauss process (GP) [28] surrogate model is employed to approximate each objective. For the jth objective, the response function is expressed as y(xi)=f(xi)+ζ, where f(xi) indicates the mapping function between the input x1:N and the output y1:N; ζ∼N(0,δ2y) denotes the Gaussian noise. With the GP prior, the response function of the jth objective is formulated as y∼N(K(x1:N,x1:N)+δ2yI). Given the new point x∗, the mean μj(x∗) and variance δ2j(x∗) are expressed as follows:
where μj and δ2j indicate the predicted mean value and variance for the jth objective, respectively; K denotes the covariance matrix using the squared exponential function k(xp,xq)=δ2sexp(−12(xp−xq)TW(xp−xq)), where δ2s represents the signal variance and W is the widths of the kernel.
C
ε-Pareto Active Learning
The ε-PAL [26] method is a classification method which is utilized to find ε-accurate Pareto front with as few function evaluations as possible. In ε-PAL, GP models are adopted to predict the candidate solutions that have not been evaluated yet. Furthermore, the predictive uncertainty is employed to guide the iterative sampling. Specifically, the sampling strategy is designed to maximize the probability that candidate solutions are Pareto-optimal. With a set of classification rules, the candidate solutions are identified as the Pareto-optimal and non-Pareto-optimal solutions with high probability. At last, ε-PAL terminates when all the candidate solutions are classified. The computing procedures for ε-PAL are summarized as Algorithm 1.
Algorithm 1 The framework of ε-PAL
Input:Ui (undecided points), Pi (predicted set), ε (user-controlled parameter)
1: Initialize U1=E, P1=∅ and set i=1.
2: whileUi≠∅do
3: Construct the surrogate model for each objective using (5) and (6).
4: Assign the uncertainty region Ri(x) for each point x∈Ui∪Pi.
5: Discard the points in Ui which are ε-dominated by another point with high probability.
6: Move the points that belong to the ε-Pareto front of E from Ui to Pi.
III.
The Proposed Surrogate-Assisted PSO Algorithm With Pareto Active Learning
A
The Overall Framework
In this paper, the evaluation of the fitness function is considered to be computationally expensive. In order to obtain Pareto optimal solutions with the limited number of the fitness evaluations, a novel surrogate-assisted PSO with the help of Pareto active learning, termed PAL-SAPSO, is proposed in this section.
The pseudo code of PAL-SAPSO is given as Algorithm 2, which can be summarized as six procedures as follows:
1) Initialization (line 1): NP particles are generated using Latin hypercube sampling, which are evaluated using the fitness function. Then the external archive and the knowledge base are initialized.
2) Swarm update (line 3 to 4): The swarm is updated with the personal best and the global best.
3) Construction of surrogate model (line 7): The surrogate model is built with data in the knowledge base to approximate the fitness function for each objective.
4) Sampling of candidate solution set (line 8): The mixed mutation sampling method based on the simulated evolution is implemented to get the candidate solutions.
5) Classification of candidate solution set (line 9): The improved ε-PAL is employed to categorize the candidate solutions into Pareto-optimal solutions and non-Pareto-optimal ones.
6) Update of the external archive (line 10): The external archive is updated by pre-selecting results from the improved ε-PAL.
7) Repeat Step 2) to Step 6) until the maximum number of fitness evaluations is reached.
In PAL-SAPSO, the sampling method and the classification strategy are crucial for the success of the algorithm. We will discuss them in detail in the following subsections.
Algorithm 2 The framework of PAL-SAPSO
Input:NP (population size), v (velocity), x (position), A (external archive), Dt (knowledge base with Nt samples at t generation), Nmax (maximum number of the fitness evaluations).
1: Initialize NP, v, x, A, Dt and set Nt=NP.
2: whileNt≤Nmaxdo
3: Select the personal best pi(t) and the global best pg(t).
4: Update v(t) and x(t) using (3) and (4), and calculate the corresponding fitness f(x).
5: Update A (Using Algorithm 5).
6: Update Dt with {x,f(x)}.
7: Construct the surrogate model for each objective using (5) and (6).
8: Get the candidate solution set (Using Algorithm 3).
9: Get the ε-accurate Pareto optimal solution set (Using Algorithm 4).
10: Update A (Using Algorithm 5).
11: Update Dt.
12: Count the number of the fitness evaluations Nt.
B
A Hybrid Mutation Sampling Method Based on the Simulated Evolution
For maintaining convergence and diversity of the candidate solutions, a hybrid mutation sampling method based on simulated evolution is proposed. The main framework of the sampling method is listed in Algorithm 3.
1) Simulated Evolution of the Particle Swarm: The PSO algorithm tries to find the optimal solution using a population of particles. Based on (3) and (4), it is clear that the trajectories drawn by the particles are semi-random in nature, as they derive from the contribution of systematic attraction towards the personal and global best solutions and the stochastic weighting of two acceleration terms [27]. Furthermore, PSO is known to have a very high convergence speed. Inspired by the above ideas, a sampling method based on the simulated evolution is designed to obtain the candidate solutions.
Let us assume that the population of the tth generation in the real physical space is migrated into the virtual space where the cheap surrogate models are employed to take place of the computationally expensive fitness functions. Then the information of the initial population is expressed as x′i(1)=xi(t), v′i(1)=vi(t), ˆpi(1)=pi(t), ˆpg(1)=pg(t) and ˆA(1)=A(t). With the initial information, the velocity and position of each particle are updated as follows:
where v′i(k) and x′i(k) indicate the velocity and the position of the ith particle in the virtual space at the kth iteration in the virtual space. ˆpi(k) and ˆpg(k) denote the personal best and the global best of the swarm at the kth iteration in the virtual space; ˆA and A are the external archives in the virtual space and the real physical space, respectively.
In the process of simulated evolution, the surrogate models based on GP are used to replace the real fitness function. Based on the experience knowledge base Dt={xi,yi,j|1≤i≤Nt,1≤j≤m}, m surrogate models are constructed for m objectives. Given any position of particle x′i, fitness is estimated by ˆyi=(μ1(x′i),…,μm(x′i)), where μj(⋅) represents the estimated value of the jth surrogate model. Then the personal best and the global best are updated as presented in Section III-D.
2) Mutation on Particles Beyond the Pareto Front: Although particles which float away from the Pareto front are useful for maintaining the diversity of the population, they will slow down the convergence speed. In addition, non-dominant solutions are usually required to be as close as possible to the real Pareto front. Therefore, the mutation operation moving the particles towards to the Pareto front can not only accelerate the convergence speed, but also improve the quality of the solution.
The particles which are beyond the Pareto front are identified first. The approximate Pareto front corresponding to the non-dominant solutions in the external archive is used as the reference front because of the real Pareto front is usually unknown. In the object space, the Euclidean distances between the fitness values of the particles and the reference front are different. Then, the particles whose Euclidean distance is larger than the average distance are considered to be far from the Pareto front, as expressed in the following formula:
O={x′h|h=find(li>ˉl)}
(9)
li=min(‖
(10)
where O denotes the set of the particles which are far from the Pareto front; {{x}}^{\prime} indicates the position of the particle which beyond the Pareto front; l_{i} indicates the Euclidean distance between the fitness values of the i\mathrm{th} particle and the closest non-dominant solution; \bar{l} is the mean of l_{i} ; find(\cdot) represents the query function on the index of the element; \widehat{A}(k) stands for the external archive at the k\mathrm{th} iteration in the virtual space; \widehat{{{y}}}_{i} indicates the estimated values of the fitness of i\mathrm{th} particle; {{a}}_{j} denotes the fitness values of the non-dominant solutions on the Pareto front.
Let {{x}}^{\prime}_{i} is the particle beyond the Pareto front, then the mutation operation is carried out as follows:
where {{x}}^{\prime \prime}_{i}(k) indicates the new position of the i\mathrm{th} particle in the virtual space at the k\mathrm{th} iteration; {{x}}^{\ast}_{i} denotes the closest non-dominant solution to {{x}}^{\prime} ; r\in\{0, 1\} .
3) Mutation to Particles Locating at the Sparse Part of the Pareto Front: In the process of simulated evolution, a large number of particles will aggregate to the individual non-dominant solution according to the fast convergence of PSO. It causes that parts of Pareto front correspond to more non-dominant solutions, while others correspond to fewer. Then, the diversity distribution of the solutions becomes worse. Therefore, it is an effective method to identify the sparse parts of the Pareto front and generate new non-dominant solutions in the sparse parts.
First of all, the particles which locate at the sparse part of the Pareto front are identified. The Pareto front constructed by the non-dominant solutions in the external archive is also used as the reference front. For any objective, the fitness values of the non-dominant solutions in the external archive are arranged in ascending order and the Euclidean distance between two adjacent non-dominant solutions is computed. When the Euclidean distance of the two non-dominant solutions is larger than the average distance of all adjacent non-dominant solutions, the part between two non-dominant solutions is considered to be sparse according to the following formula:
S = \{({{x}}^{\ast}_{h}, {{x}}^{\ast}_{h+1})|h = find(d_{i}>\bar{d})\}, {{x}}^{\ast}_{h}\in \widehat{A}(k)
where S denotes the set of the sparse parts of the Pareto front; {{x}}^{\ast}_{h} and {{x}}^{\ast}_{h+1} represent the non-dominant solutions at the edge of the sparse part of the Pareto front; d_{j} indicates the Euclidean distance of the two adjacent non-dominant solutions; \bar{d} is the mean of d_{j} .
Let {{x}}^{\ast}_{h} and {{x}}^{\ast}_{h+1} denote the non-dominant solutions at the edge of the sparse part of the Pareto front. Then, both particles move towards each other. The mutation operation is formulated as
where {{x}}^{\prime \prime \prime}(k) indicates the position of the new particle which locates at the sparse part of the Pareto front in virtual space at the k\mathrm{th} iteration.
4) A Hybrid Mutation Sampling Strategy Based on the Simulated Evolution: In the process of the simulated evolution, the positions of the particles involving the offspring and the particles which are beyond the Pareto front and locate at the sparse part of the Pareto front are updated at each generation. To get more information on position in the search space, the swarm is simulated \eta generations in virtual space. Then the candidate solutions obtained by mutation operation are determined as
where X_{\rm pss} denotes the set of candidate solutions; {{x}}^{\prime} , {{x}}^{\prime \prime} and {{x}}^{\prime \prime \prime} indicate the candidate solutions which are obtained from three mutation operations, respectively.
Algorithm 3 A hybrid mutation sampling method based on the simulated evolution
Input:{v}^{\prime} (velocity), {x}^{\prime} (position), \widehat{{p}}_{i} (personal best), \widehat{{p}}_{g} (global best), \widehat{A} (external archive), \eta (maximum number of generations).
3: Update {{v}}^{\prime}(k) and {{x}}^{\prime}(k) using (7) and (8).
4: Evaluate the fitness based on (5).
5: Determine the particles which are beyond Pareto front using (9) and (10), and obtain new particles {{x}}^{\prime \prime}(k) based on (11).
6: Determine the particles which locate the sparse part of the Pareto front using (12) and (13), and obtain the new particles {{x}}^{\prime \prime \prime}(k) based on (14).
7: Get the set of the candidate solution X_{\rm pss} according to (15).
8: Update \widehat{A}(k) with \{X_{\rm pss}, \widehat{{{y}}}(X_{\rm pss})\} .
9: Select the personal best \widehat{{{p}}}_{i}(k) and the global best \widehat{{{p}}}_{g}(k) .
C
Classification Using Improved \varepsilon -Pareto Active Learning
In PAL-SAPSO, \varepsilon -PAL is employed to categorize the candidate solutions. Although the Pareto-optimal set obtained by \varepsilon -PAL is likely to be Pareto-optimal at current generation, but the candidate solutions can not cover the whole search space. As a result, the predicted Pareto-optimal set may not belong to the true Pareto front for the problem to be solved. Furthermore, the fitness function is computational expense, the classification cost from the sampling and the evaluations of the predicted Pareto-optimal solutions must be considered. In order to achieve a tradeoff between prediction accuracy and the classification cost, an improved \varepsilon -PAL is proposed, as described in Algorithm 4.
As suggested in [26], the \varepsilon -PAL automatically stops when the target accuracy \varepsilon is achieved with confidence 1-\varpi . Obviously, once the target accuracy \varepsilon is fixed, there is a theoretical boundary for the sampling number. In turn, the target accuracy \varepsilon can be obtained when the sampling number is given.
From line 7 in Algorithm 1, it is clear that each point in U_{i}\cup P_{i} have the possibility of being sampled. Let the desired number of evaluations, T , is equal to the number of the points in U_{i}\cup P_{i} . Then, the prediction accuracy \varepsilon is determined if the classification cost T is given. In order to achieve a balance between prediction accuracy \varepsilon and classification cost T , the resulting nonlinear programming problem can be expressed as follows:
where n_{j} denotes the number of the points in U_{i}\cup P_{i} at the j\mathrm{th} greedy search; \varepsilon_{l} and \varepsilon_{u} represent the upper and lower bound of the target accuracy \varepsilon , respectively.
Taking (16) into account, it is apparent that satisfactory prediction accuracy can be found under the expected classification cost. As a result, a balance strategy is presented by solving (16) greedily in the following form:
where \tau represents the learning factor, \tau\in\{0, 1\} ; \Delta denotes the speed of searching. Based on the balance strategy, a set of \varepsilon -accurate Pareto optimal solutions \widehat{P}_{T} is obtained with the desired classification cost T .
Algorithm 4 The framework of improved \varepsilon-PAL
Input:U_{i} (undecided points), P_{i} (predicted set), T\; (classification cost), N_{\rm GS} (maximum number of greedy searches), \tau (learning factor).
1: Initialize U_{1}=X_{\rm pss} , P_{1}= \emptyset , \varepsilon\in [\varepsilon_{l}, \varepsilon_{u}] , U^{\prime}= \emptyset , P^{\prime}= \emptyset and set i=1
2: while U_{i}\neq \emptyset do
3: Assign the uncertainty region R_{i}({{x}) for each point {{x}\in U_{i}\cup P_{i}
4: Discard the points in U_{i} which are \varepsilon -dominated by another point with high probability.
5: Move the points that belong to the \varepsilon -Pareto front of X_{\rm pss} from U_{i} to P_{i} .
6: Count the number of the points n_{1} in U_{i}\cup P_{i} .
7: Initialize U^{\prime}_{1}=U_{i} , P^{\prime}_{1}=P_{i} and set j=1 .
8: while n_{j}>T or j<N_{\rm GS} do
9: Assign the uncertainty region R^{\prime}_{j}({{x}^{\prime}) for each point {{x}^{\prime}\in U^{\prime}_{j}\cup P^{\prime}_{j} .
10: Determine the value of \varepsilon using (17) to (19).
11: Discard the points in U^{\prime}_{j} which are \varepsilon -dominated byanother point with high probability.
12: Move the points that belong to the \varepsilon -Pareto frontof X_{\rm pss} from to U^{\prime}_{j} P^{\prime}_{j} .
13: j=j+1 .
14: Count the number of the points n_{j} in U^{\prime}_{j}\cup P^{\prime}_{j} .
15: Save the value of \varepsilon .
16: end while
17: Sample a point from U_{i}\cup P_{i} .
18: i=i+1 .
19: end while
Output: The \varepsilon-accurate Pareto set \widehat{P}_{T}=P_{i}.
For the multiobjective optimization problems, PSO intends to search for a set of non-dominated solutions to be stored in an external archive with a predefined size N_{\rm rep} . After initializing the PSO population, every particle will fly toward the direction guided by its personal best and global best. However, the PSO-based algorithm may converge to a false Pareto front because of its very high convergence speed. Therefore, it is important to ensure that the particles in the population move toward a more sparse and promising region in the search space.
At the t\mathrm{th} generation, the personal best of the i\mathrm{th} particle {{p}}_{i}(t) is updated by a new solution {{x}}_{i}(t+1) found by this particle if {{p}}_{i}(t) is dominated by {{x}}_{i}(t+1) . And, the personal best of the i\mathrm{th} particle is selected between {{p}}_{i}(t) and {{x}}_{i}(t+1) randomly if they are non-dominated with respect to each other.
The global best {{p}}_{g}(t) is selected from the external archive randomly, which is useful in guiding the particle to fly in the different direction. In addition, the external archive is updated with the approximate Pareto solution set \widehat{P}_{T} to enhance the social experience of the population, as described in Algorithm 5. Here, the popular archive update mechanism used in [6] is also adopted, which is based on both Pareto dominance and crowding distance.
Algorithm 5 Archive update
Input:\widehat{P}_{T} (\varepsilon-accurate Pareto set), A (external archive), N_{\rm rep} (size of external archive)
1: for i=1 to |\widehat{P}_{T}| do
2: if \widehat{P}_{i} is dominated by any member in A then
3: Discard \widehat{P}_{i} .
4: else if \widehat{P}_{i} dominates a set of member in A then
5: A=A \cup \{\widehat{P}_{i}\} .
6: else if \widehat{P}_{i} and any member of A are non-dominatedwith each other then
7: A=A \cup \{\widehat{P}_{i}\} .
8: end if
9: if |A| > N_{\rm rep} then
10: Calculate the crowding distance value for each solution in A .
E
Computational Complexity of One Generation of the Proposed Algorithm
The proposed algorithm in this study consists of a hybrid mutation sampling method based on simulated evolution, improved \varepsilon -PAL and PSO. Firstly, in the hybrid mutation sampling method based on simulated evolution, 1) implementation of PSO requires {\rm{O}}(NP\times N^2_{\rm rep}) computations. 2) Construction of the surrogate models require {\rm{O}}(m\times N^3_{t}) computations. 3) Assuming the number of candidate solutions is N_{\rm pss} = (NP+N_{\rm rep})\times \eta (In fact, the number of candidate solutions is smaller than the hypothetical value because not all particles implement mutation). Thus, the estimation of the candidate solutions require {\rm{O}}(N_{\rm pss}\times N^2_{t}) computations. Due to N_{t} increases dynamically, the worst-case complexity of the hybrid mutation sampling method based on simulated evolution is {\rm{O}}(m\times N^3_{t}) . Secondly, in the improved \varepsilon -PAL, 1) determination of the value of \varepsilon requires {\rm{O}}(N_{\rm pss}{\rm log}(N_{\rm pss})\times N_{\rm GS}) computations ( \varepsilon -PAL requires {\rm{O}}(n{\rm log}(n)) computations on every iteration [26], where n indicates the number of the undecided points), where N_{\rm GS} is the number of greedy searches. 2) Identification of Pareto solutions require {\rm{O}}(m\times (N_{t}+T-1)^3+(N_{t}+T-1)^2) computations (In the worst case, the active sampling is carried out T times and 1{\rm log}(1) = 0 ). Thus, considering the worst case, the complexity of the improved \varepsilon -PAL is {\rm{O}}(m\times (N_{t}+T-1)^3+(N_{t}+T-1)^2) . And finally, PSO optimizer requires {\rm{O}}(NP\times N^2_{\rm rep}) computations. Considering all the above computations, the overall worst-case complexity of generation of the proposed algorithm is {\rm{O}}(m\times (N_{t}+T-1)^3+(N_{t}+T-1)^2).
IV.
Experimental Studies
A
Comparative Experiment on Benchmark Problems
To verify the performance of the proposed method (PAL-SAPSO), three existing MOPSO algorithms were employed to make a comparison with a set of widely used benchmark test problems. Three state-of-the-art MOPSO algorithms include standard MOPSO [27], decomposition-based multi-objective particle swarm optimization (dMOPSO) [29] and speed-constrained multi-objective PSO (SMPSO) [30]. Both dMOPSO and SMPSO are improved version of standard MOPSO. In addition, dMOPSO is based on decomposition strategy and SMPSO adopts Pareto sorting strategy. The source codes of three MOPSO algorithms are provided in PlatEMO [31]. All parameters are set to the recommended values in the original papers.
A total of 8 test problems with two objectives are used to evaluate the performance of the algorithms, where ZDT1, ZDT2, ZDT3, UF1, UF2, UF4 and UF7 have 6 decision variables and ZDT6 is 10. The mathematical description of the test problems was given in [32]. The inverted generational distance (IGD) metric [33] is deployed as the index for evaluating the performance of the compared algorithms, and almost 1000 points uniformly sampled on the Pareto front are used in the calculation of IGD for each test problem. The IGD is defined as follows:
where P_{\rm true} represents the true Pareto front reference points; P_{\rm rep} denotes the non-dominant solution in the external archive; dis({{x}}, P_{\rm rep}) denotes the Euclidean distance between {{x}} and the non-dominant solution in the external archive; |P_{\rm true}| is the number of real Pareto forward reference points. The IGD is a metric for evaluating the quality of obtained solution set in terms of both convergence and distribution. The smaller the IGD value, the better the quality of solution set obtained by the algorithm.
The parameters of the proposed algorithm PAL-SAPSO are set as follows: the population size is set to NP = 30 ; the inertia weight is set to \omega = 0.5 ; the learning rate is set to c_{1} = 1 and c_{2} = 2 ; the generation of the simulated evolutionary is set to \eta = 20 ; the learning factor is set to \tau = 0.02 ; the prediction accuracy is set to \varepsilon\in \{0, 1\} , the classification cost is set to T = 5 and the number of the greedy searches is set to N_{\rm GS} = 1000 . For each test problem, 20 independent experiments are conducted and the maximum number of the fitness evaluations is set to 500, 1000, 1500 and 2000. All experimental results are obtained on a PC (with an Intel Core i5 6200U CPU) and MATLAB 2017a.
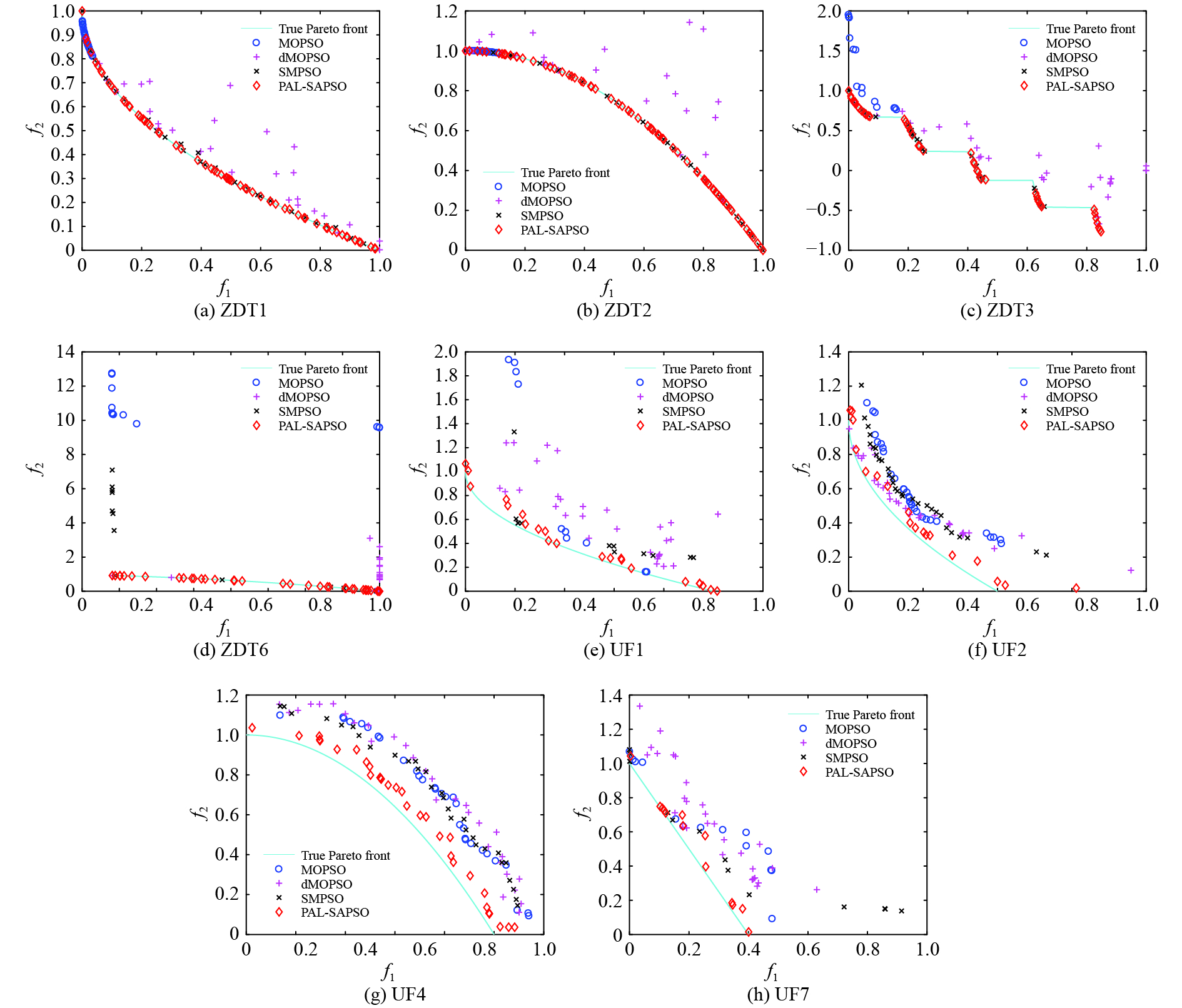
The comparative results from 4 algorithms (MOPSO, dMOPSO, SMPSO, and PAL-SAPSO) with 500 function evaluation on ZDT and UF test problems are showed in Table I. The statistical results consist of the mean (the corresponding standard deviation) of IGD which are obtained from 20 independent experiments. It can be seen from Table I that the mean of IGD from PAL-SAPSO is smaller than the other algorithms. It exhibits that the Pareto fronts obtained by PAL-SAPSO have the best performance on the convergence and the distribution. And, the standard deviation of the means from PAL-SAPSO are the smallest. It shows that PAL-SAPSO has good stability. To clearly visualize the comparison of results, the Pareto fronts which are obtained by 4 algorithms with 500 function evaluation on ZDT and UF test problems are illustrated in Fig. 1. The results in Fig. 1 correspond to the smallest values of IGD in the 20 independent experiments. It can be concluded that PAL-SAPSO effectively converges to the true front and find the more diverse solutions compared to MOPSO, dMOPSO and SMPSO.
Table
I.
Comparative Results From 4 MOPSO Algorithms
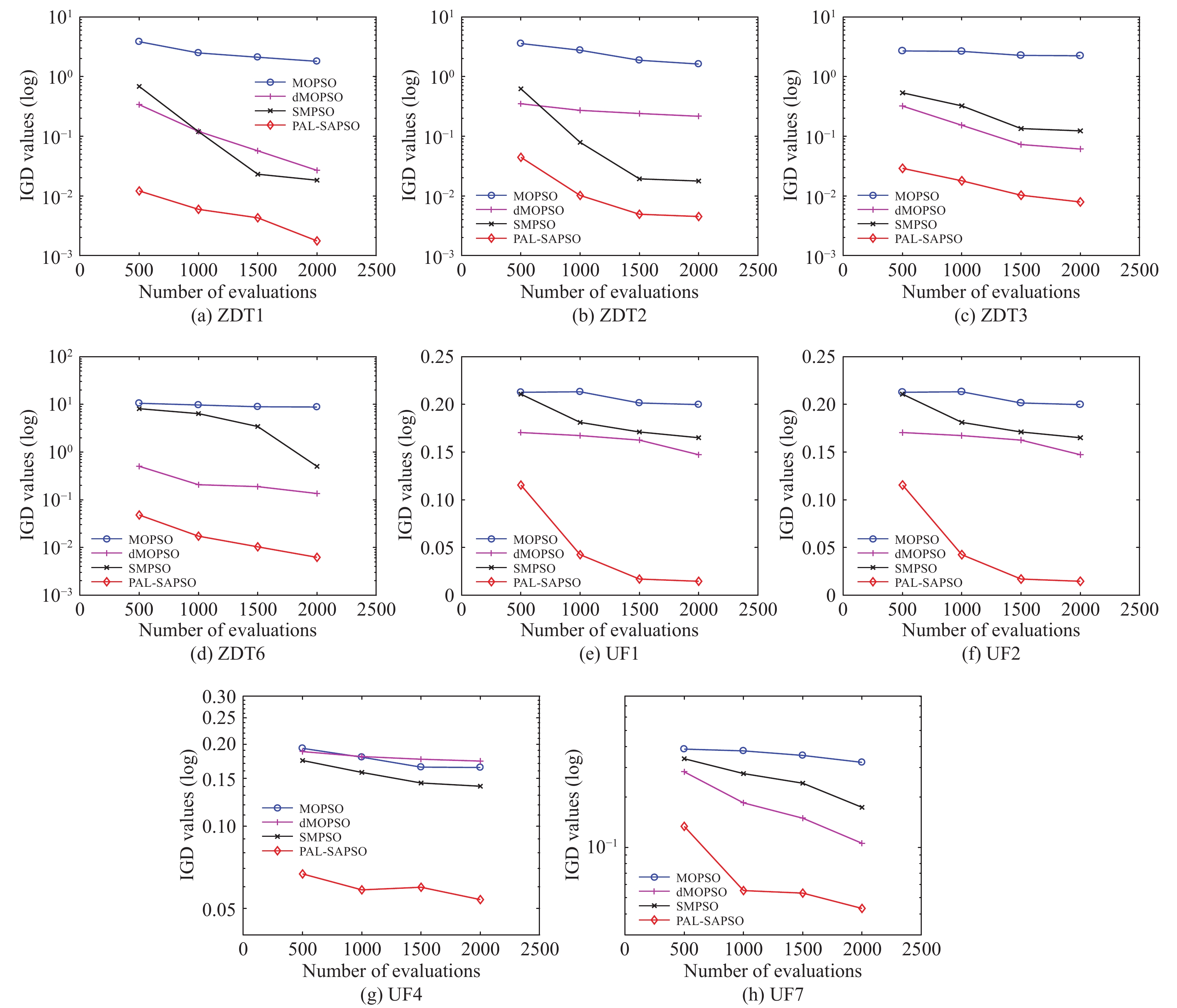
To further investigate the convergence of PAL-SAPSO, the mean of IGD from MOPSO, dMOPSO, SMPSO, and PAL-SAPSO on ZDT and UF test problems with the 500, 1000, 1500, and 2000 fitness evaluations are shown in Fig. 2. As shown in these figures, the convergence of PAL-SAPSO is better than MOPSO, dMOPSO and SMPSO.
Figure
2.
The convergence results obtained by algorithms on 8 test problems.
In summary, compared with MOPSO, dMOPSO and SMPSO, the Pareto fronts obtained by PAL-SAPSO have better performance on convergence and distribution with the same number of the fitness evaluations.
B
Comparative Experiments on Parameter Determination for MLSSVM-based Model
In order to further verify the effectiveness of the proposed algorithm, two application problems arising from the parameter determination for MLSSVM-based models [34] are employed. In general, the generalization capability of the data-driven model is evaluated by the multifold cross-validation method [35].
For predicting an output vector {{y}}\in\mathbb{R}^{m} from a given input vector {{x}}\in\mathbb{R}^{n} , the MLSSVM-based model is established by solving a constraint-based optimization problem [34]
Once the Lagrangian function is constructed with respect to (21) and (22), a linear system is obtained with Karush-Kuhn-Tucker (KKT) conditions as follows:
where {{P}} = blockdiag({\bf{1}}_{l}, {\bf{1}}_{l}, \dots, {\bf{1}}_{l})\in \mathbb{R}^{ml\times m} , {{H}} = \Omega+\gamma^{-1}{\bf{I}}_{ml}+ (m/ \lambda){{Q}}\in \mathbb{R}^{ml\times ml} is the positive definite matrix. If the solutions ( \alpha^{\ast} and {{b}}^{\ast} ) of (23) are obtained, one can get the corresponding decision function for multiple outputs as follows:s
where k({ x}, { y}) = {\rm exp}(-\dfrac{1}{2\delta^{2}}\|{ x}-{ y}\|^{2}) . Three parameters (two positive real regularized parameters \lambda , \gamma and kernel parameter \delta ) in MLSSVM model should be determined. In order to obtain a MLSSVM regression model with the satisfactory generalization, the 10-fold cross-validation method is adopted. The optimization problem is described as follows:
where {{E}} represents the cross-validation error (the mean square error); f({\theta})_{j} denotes the j\mathrm{th} objective function; A_{{\theta}} indicates the MLSSVM model with the parameters {\theta} = (\lambda, \gamma, \delta) ; L(A_{{\theta}}, D_{\rm train}^{i}, D_{\rm valid}^{i}) represents the cross-validation method; D_{\rm train}^{i} stands for the training data; D_{\rm valid}^{i} is the validation data; {\theta}_{l} and {\theta}_{u} denote the upper and lower boundaries of the parameters {\theta} , respectively.
To evaluate the effectiveness of the parameter configuration scheme, the predictive performance of the MLSSVM model is evaluated by the mean square error MSE = \dfrac{1}{l}\displaystyle\sum\nolimits_{i = 1}^{l}(y_{i}-\widehat{y}_{i}) , where y_{i} and \widehat{y}_{i} represent the real output and the predicted output, respectively.
1) Parameter Determination for MLSSVM-based Model Using the Standard Data: The purpose of optimization considered here is to find a MLSSVM regression model with satisfactory generalization. In this experiment, the energy efficiency dataset [36] is employed which is downloaded from UCI machine learning repository. 500 data points are selected to train this model and 200 data points are used as testing data. The MLSSVM model has three parameters to be configured and the energy efficiency dataset contains two output responses. Then, the optimization problem with three decision variables and two objective variables is considered according to (25) and (26).
The optimal parameter configuration corresponds to the minimum of the mean square error between the predicted and real values. The i\mathrm{th} parameter configuration is expressed as MSE({\theta}_{i}) = MSE_{1}({\theta}_{i})+MSE_{2}({\theta}_{i}) , where MSE_{1}({\theta}_{i}) indicates the mean square error between the predicted values and the real values for the objective 1 and MSE_{2}({\theta}_{i}) represents the mean square error between the predicted values and the real values for objective 2. \min(MSE({\theta}_{i})) corresponds to the MLSSVM model with the best prediction performance. Since the order of magnitude of the mean square error is different, MSE_{1}({\theta}_{i}) and MSE_{2}({\theta}_{i}) need to be normalized. In this experiment, 10 independent experiments are conducted and the maximum number of the fitness evaluations is set to 300 and 500. The statistical results of the experiment are shown in Table II, where MSE1, MSE2 and MSE represent the mean (the corresponding standard deviation) of MSE_{1}({\theta}_{i}) , MSE_{2}({\theta}_{i}) and MSE({\theta}_{i}) , i = 1, 2, \dots, 10 . The parameter setting of the PAL-SAPSO is the same as that in the experiments on benchmark problems. For the MLSSVM model, the parameter ranges are set to \lambda\in [2^{-15}, 2^{8}] , \gamma\in [2^{-10}, 2^{4}] and \delta\in [2^{-15}, 2^{3}] .
Table
II.
Statistic Results for Parameter Determination of MLSSVM-based Model
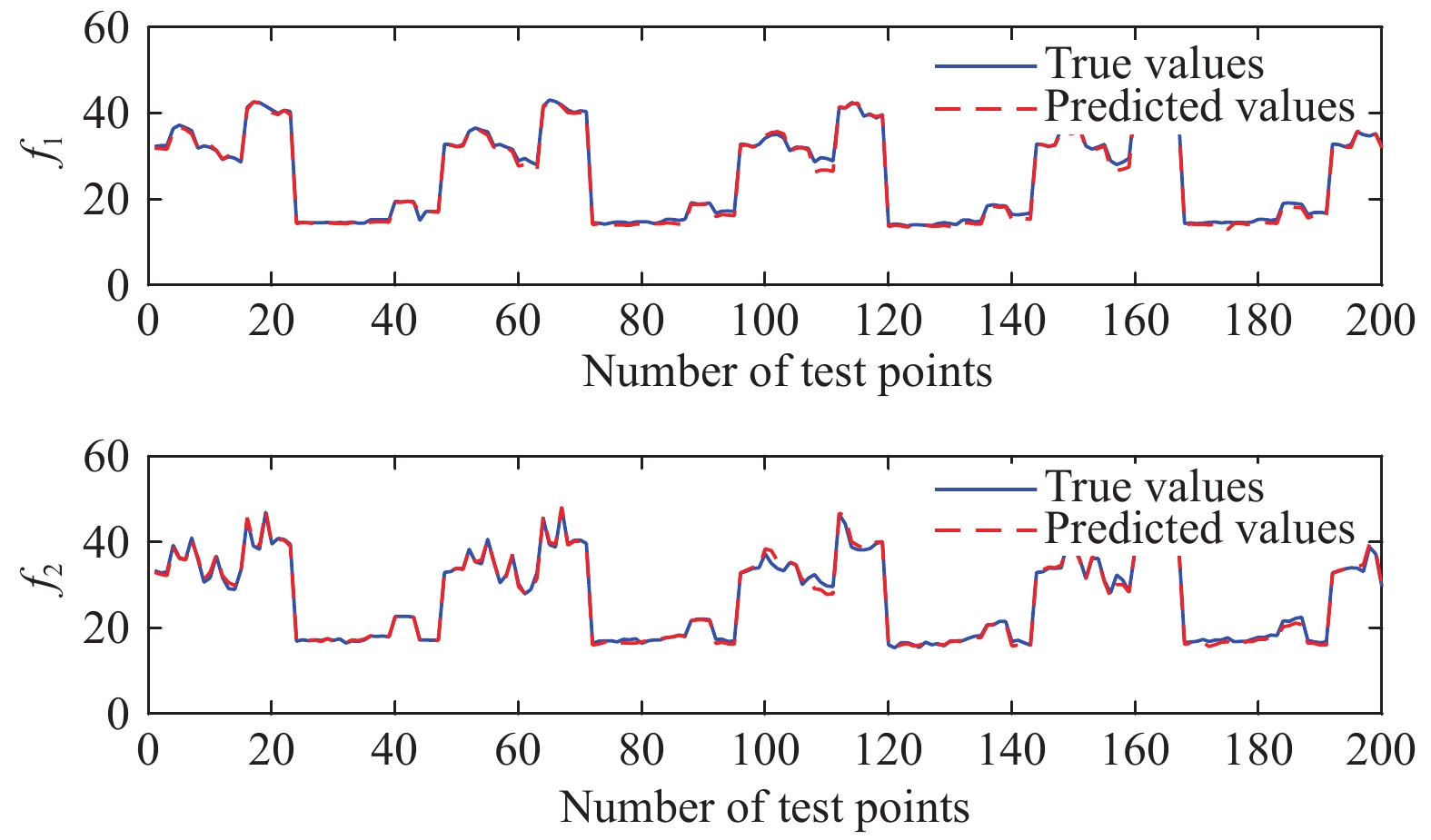
With respect to the results obtained with the 300 fitness evaluations in Table II, it can be clearly seen that the values of MSE1 obtained by PAL-SAPSO are the smallest for objective 1; the values of MSE2 obtained by PAL-SAPSO are similar to the ones obtained by MOPSO and SMPSO for objective 2; the values of MSE obtained by PAL-SAPSO are the smallest. These facts indicate that the convergence and the stability of PAL-SAPSO are better than MOPSO, dMOPSO and SMPSO, and the performance of MLSSVM model obtained by PAL-SAPSO is the best. As for the results obtained with the 500 fitness evaluations, it can be seen that MOPSO, dMOPSO and SMPSO can effectively reduce the mean square error by increasing the number of fitness evaluations. A similar parameter configuration scheme is obtained by PAL-SAPSO with the 300 and 500 fitness evaluations. It appears that PAL-SAPSO can find the reasonable parameter configuration more effectively with the same number of fitness evaluations compared with MOPSO, dMOPSO and SMPSO. In order to illustrate the effectiveness of PAL-SAPSO more intuitively, the predicted results with the best parameter configuration scheme are shown in Fig. 3.
2) Parameter Determination for MLSSVM Model Using Industrial Data: In this experiment, the goal of optimization is to accurately predict real variation for the gas holder level with the MLSSVM model. The blast furnace gas (BFG) system [37] consists of BFG converters for gas generation, pipeline networks for gas transportation, gas users for consumption and gas holder for temporary storage. As the only storage equipment and buffer unit of the pipe network, the gas holder level reflects the balance state of the generation and consumption of the gas in the pipe network. In order to simplify the problem, the inner relationships between the gas generation users and the gas consumption users are not considered. Then, the total gas generation flow, the total gas consumption flow, the 1# gas holder level at the first moment and the 2# gas holder level at the first moment are considered as the inputs. The 1# gas holder level and the 2# gas holder level are seen as the outputs. Based on samples from the input and output above, the MLSSVM model has three parameters need to be determined. Therefore, the optimization problem with three decision variables and two objective variables is considered according to (25) and (26).
To establish the MLSSVM model, the gas flow data over 4 weeks are randomly selected. The sampling interval of the time series data is one minute. The number of the training samples is set to 5040 (two weeks data). The process of predicting is triggered every 5 points (5 minutes) to predict the future 30-min gas flow. It takes about 127.50 s to carry out an exact fitness function evaluation (10-fold cross-validation). In order to achieve the optimization of the MLSSVM model within 12 hours, the maximum number of fitness evaluations is set to 300. Furthermore, in order to predict the real variation of the gas holder level, the dynamic optimization of the MLSSVM model (DMLSSVM) is carried out every 12 hours. The training samples of the DMLSSVM model are updated every 12 hours. For verifying the feasibility of the DMLSSVM model, a static MLSSVM model (SMLSSVM) is developed. The training samples of the SMLSSVM model are from the gas flow data of the first two weeks. The parameter setting of the PAL-SAPSO is the same as that in the experiments on benchmark problems. The parameter ranges of the MLSSVM model are set to \lambda\in [2^{-15}, 2^{8}] , \gamma\in [2^{-10}, 2^{4}] and \delta\in [2^{-15}, 2^{3}]
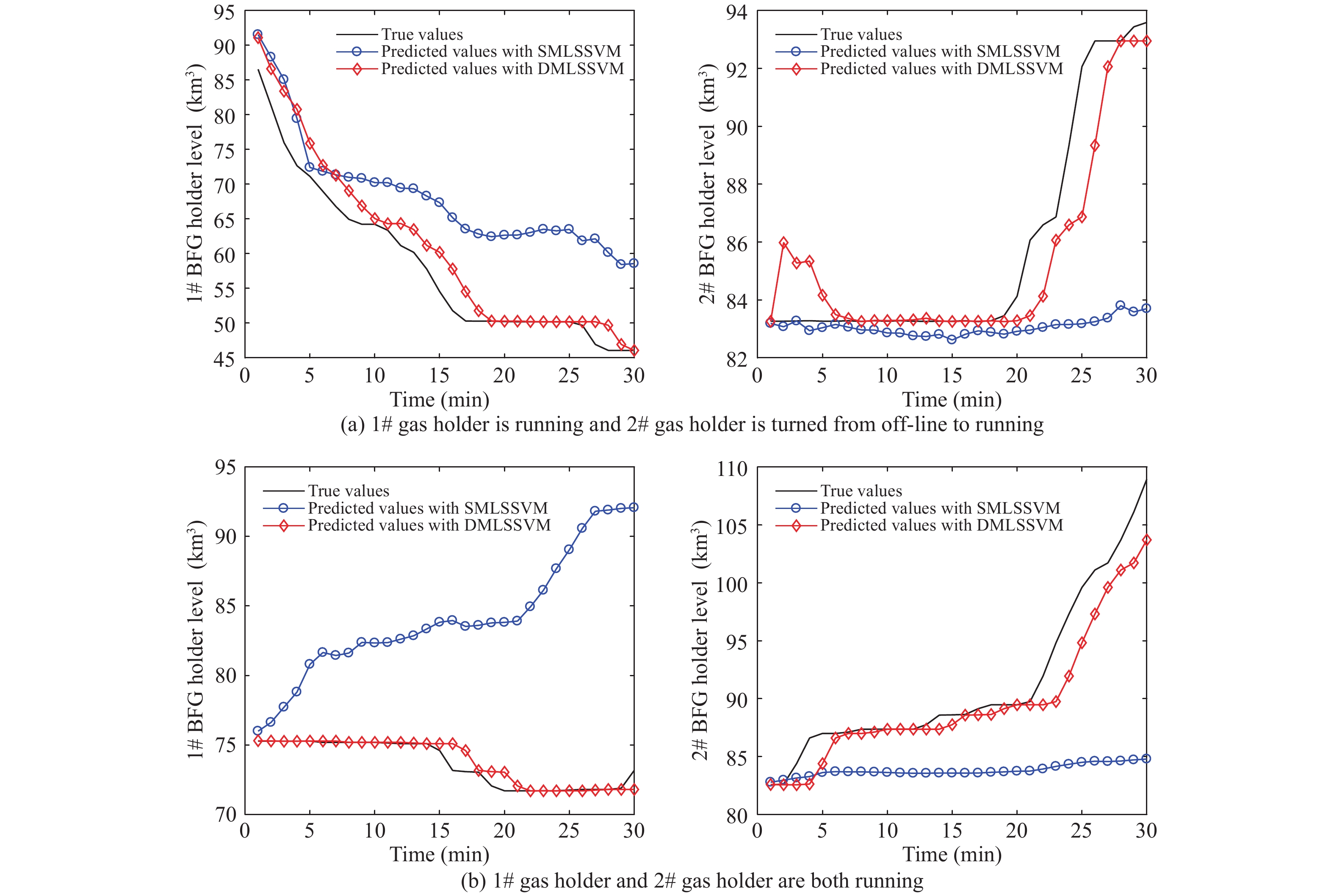
For verifying the effectiveness of PAL-SAPSO in the optimization problem on MLSSVM model driven by the gas flow data, two types of working conditions are selected as the representatives in this study: 1) 1# gas holder is running, 2# gas holder is turned from off-line to running; 2) 1# gas holder and 2# gas holder are both running. The corresponding simulation results are shown in Fig. 4 respectively. As shown in Fig. 4, DMLSSVM can effectively predict the change trend of 1# gas holder level and 2# gas holder level for two types of working conditions. Although it roughly predicts the changing trend of 1# gas holder level in the first type of working conditions, SMLSSVM fails to estimate the tendency of 2# gas holder level and the 1# and 2# gas holder level in the last type of working condition. In all, based on the dynamic optimization with PAL-SAPSO, the real changing trend of the gas holder level can be accurately forecasted with the parameter optimized MLSSVM model.
Figure
4.
The simulation results obtained by algorithms on two types of working condition.
In this paper, a surrogate-assisted PSO with Pareto active learning is proposed to solve the multi-objective optimization problem with high computational cost. In this algorithm, PSO is regarded as a sampler to generate candidate solutions. The performance of the PSO optimizer is improved by pre-selecting results from the candidate solutions with the improved \varepsilon -PAL. To improve the performance of the sampler, a hybrid mutation sampling method based on simulated evolution is proposed, which takes into account fast convergence and the diversity of distribution. In addition, a new method for determining the parameter ε is suggested where the number of the active sampling is used as an evaluation index of classification cost. The effectiveness of the proposed algorithm is verified by eight standard test problems. Compared with MOPSO, dMOPSO and SMPSO, the experimental results demonstrated that the Pareto optimal solutions obtained by the proposed algorithm has better convergence and distribution. In addition, comparative studies are also conducted on two MLSSVM model optimization problems, in which the advantage of determining effective parameter configuration schemes for the proposed method is verified on not only the standard data but also the real-world applications.
A few parameters (e.g., the value of the classification cost T ) in the proposed algorithm must be predefined by the user, which do affect the performance of algorithms and must be defined properly. Therefore, more attention will be paid to address this issue. In addition, the performance of the proposed algorithm on expensive optimization problems with high dimension also remains to be verified.
G. R. Zavala, A. J. Nebro, F. Luna, and C. A. C. Coello, " A survey of multi-objective metaheuristics applied to structural optimization,” Struct. Multidiscipl. Optim., vol. 49, no. 4, pp. 537–558, Apr. 2014. doi: 10.1007/s00158-013-0996-4
[2]
M. Park, M. Nassar, and H. Vikalo, " Bayesian active learning for drug combinations,” IEEE Trans. Biomed. Eng., vol. 60, no. 11, pp. 3248–3255, Nov. 2013. doi: 10.1109/TBME.2013.2272322
[3]
D. Ronco, C. Comis, R. Ponza, and E. Benini, " Aerodynamic shape optimization of aircraft components using an advanced multi-objective evolutionary approach,” Comput. Methods Appl. Mech. Eng., vol. 285, pp. 255–290, Mar. 2015. doi: 10.1016/j.cma.2014.10.024
[4]
J. Snoek, I. Larochelle, and R. P. Adans., " Practical Bayesian optimization of machine learning algorithms,” in Proc. 25th Int. Conf. NIPS, Lake Tahoe, Nevada, 2012, pp. 2951–2959.
[5]
H. D. Wang, Y. C. Jin, and J. O. Jansen, " Data-driven surrogate-assisted multiobjective evolutionary optimization of a trauma system,” IEEE Trans. E Comput., vol. 20, no. 6, pp. 939–952, Dec. 2016. doi: 10.1109/TEVC.2016.2555315
[6]
Q. L. Zhu, Q. Z. Lin, W. N. Chen, K. C. Wong, C. A. Coello Coello, J. Li, J. Chen, and J. Zhang, " An external archive-guided multiobjective particle swarm optimization algorithm,” IEEE Trans. Cybern., vol. 47, no. 9, pp. 2794–2808, Sep. 2017. doi: 10.1109/TCYB.2017.2710133
[7]
Q. Z. Lin, S. B. Liu, Q. L. Zhu, C. Y. Tang, R. Z. Song, J. Y. Chen, C. A. Coello Coello, K. C. Wong, and J. Zhang, " Particle swarm optimization with a balanceable fitness estimation for many-objective optimization problems,” IEEE Trans. E Comput., vol. 22, no. 1, pp. 32–46, Feb. 2018. doi: 10.1109/TEVC.2016.2631279
[8]
W. J. Kong, T. Y. Chai, J. L. Ding, and Z. W. Wu, " A real-time multiobjective electric energy allocation optimization approach for the smelting process of magnesia,” Acta Autom. Sinica, vol. 40, no. 1, pp. 51–61, Jan. 2014.
[9]
W. Hu and G. G. Yen, " Adaptive multiobjective particle swarm optimization based on parallel cell coordinate system,” IEEE Trans. E Comput., vol. 19, no. 1, pp. 1–18, Feb. 2015. doi: 10.1109/TEVC.2013.2296151
[10]
A. Trivedi, D. Srinivasan, K. Sanyal, and A. Ghosh, " A survey of multiobjective evolutionary algorithms based on decomposition,” IEEE Trans. E Comput., vol. 21, no. 3, pp. 440–462, Jun. 2017.
[11]
Q. Kang, S. W. Feng, M. C. Zhou, A. C. Ammari, and K. Sedraoui, " Optimal load scheduling of plug-in hybrid electric vehicles via weight-aggregation multi-objective evolutionary algorithms,” IEEE Trans. Intell. Transp. Syst., vol. 18, no. 9, pp. 2557–2568, Sep. 2017. doi: 10.1109/TITS.2016.2638898
[12]
R. T. Haftka, D. Villanueva, and A. Chaudhuri, " Parallel surrogate-assisted global optimization with expensive functions — a survey,” Struct. Multidiscip. Optim., vol. 54, no. 1, pp. 1–11, Apr. 2016. doi: 10.1007/s00158-016-1491-5
[13]
M. Tabatabaei, J. Hakanen, M. Hartikainen, K. Miettinen, and K. Sindhya, " A survey on handling computationally expensive multiobjective optimization problems using surrogates: non-nature inspired methods,” Struct. Multidiscip. Optim., vol. 52, no. 1, pp. 1–25, Jul. 2015. doi: 10.1007/s00158-015-1226-z
[14]
Y. Jin, " Surrogate-assisted evolutionary computation: recent advances and future challenges,” Swarm E Comput., vol. 1, no. 2, pp. 61–70, Jun. 2011. doi: 10.1016/j.swevo.2011.05.001
[15]
C. Ma and L. Y. Qu, " Multiobjective optimization of switched reluctance motors based on design of experiments and particle swarm optimization,” IEEE Trans. Energy Convers., vol. 30, no. 3, pp. 1144–1153, Sep. 2015. doi: 10.1109/TEC.2015.2411677
[16]
X. R. Ye, H. Chen, H. M. Liang, X. J. Chen., and J. X. You, " Multi-objective optimization design for electromagnetic devices with permanent magnet based on approximation model and distributed cooperative particle swarm optimization algorithm,” IEEE Trans. Magn., vol. 54, no. 3, pp. 1–5, Mar. 2018.
[17]
H. X. Jie, Y. Z. Wu, J. J. Zhao, J. W. Ding, and L. liang, " An efficient multi-objective PSO algorithm assisted by Kriging metamodel for expensive black-box problems,” J. Glob. Optim., vol. 67, no. 1–2, pp. 399–423, Jan. 2017.
[18]
F. Bittner and I. Hahn, " Kriging-assisted multi-objective particle swarm optimization of permanent magnet synchronous machine for hybrid and electric cars,” in Proc. IEEE Int. Elect. Mach. Drives Conf., Chicago, IL, USA, 2013, pp. 15–22.
[19]
H. D. Wang, Y. C. Jin, and J. O. Jansen, " Committee-based active learning for surrogate-assisted particle swarm optimization of expensive problems,” IEEE Trans. Cybern., vol. 47, no. 9, pp. 2664–2677, Jun. 2017. doi: 10.1109/TCYB.2017.2710978
[20]
M. Parno, T. Hemker, and K. R. Fowler, " Applicability of surrogates to improve efficiency of particle swarm optimization for simulation-based problems,” Eng. Optim., vol. 44, no. 5, pp. 521–535, Sep. 2012. doi: 10.1080/0305215X.2011.598521
[21]
Z. C. Cao, C. R. Lin, M. C. Zhou, and R. Huang, " Scheduling semiconductor testing facility by using cuckoo search algorithm with reinforcement learning and surrogate modeling,” IEEE Trans. Autom. Sci. Eng.. 2018. DOI: 10.1109/TASE.2018.2862380.
[22]
X. Y. Sun, D. W. Gong, Y. C. Jin, and S. S. Chen, " A new surrogate-assisted interactive genetic algorithm with weighted semisupervised learning,” IEEE Trans. Cybern., vol. 43, no. 2, pp. 685–698, Apr. 2013. doi: 10.1109/TSMCB.2012.2214382
[23]
P. Campigotto, A. Passerini, and R. Battiti, " Active learning of Pareto fronts,” IEEE Trans. Neural Netw. Learn. Syst., vol. 25, no. 3, pp. 506–519, Mar. 2014. doi: 10.1109/TNNLS.2013.2275918
[24]
D. Reker, P. Schneider, and G. Schneider, " Multi-objective active machine learning rapidly improves structure-activity models and reveals new protein-protein interaction inhibitors,” Chem. Sci., vol. 7, pp. 3919–3727, Mar. 2016. doi: 10.1039/C5SC04272K
[25]
M. Zuluaga, G. Sergent, A. Krause, and M. Püschel, " Active learning for multi-objective optimization,” in Proc. Int. Conf. Mach. Learning, Atlanta, GA, USA, 2013, pp. 462–470.
[26]
M. Zuluaga, A. Krause, and M. Puschel, " ε-PAL: an active learning approach to the multi-objective optimization problem,” J. Mach. Learn. Res., vol. 17, no. 1, pp. 3619–3650, Aug. 2016.
[27]
D. F. Wang, and L. Meng, " Performance analysis and parameter selection of PSO algorithms,” Acta Autom. Sinica, vol. 42, no. 10, pp. 1552–1561, Jan. 2016.
[28]
C. E. Rasmussen and H. Nickisch, " Gaussian processes for machine learning (GPML) toolbox,” J. Mach. Learn. Res., vol. 11, pp. 3011–3015, Nov. 2010.
[29]
S. Z. Martínez and C. C. Coello, " A multi-objective particle swarm optimizer based on decomposition,” in Proc. Genetic Evol. Comput., Dublin, Ireland, 2011, pp. 69–76.
[30]
A. J. Nebro, J. J. Durillo, J. Garcia-Nieto, C. A. coello coeelo, F. Luna, and R. Aeba, " SMPSO: a new PSO-based metaheuristic for multi-objective optimization,” in Proc. IEEE Symp. Comput. Intell. Miulticriteria Decision Making, Nashville, TN, USA, 2009, pp. 66–73.
[31]
Y. Tian, R. Cheng, X. Y. Zhang, and Y. C. Jin, " PlatEMO: A MATLAB platform for evolutionary multi-objective optimization,” IEEE Comput. Intell. Mag., vol. 12, pp. 73–87, Nov. 2017.
[32]
Q. F. Zhang, A. M. Zhou, S. Z. Zhao, P. Suganthan, W. D. Liu, and S. Tiwari,, " Multiobjective optimization test instances for the CEC-2009 special session and competition,” Nanyang Technol. Univ., Singapore, Tech. Rep., 2008. http://www.ntu.edu.sg/home/epnsugan/.
[33]
Q. F. Zhang, A. M. Zhou, and Y. C. Jin, " RM-MEDA: a regularity model-based multiobjective estimation of distribution algorithm,” IEEE Trans. E Comput., vol. 21, no. 1, pp. 41–63, Feb. 2008.
[34]
S. Xu, X. An, X. D. Qiao, L. J. Zhu, and L. Li, " Multi-output least-squares support vector regression machines,” Pattern Recognit. Lett., vol. 34, no. 9, pp. 1078–1084, Jul. 2013. doi: 10.1016/j.patrec.2013.01.015
[35]
J. Bergstra and Y. Bengio, " Random search for hyper-parameter optimization,” J. Mach. Learn. Res., vol. 13, no. 1, pp. 281–305, Feb. 2012.
[36]
S. Chen, " Multi-output regression using a locally regularised orthogonal least square algorithm,” IEEE Proc. Vision Image Signal Process., vol. 149, no. 4, pp. 185–195, Aug. 2002. doi: 10.1049/ip-vis:20020401
[37]
Z. Y. Han, Y. Liu, J. Zhao, and W. Wang, " Real time prediction for converter gas tank levels based on multi-output least square support vector regressor,” Control Eng. Pract., vol. 20, no. 12, pp. 1400–1409, Dec. 2012. doi: 10.1016/j.conengprac.2012.08.006
Zhiming Lv, Linqing Wang, Zhongyang Han, Jun Zhao and Wei Wang, "Surrogate-Assisted Particle Swarm Optimization Algorithm With Pareto Active Learning for Expensive Multi-Objective Optimization," IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 838-849, May 2019. doi: 10.1109/JAS.2019.1911450
Zhiming Lv, Linqing Wang, Zhongyang Han, Jun Zhao and Wei Wang, "Surrogate-Assisted Particle Swarm Optimization Algorithm With Pareto Active Learning for Expensive Multi-Objective Optimization," IEEE/CAA J. Autom. Sinica, vol. 6, no. 3, pp. 838-849, May 2019. doi: 10.1109/JAS.2019.1911450
Input:NP (population size), {v} (velocity), {x} (position), A (external archive), D_{t} (knowledge base with N_{t} samples at t generation), N_{\max} (maximum number of the fitness evaluations).
1: Initialize NP , {{v}} , {{x}} , A , D_{t} and set N_{t}=NP .
2: while N_{t} \le N_{\max} do
3: Select the personal best {{p}}_{i}(t) and the global best {{p}}_{g}(t) .
4: Update {{v}}(t) and {{x}}(t) using (3) and (4), and calculate the corresponding fitness {{f}}({{x}}) .
5: Update A (Using Algorithm 5).
6: Update D_{t} with \{{{x}}, {{f}}({{x}})\} .
7: Construct the surrogate model for each objective using (5) and (6).
8: Get the candidate solution set (Using Algorithm 3).
9: Get the \varepsilon -accurate Pareto optimal solution set (Using Algorithm 4).
10: Update A (Using Algorithm 5).
11: Update D_{t} .
12: Count the number of the fitness evaluations N_{t} .
3: Update {{v}}^{\prime}(k) and {{x}}^{\prime}(k) using (7) and (8).
4: Evaluate the fitness based on (5).
5: Determine the particles which are beyond Pareto front using (9) and (10), and obtain new particles {{x}}^{\prime \prime}(k) based on (11).
6: Determine the particles which locate the sparse part of the Pareto front using (12) and (13), and obtain the new particles {{x}}^{\prime \prime \prime}(k) based on (14).
7: Get the set of the candidate solution X_{\rm pss} according to (15).
8: Update \widehat{A}(k) with \{X_{\rm pss}, \widehat{{{y}}}(X_{\rm pss})\} .
9: Select the personal best \widehat{{{p}}}_{i}(k) and the global best \widehat{{{p}}}_{g}(k) .





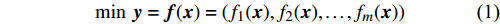

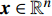
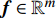
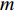
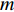
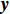
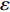
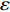
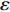
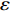
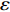
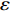
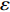
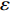
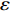
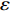
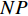
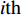
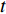
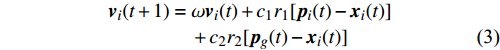
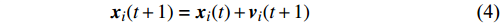
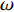
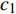
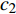
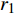
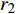
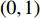
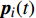
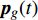
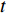
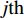
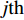
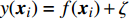
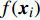
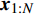
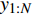

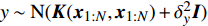
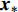
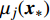
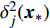
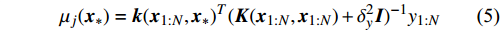
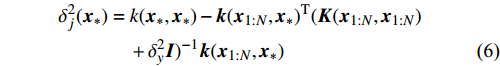
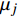
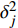
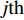
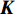
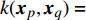
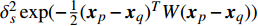
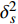
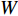
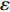
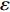
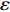
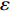
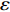
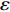
 DownLoad:
DownLoad:
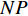

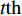
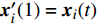
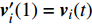
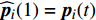
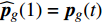
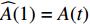
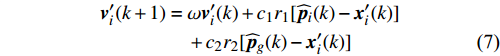
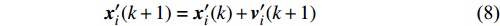
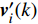
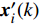
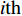
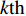
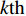
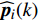
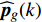
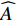
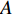
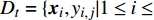
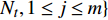
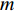
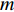
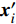
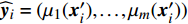
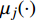
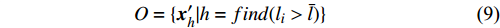
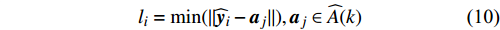

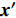
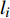
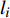
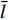
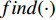
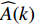
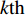
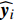
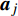
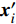
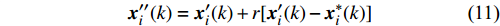
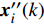
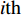
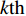
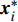
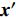
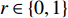
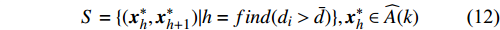
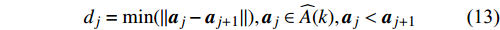
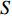
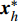
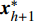
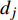
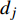
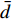
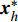
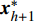
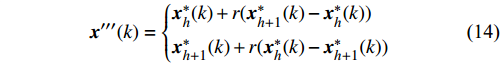
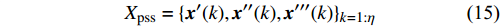
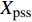
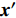

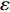
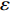
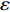
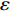
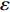
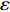
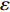
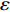
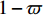
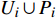
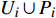
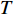
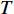
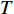
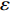
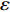
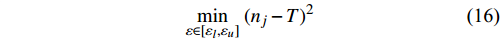
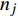
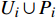
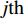
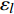
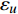
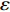
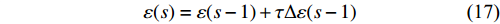
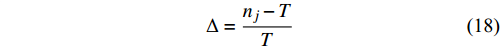
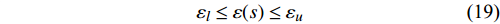
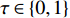
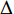
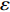
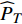
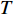
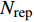
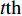
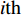
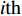
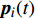
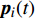
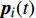
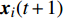
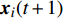
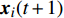
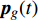
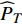
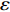
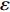
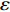
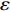
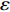
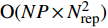
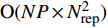
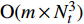
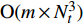
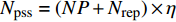
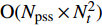
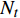
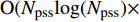
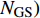
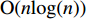
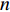
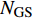

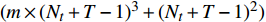
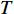
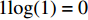
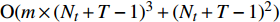
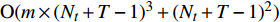
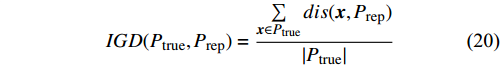
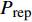
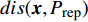
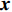
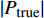
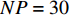
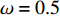

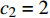
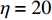
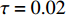
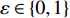

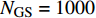
 DownLoad:
DownLoad:
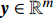
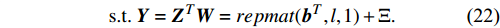
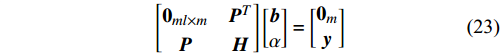
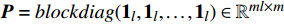
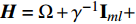
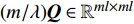
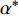
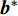
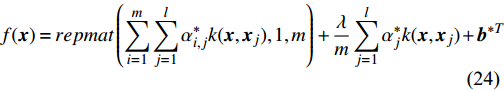
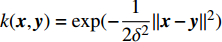
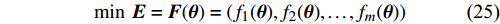
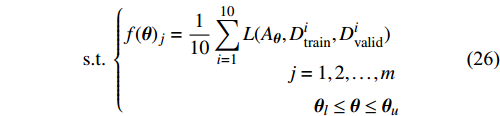
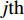
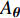
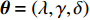
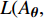
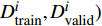
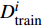
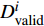
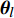
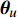
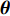
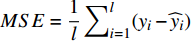
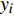
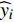
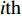
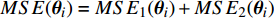
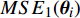
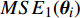
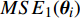
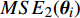
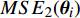
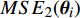
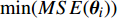
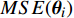
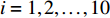
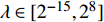
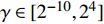
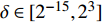
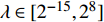
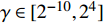
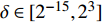
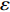
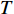






 DownLoad:
DownLoad:


