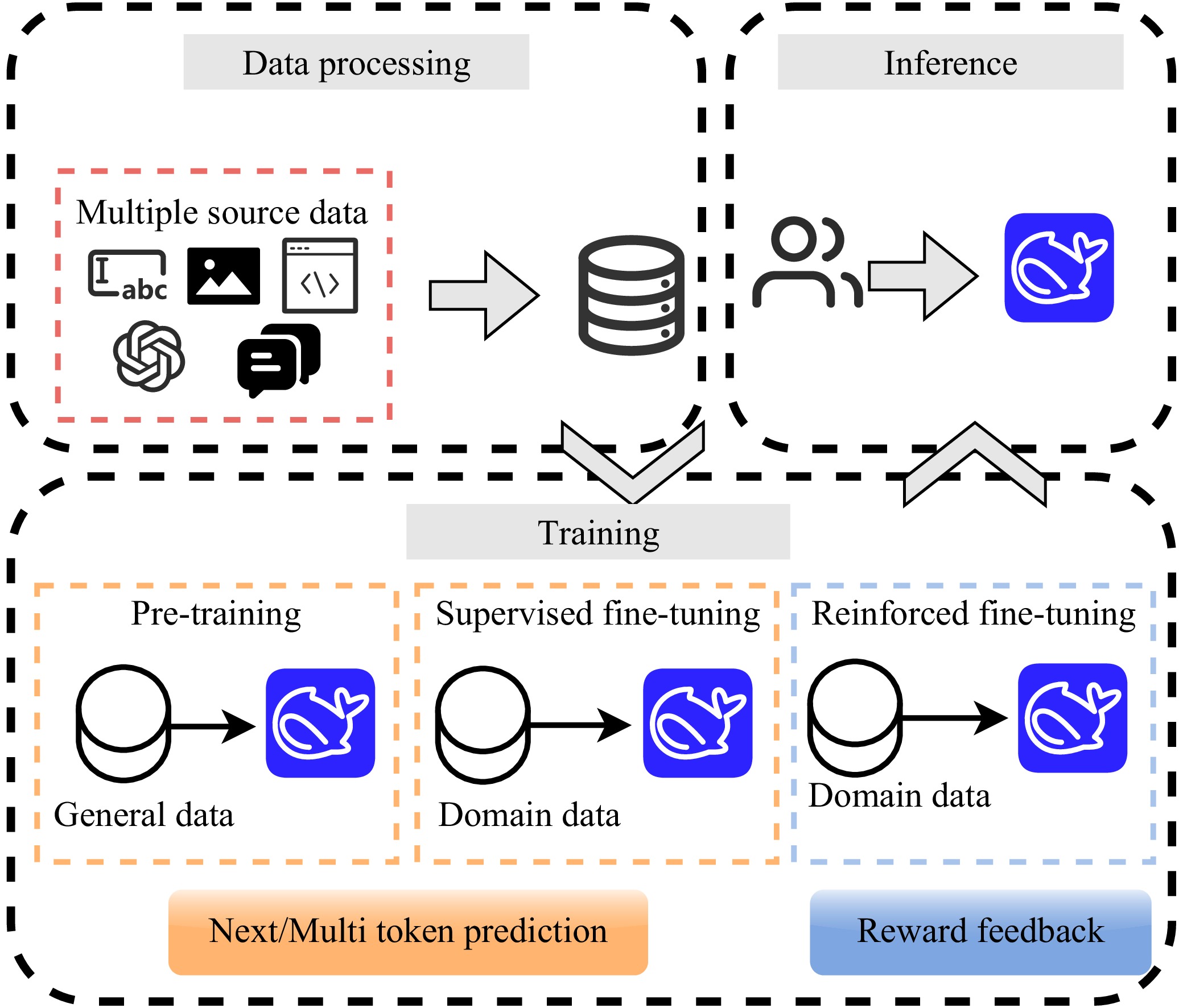
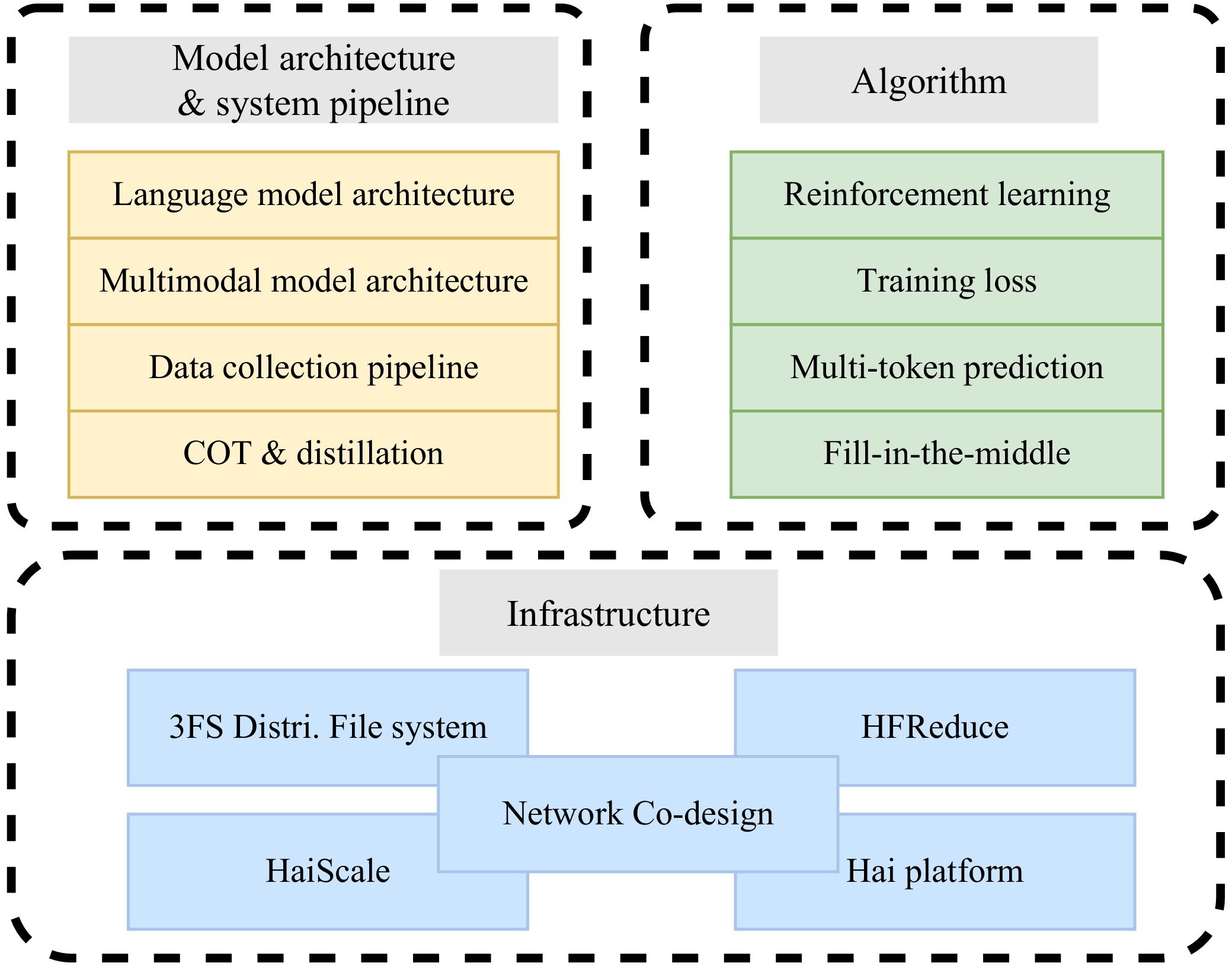
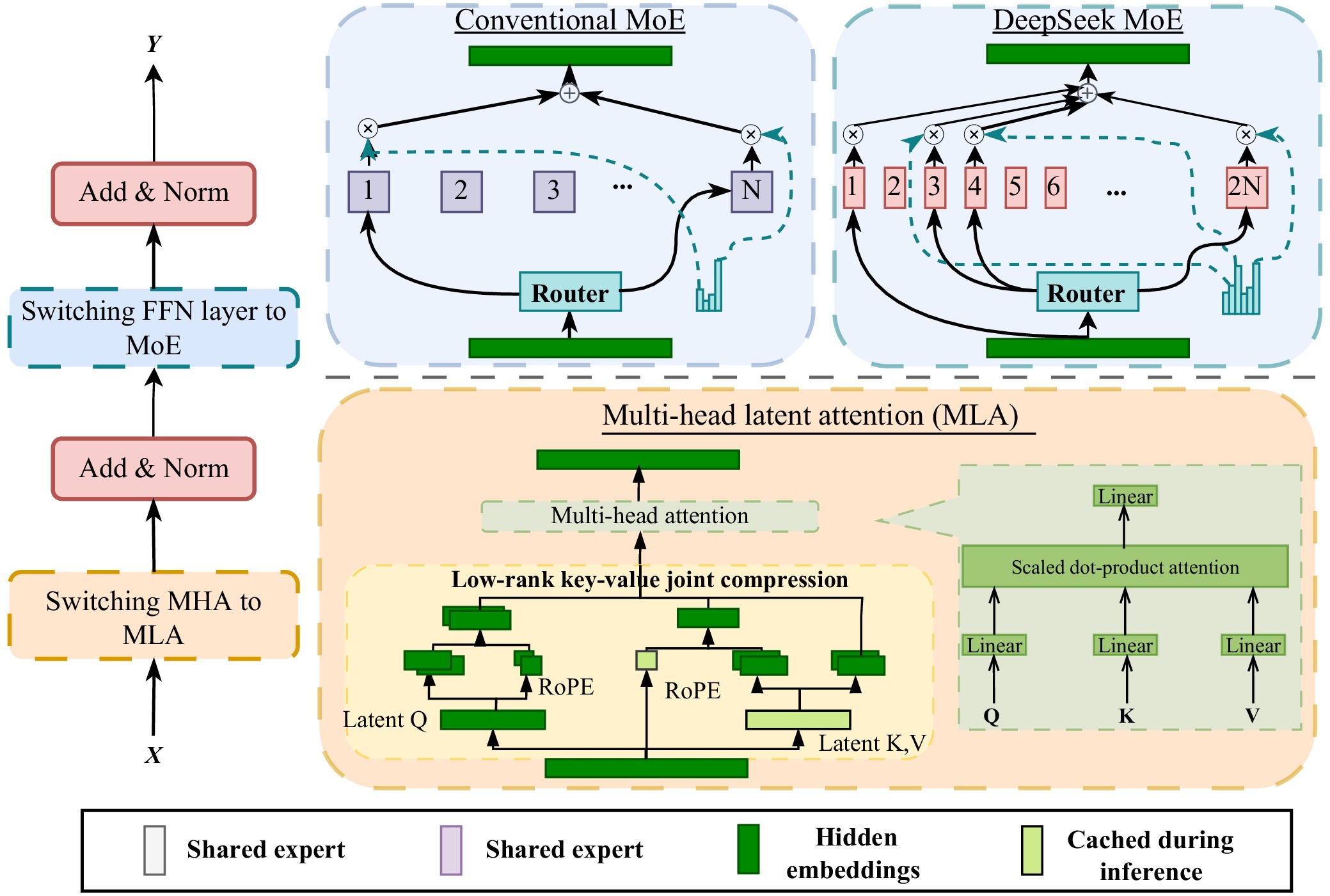
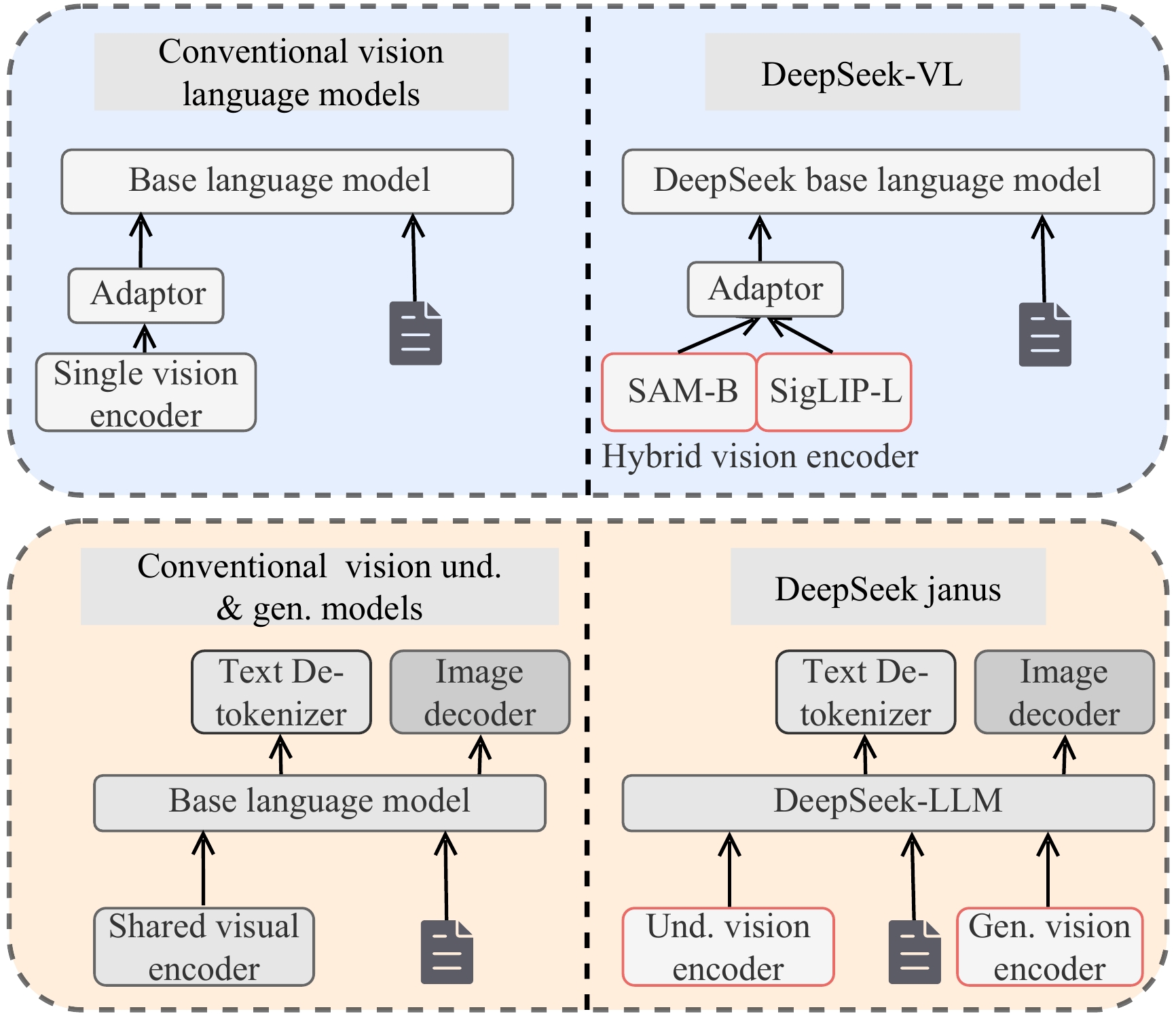
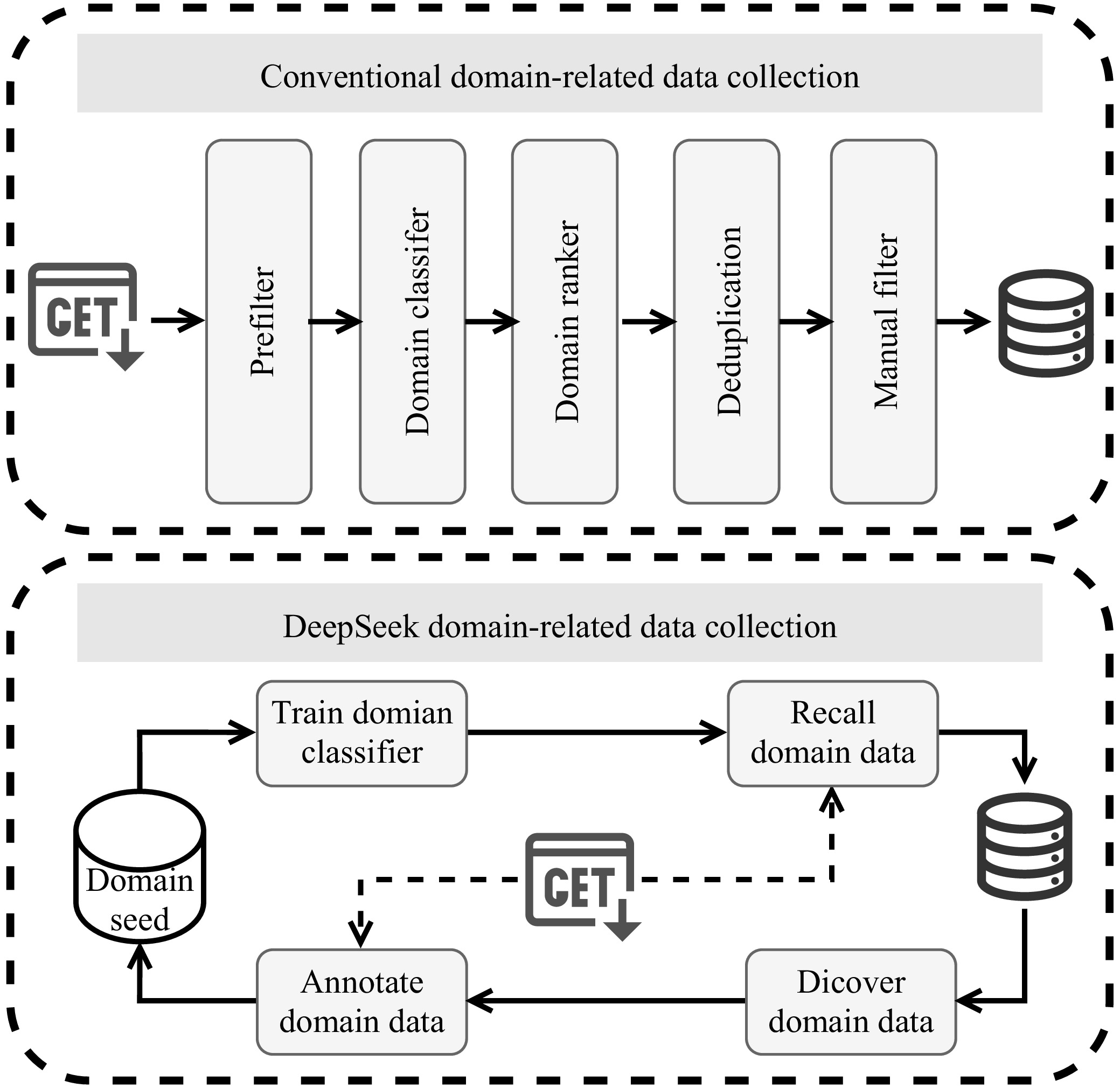
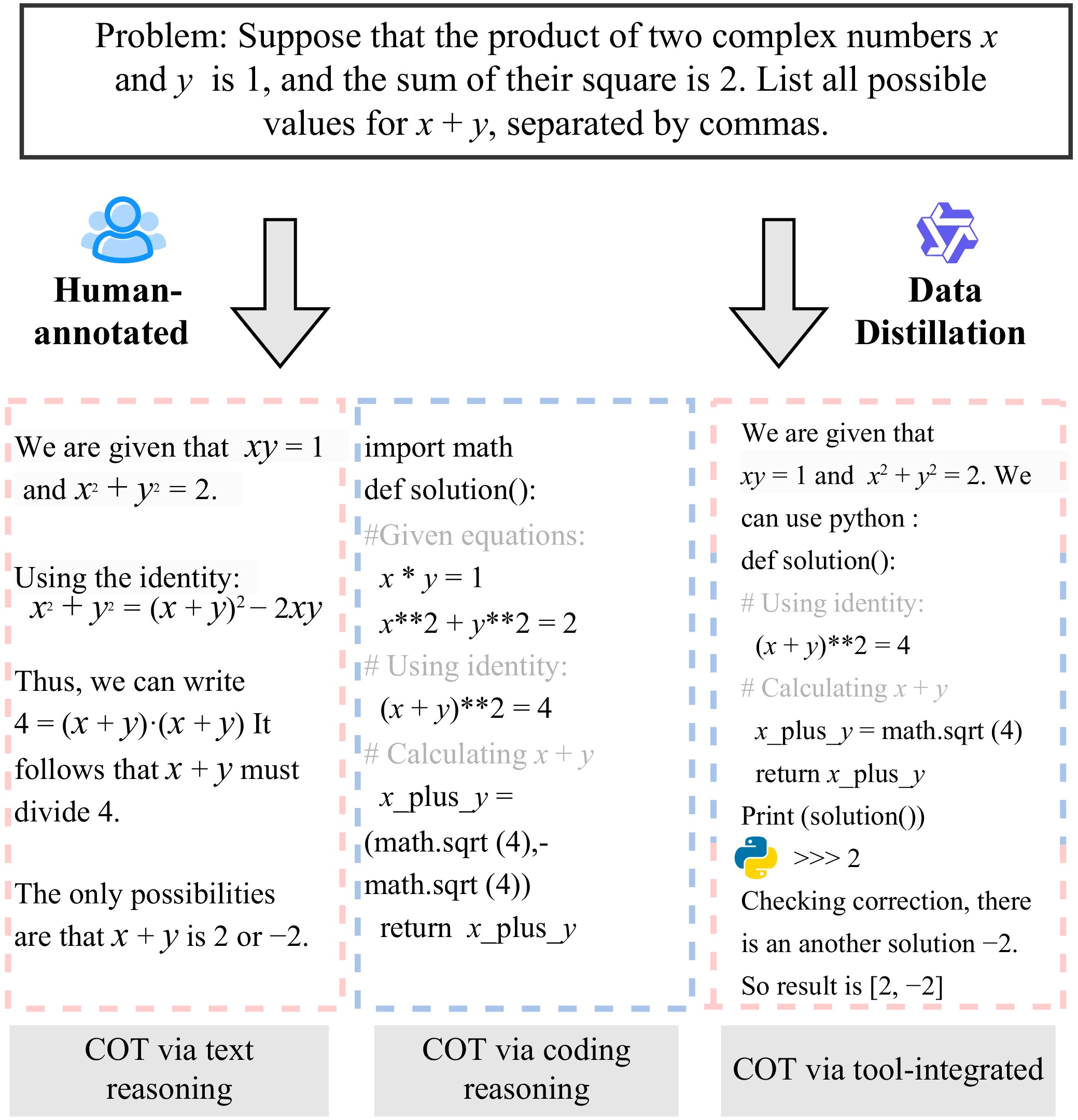
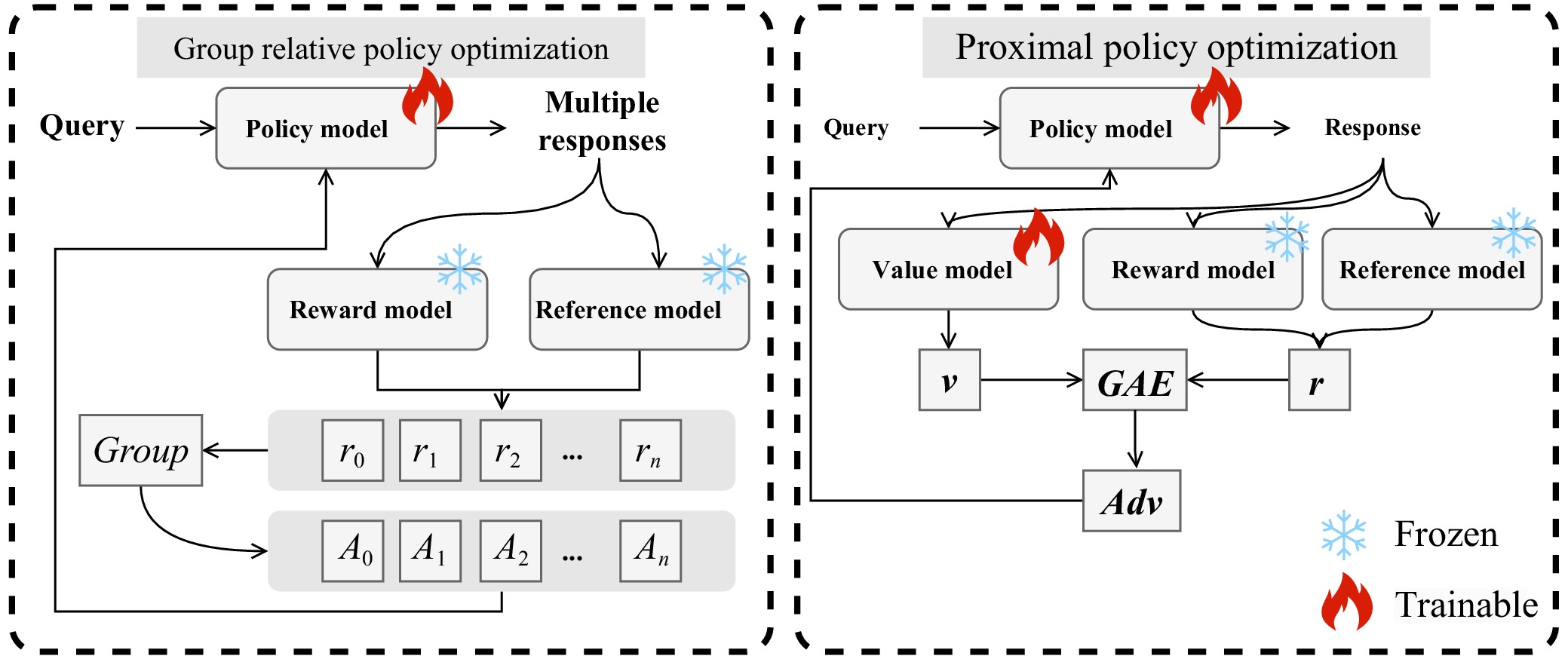
| [1] |
X. Wang, G. Chen, G. Qian, P. Gao, X.-Y. Wei, Y. Wang, Y. Tian, and W. Gao, “Large-scale multi-modal pre-trained models: A comprehensive survey,” Mach. Intell. Res., vol. 20, no. 4, pp. 447–482, Jun. 2023. doi: 10.1007/s11633-022-1410-8 |
| [2] |
Y.-F. Li, H. Wang, and M. Sun, “ChatGPT-like large-scale foundation models for prognostics and health management: A survey and roadmaps,” Reliab. Eng. Syst. Saf., vol. 243, p. 109850, Mar. 2024. doi: 10.1016/j.ress.2023.109850 |
| [3] |
Y. Yao, J. Duan, K. Xu, Y. Cai, Z. Sun, and Y. Zhang, “A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly,” High-Confid. Comput., vol. 4, no. 2, p. 100211, Jun. 2024. doi: 10.1016/j.hcc.2024.100211 |
| [4] |
F.-A. Croitoru, V. Hondru, R. T. Ionescu, and M. Shah, “Diffusion models in vision: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 9, pp. 10850–10869, Mar. 2023. doi: 10.1109/TPAMI.2023.3261988 |
| [5] |
S. Latif, M. Shoukat, F. Shamshad, M. Usama, Y. Ren, H. Cuayáhuitl, W. Wang, X. Zhang, R. Togneri, E. Cambria, and B. W. Schuller, “Sparks of large audio models: A survey and outlook,” arXiv preprint arXiv: 2308.12792, 2023.
|
| [6] |
B. Zhang, K. Li, Z. Cheng, Z. Hu, Y. Yuan, G. Chen, S. Leng, Y. Jiang, H. Zhang, X. Li, P. Jin, W. Zhang, F. Wang, L. Bing, and D. Zhao, “VideoLLaMA 3: Frontier multimodal foundation models for image and video understanding,” arXiv preprint arXiv: 2501.13106, 2025.
|
| [7] |
Z. Qian, S. Wang, M. Mihajlovic, A. Geiger, and S. Tang, “3DGS-Avatar: Animatable avatars via deformable 3D Gaussian splatting,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 5020–5030.
|
| [8] |
K. S. Kalyan, “A survey of GPT-3 family large language models including ChatGPT and GPT-4,” Nat. Language Process. J., vol. 6, p. 100048, Mar. 2024. doi: 10.1016/j.nlp.2023.100048 |
| [9] |
S. A. A. Safavi-Naini, S. Ali, O. Shahab, Z. Shahhoseini, T. Savage, S. Raffee, J. S. Samaan, R. Al Shabeeb, F. Ladak, J. O. Yang, J. Echavarria, S. Babar, A. Shaukat, S. Margolis, N. P. Tatonetti, G. Nadkarni, B. El Kurdi, and A. Soroush, “Vision-language and large language model performance in gastroenterology: GPT, Claude, Llama, Phi, Mistral, Gemma, and Quantized Models,” arXiv preprint arXiv: 2409.00084, 2024.
|
| [10] |
X. Sun, Y. Chen, Y. Huang, R. Xie, J. Zhu, K. Zhang, S. Li, Z. Yang, J. Han, X. Shu, J. Bu, Z. Chen, X. Huang, F. Lian, S. Yang, J. Yan, Y. Zeng, X. Ren, C. Yu, L. Wu, Y. Mao, J. Xia, T. Yang, S. Zheng, K. Wu, D. Jiao, J. Xue, X. Zhang, D. Wu, K. Liu, D. Wu, G. Xu, S. Chen, S. Chen, X. Feng, Y. Hong, J. Zheng, C. Xu, Z. Li, X. Kuang, J. Hu, Y. Chen, Y. Deng, G. Li, A. Liu, C. Zhang, S. Hu, Z. Zhao, Z. Wu, Y. Ding, W. Wang, H. Liu, R. Wang, H. Fei, P. Yu, Z. Zhao, X. Cao, H. Wang, F. Xiang, M. Huang, Z. Xiong, B. Hu, X. Hou, L. Jiang, J. Ma, J. Wu, Y. Deng, Y. Shen, Q. Wang, W. Liu, J. Liu, M. Chen, L. Dong, W. Jia, H. Chen, F. Liu, R. Yuan, H. Xu, Z. Yan, T. Cao, Z. Hu, X. Feng, D. Du, T. Yu, Y. Tao, F. Zhang, J. Zhu, C. Xu, X. Li, C. Zha, W. Ouyang, Y. Xia, X. Li, Z. He, R. Chen, J. Song, R. Chen, F. Jiang, C. Zhao, B. Wang, H. Gong, R. Gan, W. Hu, Z. Kang, Y. Yang, Y. Liu, D. Wang, and J. Jiang, “Hunyuan-large: An open-source MoE model with 52 billion activated parameters by tencent,” arXiv preprint arXiv: 2411.02265, 2024.
|
| [11] |
M. Xu, W. Yin, D. Cai, R. Yi, D. Xu, Q. Wang, B. Wu, Y. Zhao, C. Yang, S. Wang, Q. Zhang, Z. Lu, L. Zhang, S. Wang, Y. Li, Y. Liu, X. Jin, and X. Liu, “A survey of resource-efficient LLM and multimodal foundation models,” arXiv preprint arXiv: 2401.08092, 2024.
|
| [12] |
DeepSeek-AI, “DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model,” arXiv preprint arXiv: 2405.04434, 2024.
|
| [13] |
DeepSeek-AI, “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,” arXiv preprint arXiv: 2501.12948, 2025.
|
| [14] |
OpenAI, “GPT-4O system card,” arXiv preprint arXiv: 2410.21276, 2024.
|
| [15] |
OpenAI, “Introducing OpenAI o1,” 2025. [Online]. Available: https://openai.com/o1/.
|
| [16] |
DeepSeek-AI, X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, H. Gao, K. Gao, W. Gao, R. Ge, K. Guan, D. Guo, J. Guo, G. Hao, Z. Hao, Y. He, W. Hu, P. Huang, E. Li, G. Li, J. Li, Y. Li, Y. K. Li, W. Liang, F. Lin, A. X. Liu, B. Liu, W. Liu, X. Liu, X. Liu, Y. Liu, H. Lu, S. Lu, F. Luo, S. Ma, X. Nie, T. Pei, Y. Piao, J. Qiu, H. Qu, T. Ren, Z. Ren, C. Ruan, Z. Sha, Z. Shao, J. Song, X. Su, J. Sun, Y. Sun, M. Tang, B. Wang, P. Wang, S. Wang, Y. Wang, Y. Wang, T. Wu, Y. Wu, X. Xie, Z. Xie, Z. Xie, Y. Xiong, H. Xu, R. X. Xu, Y. Xu, D. Yang, Y. You, S. Yu, X. Yu, B. Zhang, H. Zhang, L. Zhang, L. Zhang, M. Zhang, M. Zhang, W. Zhang, Y. Zhang, C. Zhao, Y. Zhao, S. Zhou, S. Zhou, Q. Zhu, Y. Zou, “DeepSeek LLM: Scaling open-source language models with longtermism,” arXiv preprint arXiv: 2401.02954, 2024.
|
| [17] |
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv: 2302.13971, 2023.
|
| [18] |
D. Dai, C. Deng, C. Zhao, R. X. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y. Wu, Z. Xie, Y. K. Li, P. Huang, F. Luo, C. Ruan, Z. Sui, and W. Liang, “DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models,” in Proc. 62nd Annu. Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 1280–1297.
|
| [19] |
DeepSeek-AI, “DeepSeek-V3 technical report,” arXiv preprint arXiv: 2412.19437, 2024.
|
| [20] |
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. K. Li, Y. Wu, D. Guo, “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models,” arXiv preprint arXiv: 2402.03300, 2024.
|
| [21] |
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y. Wu, Y. K. Li, F. Luo, Y. Xiong, and W. Liang, “DeepSeek-Coder: When the large language model meets programming–the rise of code intelligence,” arXiv preprint arXiv: 2401.14196, 2024.
|
| [22] |
DeepSeek-AI, Q. Zhu, D. Guo, Z. Shao, D. Yang, P. Wang, R. Xu, Y. Wu, Y. Li, H. Gao, S. Ma, W. Zeng, X. Bi, Z. Gu, H. Xu, D. Dai, K. Dong, L. Zhang, Y. Piao, Z. Gou, Z. Xie, Z. Hao, B. Wang, J. Song, D. Chen, X. Xie, K. Guan, Y. You, A. Liu, Q. Du, W. Gao, X. Lu, Q. Chen, Y. Wang, C. Deng, J. Li, C. Zhao, C. Ruan, F. Luo, and W. Liang, “DeepSeek-Coder-V2: Breaking the barrier of closed-source models in code intelligence,” arXiv preprint arXiv: 2406.11931, 2024.
|
| [23] |
Common Crawl, “ Common Crawl maintains a free, open repository of web crawl data that can be used by anyone,” 2025. [Online]. Available: https://commoncrawl.org.
|
| [24] |
H. Xin, D. Guo, Z. Shao, Z. Ren, Q. Zhu, B. Liu, C. Ruan, W. Li, and X. Liang, “DeepSeek-Prover: Advancing theorem proving in LLMs through large-scale synthetic data,” arXiv preprint arXiv: 2405.14333, 2024.
|
| [25] |
H. Xin, Z. Z. Ren, J. Song, Z. Shao, W. Zhao, H. Wang, B. Liu, L. Zhang, X. Lu, Q. Du, W. Gao, H. Zhang, Q. Zhu, D. Yang, Z. Gou, Z. F. Wu, F. Luo, and C. Ruan, “DeepSeek-Prover-V1.5: Harnessing proof assistant feedback for reinforcement learning and Monte-Carlo tree search,” in Proc. 13th Int. Conf. Learning Representations, Singapore, Singapore, 2025.
|
| [26] |
H. Lu, W. Liu, B. Zhang, B. Wang, K. Dong, B. Liu, J. Sun, T. Ren, Z. Li, H. Yang, Y. Sun, C. Deng, H. Xu, Z. Xie, and C. Ruan, “DeepSeek-VL: Towards real-world vision-language understanding,” arXiv preprint arXiv: 2403.05525, 2024.
|
| [27] |
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, and R. Girshick, “Segment anything,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 3992–4003.
|
| [28] |
Y. Li, H. Mao, R. Girshick, and K. He, “Exploring plain vision transformer backbones for object detection,” in Proc. 17th European Conf. Computer Vision, Tel Aviv, Israel, 2022, pp. 280–296.
|
| [29] |
Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y. Ma, C. Wu, B. Wang, Z. Xie, Y. Wu, K. Hu, J. Wang, Y. Sun, Y. Li, Y. Piao, K. Guan, A. Liu, X. Xie, Y. You, K. Dong, X. Yu, H. Zhang, L. Zhao, Y. Wang, and C. Ruan, “DeepSeek-VL2: Mixture-of-experts vision-language models for advanced multimodal understanding,” arXiv preprint arXiv: 2412.10302, 2024.
|
| [30] |
C. Wu, X. Chen, Z. Wu, Y. Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruan, and P. Luo, “Janus: Decoupling visual encoding for unified multimodal understanding and generation,” arXiv preprint arXiv: 2410.13848, 2024.
|
| [31] |
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Paris, France, 2023, pp. 11941–11952.
|
| [32] |
P. Sun, Y. Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan, “Autoregressive model beats diffusion: Llama for scalable image generation,” arXiv preprint arXiv: 2406.06525, 2024.
|
| [33] |
Y. Ma, X. Liu, X. Chen, W. Liu, C. Wu, Z. Wu, Z. Pan, Z. Xie, H. Zhang, X. Yu, L. Zhao, Y. Wang, J. Liu, and C. Ruan, “JanusFlow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation,” arXiv preprint arXiv: 2411.07975, 2024.
|
| [34] |
X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, and C. Ruan, “Janus-Pro: Unified multimodal understanding and generation with data and model scaling,” arXiv preprint arXiv: 2501.17811, 2025.
|
| [35] |
A. Temsah, K. Alhasan, I. Altamimi, A. Jamal, A. Al-Eyadhy, K. H. Malki, and M.-H. Temsah, “DeepSeek in healthcare: Revealing opportunities and steering challenges of a new open-source artificial intelligence frontier,” Cureus, vol. 17, p. 2, Feb. 2025. doi: 10.18605/2175-7275/cereus.v16n4p2-16 |
| [36] |
O. Arabiat, “DeepSeek AI in accounting: Opportunities and challenges in intelligent automation,” 2025.
|
| [37] |
L. Qian, W. Zhou, Y. Wang, X. Peng, J. Huang, Q. Xie, and J. Nie, “Fino1: On the transferability of reasoning enhanced LLMs to finance,” arXiv preprint arXiv: 2502.08127, 2025.
|
| [38] |
M. Zhao, H. He, M. Zhou, Y. Han, X. Song, and Y. Zhou, “Evaluating the readability and quality of AI-generated scoliosis education materials: A comparative analysis of five language models,” 2025.
|
| [39] |
W. Zhang, X. Lei, Z. Liu, N. Wang, Z. Long, P. Yang, J. Zhao, M. Hua, C. Ma, K. Wang, and S. Lian, “Safety evaluation of DeepSeek models in Chinese contexts,” arXiv preprint arXiv: 2502.11137, 2025.
|
| [40] |
M. N.-U.-R. Chowdhury, A. Haque, and I. Ahmed, “DeepSeek vs. ChatGPT: A comparative analysis of performance, efficiency, and ethical AI considerations,” TechRxiv, 2025, DOI: 10.36227/techrxiv.173929663.35290537/v1. |
| [41] |
Artificial analysis. [Online]. Available: https://artificialanalysis.ai/. Accessed on: Mar. 4, 2025.
|
| [42] |
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “LiveCodeBench: Holistic and contamination free evaluation of large language models for code,” arXiv preprint arXiv: 2403.07974, 2024.
|
| [43] |
M. Tian, L. Gao, S. D. Zhang, X. Chen, C. Fan, X. Guo, R. Haas, P. Ji, K. Krongchon, Y. Li, S. Liu, D. Luo, Y. Ma, H. Tong, K. Trinh, C. Tian, Z. Wang, B. Wu, S. Yin, M. Zhu, K. Lieret, Y. Lu, G. Liu, Y. Du, T. Tao, O. Press, J. Callan, E. A. Huerta, and H. Peng, “SciCode: A research coding benchmark curated by scientists,” in Proc. 38th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2024, pp. 30624–30650.
|
| [44] |
M. Jia, “AIME 2024 dataset,” 2024. [Online]. Available: https://huggingface.co/datasets/Maxwell-Jia/AIME_2024. Accessed on: Mar. 4, 2025.
|
| [45] |
HuggingFaceH4, “MATH-500 dataset,” 2024. [Online]. Available: https://huggingface.co/datasets/HuggingFaceH4/MATH-500/blob/main/README.md. Accessed on: Mar. 4, 2025.
|
| [46] |
Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen, “MMLU-Pro: A more robust and challenging multi-task language understanding benchmark,” arXiv preprint arXiv: 2406.01574, 2024.
|
| [47] |
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman, “GPQA: A graduate-level google-proof Q&A benchmark,” arXiv preprint arXiv: 2311.12022, 2023.
|
| [48] |
L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, M. Choi, A. Agrawal, A. Chopra, A. Khoja, R. Kim, R. Ren, J. Hausenloy, O. Zhang, M. Mazeika, S. Yue, A. Wan, and D. Hendrycks, “Humanity’s last exam,” arXiv preprint arXiv: 2501.14249, 2025.
|
| [49] |
N. Du, Y. Huang, A. M. Dai, S. Tong, D. Lepikhin, Y. Xu, M. Krikun, Y. Zhou, A. W. Yu, O. Firat, B. Zoph, L. Fedus, M. P. Bosma, Z. Zhou, T. Wang, E. Wang, K. Webster, M. Pellat, K. Robinson, K. Meier-Hellstern, T. Duke, L. Dixon, K. Zhang, Q. Le, Y. Wu, Z. Chen, and C. Cui, “GLaM: Efficient scaling of language models with mixture-of-experts,” in Proc. 39th Int. Conf. Machine Learning, Baltimore, USA, 2022, pp. 5547–5569.
|
| [50] |
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” J. Mach. Learn. Res., vol. 23, no. 1, p. 120, 2022.
|
| [51] |
D. Lepikhin, H. Lee, Y. Xu, D. Chen, O. Firat, Y. Huang, M. Krikun, N. Shazeer, and Z. Chen, “GShard: Scaling giant models with conditional computation and automatic sharding,” in Proc. 9th Int. Conf. Learning Representations, Austria, 2021.
|
| [52] |
ANTHROPIC. Claude 3.5 sonnet. 2024. [Online]. Available: https://www.anthropic.com/news/claude-3-5-sonnet
|
| [53] |
xAI. xAI official website. [Online]. Available: https://x.ai/. Accessed on: Mar. 3, 2025.
|
| [54] |
Qwen Team, “Qwen2.5 technical report,” arXiv preprint arXiv: 2412.15115, 2024.
|
| [55] |
Z. Jiang, H. Lin, Y. Zhong, Q. Huang, Y. Chen, Z. Zhang, Y. Peng, X. Li, C. Xie, S. Nong, Y. Jia, S. He, H. Chen, Z. Bai, Q. Hou, S. Yan, D. Zhou, Y. Sheng, Z. Jiang, H. Xu, H. Wei, Z. Zhang, P. Nie, L. Zou, S. Zhao, L. Xiang, Z. Liu, Z. Li, X. Jia, J. Ye, X. Jin, and X. Liu, “MegaScale: Scaling large language model training to more than 10,000 GPUs,” in Proc. 21st USENIX Symp. Networked Systems Design and Implementation, Santa Clara, USA, 2024, pp. 745–760.
|
| [56] |
Q. Chen, Q. Hu, G. Wang, Y. Xiong, T. Huang, X. Chen, Y. Gao, H. Yan, Y. Wen, T. Zhang, and P. Sun, “Lins: Reducing communication overhead of ZeRo for efficient LLM training,” in Proc. IEEE/ACM 32nd Int. Symp. Quality of Service, Guangzhou, China, 2024, pp. 1–10.
|
| [57] |
Y. Huang, Y. Cheng, A. Bapna, O. Firat, M. X. Chen, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu, and Z. Chen, “GPipe: Efficient training of giant neural networks using pipeline parallelism,” in Proc. 33rd Int. Conf. Neural Information Processing Systems, 2019, pp. 10.
|
| [58] |
D. Narayanan, A. Harlap, A. Phanishayee, V. Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia, “PipeDream: Generalized pipeline parallelism for DNN training,” in Proc. 27th ACM Symp. Operating Systems Principles, Huntsville, Canada, 2019, pp. 1–15.
|
| [59] |
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-LM: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv: 1909.08053, 2019.
|
| [60] |
Y. Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer, A. Desmaison, C. Balioglu, P. Damania, B. Nguyen, G. Chauhan, Y. Hao, A. Mathews, and S. Li, “PyTorch FSDP: Experiences on scaling fully sharded data parallel,” Proc. VLDB Endow., vol. 16, no. 12, pp. 3848–3860, Aug. 2023. doi: 10.14778/3611540.3611569 |
| [61] |
A. Waswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. 31st Int. Conf. Neural Information Processing Systems, Long Beach, USA, 2017, pp. 6000–6010.
|
| [62] |
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu, “RoFormer: Enhanced transformer with rotary position embedding,” Neurocomputing, vol. 568, p. 127063, Feb. 2024. doi: 10.1016/j.neucom.2023.127063 |
| [63] |
Chameleon Team, “Chameleon: Mixed-modal early-fusion foundation models,” arXiv preprint arXiv: 2405.09818, 2024.
|
| [64] |
X. Wang, X. Zhang, Z. Luo, Q. Sun, Y. Cui, J. Wang, F. Zhang, Y. Wang, Z. Li, Q. Yu, Y. Zhao, Y. Ao, X. Min, T. Li, B. Wu, B. Zhao, B. Zhang, L. Wang, G. Liu, Z. He, X. Yang, J. Liu, Y. Lin, T. Huang, and Z. Wang, “Emu3: Next-token prediction is all you need,” arXiv preprint arXiv: 2409.18869, 2024.
|
| [65] |
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. H. Chi, Q. V. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” in Proc. 36th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2022, pp. 1800.
|
| [66] |
W. Chen, X. Ma, X. Wang, and W. W. Cohen, “Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,” Trans. Mach. Learn. Res., vol. 2023, 2023.
|
| [67] |
Z. Gou, Z. Shao, Y. Gong, Y. Shen, Y. Yang, M. Huang, N. Duan, and W. Chen, “ToRA: A tool-integrated reasoning agent for mathematical problem solving,” in Proc. 12th Int. Conf. Learning Representations, Vienna, Austria, 2024, pp. 1–34.
|
| [68] |
T. Chu, Y. Zhai, J. Yang, S. Tong, S. Xie, S. Levine, and Y. Ma, “SFT memorizes, RL generalizes: A comparative study of foundation model post-training,” in Proc. 2nd Conf. Parsimony and Learning, Stanford, USA, 2025.
|
| [69] |
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv: 1707.06347, 2017.
|
| [70] |
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High-dimensional continuous control using generalized advantage estimation,” in Proc. 4th Int. Conf. Learning Representations, San Juan, Puerto Rico, 2016.
|
| [71] |
D. Mikhail, A. Farah, J. Milad, W. Nassrallah, A. Mihalache, D. Milad, F. Antaki, M. Balas, M. M. Popovic, A. Feo, R. H. Muni, P. A. Keane, and R. Duval, “Performance of DeepSeek-R1 in ophthalmology: An evaluation of clinical decision-making and cost-effectiveness,” medRxiv, 2025, DOI: 10.1101/2025.02.10.25322041. |
| [72] |
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V. Le, G. E. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” in Proc. 5th Int. Conf. Learning Representations, Toulon, France, 2017.
|
| [73] |
L. Wang, H. Gao, C. Zhao, X. Sun, and D. Dai, “Auxiliary-loss-free load balancing strategy for mixture-of-experts,” in Proc. 13th Int. Conf. Learning Representations, Singapore, Singapore, 2025.
|
| [74] |
M. Bavarian, H. Jun, N. Tezak, J. Schulman, C. McLeavey, J. Tworek, and M. Chen, “Efficient training of language models to fill in the middle,” arXiv preprint arXiv: 2207.14255, 2022.
|
| [75] |
C. Donahue, M. Lee, and P. Liang, “Enabling language models to fill in the blanks,” in Proc. 58th Annu. Meeting of the Association for Computational Linguistics, 2020, pp. 2492–2501.
|
| [76] |
W. An, X. Bi, G. Chen, S. Chen, C. Deng, H. Ding, K. Dong, Q. Du, W. Gao, K. Guan, J. Guo, Y. Guo, Z. Fu, Y. He, P. Huang, J. Li, W. Liang, X. Liu, X. Liu, Y. Liu, Y. Liu, S. Lu, X. Lu, X. Nie, T. Pei, J. Qiu, H. Qu, Z. Ren, Z. Sha, X. Su, X. Sun, Y. Tan, M. Tang, S. Wang, Y. Wang, Y. Wang, Z. Xie, Y. Xiong, Y. Xu, S. Ye, S. Yu, Y. Zha, L. Zhang, H. Zhang, M. Zhang, W. Zhang, Y. Zhang, C. Zhao, Y. Zhao, S. Zhou, S. Zhou, and Y. Zou, “Fire-Flyer AI-HPC: A cost-effective software-hardware co-design for deep learning.” in Proc. Int. Conf. High Performance Computing, Networking, Storage, and Analysis, Atlanta, USA, 2024, pp. 83.
|
| [77] |
C. E. Leiserson, “Fat-trees: Universal networks for hardware-efficient supercomputing,” IEEE Trans. Computers, vol. C-34, no. 10, pp. 892–901, Oct. 1985. doi: 10.1109/TC.1985.6312192 |
| [78] |
J. Kim, W. J. Dally, S. Scott, and D. Abts, “Technology-driven, highly-scalable dragonfly topology,” ACM SIGARCH Comput. Archit. News, vol. 36, no. 3, pp. 77–88, Jun. 2008. doi: 10.1145/1394608.1382129 |
| [79] |
NVIDIA, “NVIDIA collective communications library (NCCL),” 2017.
|
| [80] |
J. Rasley, S. Rajbhandari, O. Ruwase, and Y. He, “DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters,” in Proc. 26th ACM SIGKDD Int. Conf. Knowledge Discovery & Data Mining, 2020, pp. 3505–3506.
|
| [81] |
H. Subramoni, P. Lai, M. Luo, and D. K. Panda, “RDMA over Ethernet—a preliminary study,” in Proc. IEEE Int. Conf. Cluster Computing and Workshops, New Orleans, USA, 2009, pp. 1–9.
|
| [82] |
WEKA, “WEKA architectural whitepaper,” 2025. [Online]. Available: https://www.weka.io/resources/white-paper/wekaio-architectural-whitepaper/. Accessed on Feb. 23, 2025.
|
| [83] |
Z. Liang, J. Lombardi, M. Chaarawi, and M. Hennecke, “DAOS: A scale-out high performance storage stack for storage class memory,” in Proc. Supercomputing Frontiers: 6th Asian Conf., Singapore, Singapore, 2020, pp. 40–54.
|
| [84] |
J. Terrace and M. J. Freedman, “Object storage on CRAQ: High-throughput chain replication for read-mostly workloads,” in Proc. USENIX Annu. Technical Conf., San Diego, USA, 2009, pp. 11.
|
| [85] |
HFAiLab, “Hai platform,” [Online]. Available: https://github.com/HFAiLab/hai-platform. Accessed on Feb. 23, 2025.
|
| [86] |
H. Alghamdi and A. Mostafa, “Advancing EHR analysis: Predictive medication modeling using LLMs,” Inf. Syst., vol. 131, p. 102528, Jun. 2025. doi: 10.1016/j.is.2025.102528 |
| [87] |
G. Mondillo, S. Colosimo, A. Perrotta, V. Frattolillo, and M. Masino, “Comparative evaluation of advanced AI reasoning models in pediatric clinical decision support: ChatGPT O1 vs. DeepSeek-R1,” medRxiv, 2025, DOI: 10.1101/2025.01.27.25321169. |
| [88] |
L. F. de Paiva, G. Luijten, B. Puladi, and J. Egger, “How does DeepSeek-R1 perform on USMLE?” medRxiv, 2025, DOI: 10.1101/2025.02.06.25321749. |
| [89] |
M. Zhou, Y. Pan, Y. Zhang, X. Song, and Y. Zhou, “Evaluating AI-generated patient education materials for spinal surgeries: Comparative analysis of readability and discern quality across ChatGPT and DeepSeek models,” Int. J. Med. Inform., vol. 198, p. 105871, Jun. 2025. doi: 10.1016/j.ijmedinf.2025.105871 |
| [90] |
A. Choudhury, Y. Shahsavar, and H. Shamszare, “User intent to use DeepSeek for healthcare purposes and their trust in the large language model: Multinational survey study,” arXiv preprint arXiv: 2502.17487, 2025.
|
| [91] |
G. De Vito, F. Ferrucci, and A. Angelakis, “LLMs for drug-drug interaction prediction: A comprehensive comparison,” arXiv preprint arXiv: 2502.06890, 2025.
|
| [92] |
S. Hasan and S. Basak, “Open-source AI-powered optimization in scalene: Advancing python performance profiling with DeepSeek-R1 and LLaMA 3.2,” arXiv preprint arXiv: 2502.10299, 2025.
|
| [93] |
H. Zeng, D. Jiang, H. Wang, P. Nie, X. Chen, and W. Chen, “ACECODER: Acing coder RL via automated test-case synthesis,” arXiv preprint arXiv: 2502.01718, 2025.
|
| [94] |
M. Vero, N. Mündler, V. Chibotaru, V. Raychev, M. Baader, N. Jovanović, J. He, and M. Vechev, “BaxBench: Can LLMs generate correct and secure backends?” in Proc. 13th Int. Conf. Learning Representations, Singapore, Singapore, 2025.
|
| [95] |
D. Zhang, J. Wang, and T. Sun, “Building a proof-oriented programmer that is 64% better than GPT-4o under data scarcity,” arXiv preprint arXiv: 2502.11901, 2025.
|
| [96] |
Y.-C. Yu, T.-H. Chiang, C.-W. Tsai, C.-M. Huang, and W.-K. Tsao, “Primus: A pioneering collection of open-source datasets for cybersecurity LLM training,” arXiv preprint arXiv: 2502.11191, 2025.
|
| [97] |
J. Chen, G. Tang, G. Zhou, and W. Zhu, “ChatGPT and DeepSeek: Can they predict the stock market and macroeconomy?” arXiv preprint arXiv: 2502.10008, 2025.
|
| [98] |
D. Krause, “DeepSeek and FinTech: The democratization of AI and its global implications,” Available at SSRN 5116322, 2025.
|
| [99] |
K. T. Kotsis, “ChatGPT and DeepSeek evaluate one another for science education,” EIKI J. Eff. Teach. Methods, vol. 3, no. 1, 2025.
|
| [100] |
N. Kerimbayev, Z. Menlibay, M. Garvanova, S. Djaparova, and V. Jotsov, “A comparative analysis of generative AI models for improving learning process in higher education,” in Proc. Int. Conf. Automatics and Informatics (ICAI), Varna, Bulgaria, 2024, pp. 271–276.
|
| [101] |
Y. Lin, S. Tang, B. Lyu, J. Wu, H. Lin, K. Yang, J. Li, M. Xia, D. Chen, S. Arora, and C. Jin, “Goedel-Prover: A Frontier model for open-source automated theorem proving,” arXiv preprint arXiv: 2502.07640, 2025.
|
| [102] |
K. Dong and T. Ma, “Beyond limited data: Self-play LLM theorem provers with iterative conjecturing and proving,” arXiv preprint arXiv: 2502.00212, 2025.
|
| [103] |
J. O. J. Leang, G. Hong, W. Li, and S. B. Cohen, “Theorem prover as a judge for synthetic data generation,” arXiv preprint arXiv: 2502.13137, 2025.
|
| [104] |
J. Boye and B. Moell, “Large language models and mathematical reasoning failures,” arXiv preprint arXiv: 2502.11574, 2025.
|
| [105] |
J. Zhong, Z. Li, Z. Xu, X. Wen, and Q. Xu, “Dyve: Thinking fast and slow for dynamic process verification,” arXiv preprint arXiv: 2502.11157, 2025.
|
| [106] |
Y. Cao, H. Liu, A. Arora, I. Augenstein, P. Röttger, and D. Hershcovich, “Specializing large language models to simulate survey response distributions for global populations,” arXiv preprint arXiv: 2502.07068, 2025.
|
| [107] |
J. Fu, X. Ge, K. Zheng, I. Arapakis, X. Xin, and J. M. Jose, “LLMPopcorn: An empirical study of LLMs as assistants for popular micro-video generation,” arXiv preprint arXiv: 2502.12945, 2025.
|
| [108] |
S. Zhang, X. Wang, W. Zhang, C. Li, J. Song, T. Li, L. Qiu, X. Cao, X. Cai, W. Yao, W. Zhang, X. Wang, and Y. Wen, “Leveraging dual process theory in language agent framework for real-time simultaneous human-AI collaboration,” arXiv preprint arXiv: 2502.11882, 2025.
|
| [109] |
A. M. Bran, S. Cox, O. Schilter, C. Baldassari, A. D. White, and P. Schwaller, “Augmenting large language models with chemistry tools,” Nat. Mach. Intell., vol. 6, no. 5, pp. 525–535, May 2024. doi: 10.1038/s42256-024-00832-8 |
| [110] |
C. Chakraborty, M. Bhattacharya, S. Pal, S. Chatterjee, A. Das, and S.-S. Lee, “Ai-enabled language models (LMs) to large language models (LLMs) and multimodal large language models (MLLMS) in drug discovery and development,” J. Adv. Res., 2025, DOI: 10.1016/j.jare.2025.02.011. |
| [111] |
Y. Peng, B. A. Malin, J. F. Rousseau, Y. Wang, Z. Xu, X. Xu, C. Weng, and J. Bian, “From GPT to DeepSeek: Significant gaps remain in realizing AI in healthcare,” J. Biomed. Inf., vol. 163, p. 104791, Mar. 2025. doi: 10.1016/j.jbi.2025.104791 |
| [112] |
Z. Gan, Y. Lu, D. Zhang, H. Li, C. Liu, J. Liu, J. Liu, H. Wu, C. Fu, Z. Xu, R. Zhang, and Y. Dai, “MME-Finance: A multimodal finance benchmark for expert-level understanding and reasoning,” arXiv preprint arXiv: 2411.03314, 2024.
|
| [113] |
“DeepSeek course,” 2025. [Online]. Available: https://www.nobleprog.com.au/cc/DeepSeekedu.
|
| [114] |
“Awesome DeepSeek integrations,” 2025. [Online]. Available: https://github.com/DeepSeek-ai/awesome-DeepSeek-integration.
|
| [115] |
A. Arrieta, M. Ugarte, P. Valle, J. A. Parejo, and S. Segura, “o3-mini vs DeepSeek-R1: Which one is safer?” arXiv preprint arXiv: 2501.18438, 2025.
|
| [116] |
H. Zhang, H. Gao, Q. Hu, G. Chen, L. Yang, B. Jing, H. Wei, B. Wang, H. Bai, and L. Yang, “ChineseSafe: A Chinese benchmark for evaluating safety in large language models,” arXiv preprint arXiv: 2410.18491, 2024.
|
| [117] |
K. Zhou, C. Liu, X. Zhao, S. Jangam, J. Srinivasa, G. Liu, D. Song, and X. E. Wang, “The hidden risks of large reasoning models: A safety assessment of R1,” arXiv preprint arXiv: 2502.12659, 2025.
|
| [118] |
T. Gu, Z. Zhou, K. Huang, D. Liang, Y. Wang, H. Zhao, Y. Yao, X. Qiao, K. Wang, Y. Yang, Y. Teng, Y. Qiao, and Y. Wang, “MLLMguard: A multi-dimensional safety evaluation suite for multimodal large language models,” in Proc. 38th Int. Conf. on Neural Information Processing Systems, Vancouver, Canada, 2025, pp. 7256–7295.
|
| [119] |
A. Rydén, E. Näslund, E. M. Schiller, and M. Almgren, “LLMSecCode: Evaluating large language models for secure coding,” in Proc. 8th Int. Symp. Cyber Security, Cryptology, and Machine Learning, Beer Sheva, Israel, 2024, pp. 100–118.
|
| [120] |
R. Lu, J. Sedoc, and A. Sundararajan, “Reasoning and the trusting behavior of DeepSeek and GPT: An experiment revealing hidden fault lines in large language models,” arXiv preprint arXiv: 2502.12825, 2025.
|
| [121] |
R. Ye, X. Pang, J. Chai, J. Chen, Z. Yin, Z. Xiang, X. Dong, J. Shao, and S. Chen, “Are we there yet? Revealing the risks of utilizing large language models in scholarly peer review,” arXiv preprint arXiv: 2412.01708, 2024.
|
| [122] |
S. K. Barkur, S. Schacht, and J. Scholl, “Deception in LLMs: Self-preservation and autonomous goals in large language models,” arXiv preprint arXiv: 2501.16513, 2025.
|
| [123] |
M. Kuo, J. Zhang, A. Ding, Q. Wang, L. DiValentin, Y. Bao, W. Wei, H. Li, and Y. Chen, “H-CoT: Hijacking the chain-of-thought safety reasoning mechanism to jailbreak large reasoning models, including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 flash thinking,” arXiv preprint arXiv: 2502.12893, 2025.
|
| [124] |
Z. Lin, W. Ma, M. Zhou, Y. Zhao, H. Wang, Y. Liu, J. Wang, and L. Li, “PathSeeker: Exploring LLM security vulnerabilities with a reinforcement learning-based jailbreak approach,” arXiv preprint arXiv: 2409.14177, 2024.
|
| [125] |
C. M. Islam, S. J. Chacko, P. Horne, and X. Liu, “DeepSeek on a trip: Inducing targeted visual hallucinations via representation vulnerabilities,” arXiv preprint arXiv: 2502.07905, 2025.
|
| [126] |
F. Jiang, Z. Xu, Y. Li, L. Niu, Z. Xiang, B. Li, B. Y. Lin, and R. Poovendran, “SafeChain: Safety of language models with long chain-of-thought reasoning capabilities,” in Proc. 13th Int. Conf. Learning Representations, Singapore, Singapore, 2025.
|
| [127] |
M. Parmar and Y. Govindarajulu, “Challenges in ensuring AI safety in DeepSeek-R1 models: The shortcomings of reinforcement learning strategies,” arXiv preprint arXiv: 2501.17030, 2025.
|
| [128] |
G. Yang, Y. Zhou, X. Chen, X. Zhang, T. Y. Zhuo, D. Lo, and T. Chen, “DeCE: Deceptive cross-entropy loss designed for defending backdoor attacks,” arXiv preprint arXiv: 2407.08956, 2024.
|
| [129] |
D. Li, M. Yan, Y. Zhang, Z. Liu, C. Liu, X. Zhang, T. Chen, and D. Lo, “CoSec: On-the-Fly security hardening of code LLMs via supervised co-decoding,” in Proc. 33rd ACM SIGSOFT Int. Symp. Software Testing and Analysis, Vienna, Austria, 2024, pp. 1428–1439.
|
| [130] |
M. I. Hossen, J. Zhang, Y. Cao, and X. Hei, “Assessing cybersecurity vulnerabilities in code large language models,” arXiv preprint arXiv: 2404.18567, 2024.
|
| [131] |
Z. Xu, J. Gardiner, and S. Belguith, “The dark deep side of DeepSeek: Fine-tuning attacks against the safety alignment of CoT-enabled models,” arXiv preprint arXiv: 2502.01225, 2025.
|
| [132] |
Z. Zhu, H. Zhang, M. Zhang, R. Wang, G. Wu, K. Xu, and B. Wu, “BoT: Breaking long thought processes of o1-like large language models through backdoor attack,” arXiv preprint arXiv: 2502.12202, 2025.
|
| [133] |
Y. Nie, C. Wang, K. Wang, G. Xu, G. Xu, and H. Wang, “Decoding secret memorization in code LLMs through token-level characterization,” arXiv preprint arXiv: 2410.08858, 2024.
|
| [134] |
R. Gupta, “Comparative analysis of DeepSeek R1, ChatGPT, Gemini, Alibaba, and LLaMA: Performance, reasoning capabilities, and political bias,” Authorea, 2025, DOI: 10.22541/au.173921625.50315230/v1. |
| [135] |
M. Ugarte, P. Valle, J. A. Parejo, S. Segura, and A. Arrieta, “ASTRAL: Automated safety testing of large language models,” arXiv preprint arXiv: 2501.17132, 2025.
|
| [136] |
Y. Xie, J. Yi, J. Shao, J. Curl, L. Lyu, Q. Chen, X. Xie, and F. Wu, “Defending ChatGPT against jailbreak attack via self-reminders,” Nat. Mach. Intell., vol. 5, no. 12, pp. 1486–1496, Dec. 2023. doi: 10.1038/s42256-023-00765-8 |
| [137] |
J. Mökander, J. Schuett, H. R. Kirk, and L. Floridi, “Auditing large language models: A three-layered approach,” AI Ethics, vol. 4, no. 4, pp. 1085–1115, Nov. 2024. doi: 10.1007/s43681-023-00289-2 |
| [138] |
T. Liu, W. Xiong, J. Ren, L. Chen, J. Wu, R. Joshi, Y. Gao, J. Shen, Z. Qin, T. Yu, D. Sohn, A. Makarova, J. Z. Liu, Y. Liu, B. Piot, A. Ittycheriah, A. Kumar, and M. Saleh, “RRM: Robust reward model training mitigates reward hacking,” in Proc. 13th Int. Conf. Learning Representations, Singapore, Singapore, 2025.
|
| [139] |
C. Iwendi, S. A. Moqurrab, A. Anjum, S. Khan, S. Mohan, and G. Srivastava, “N-Sanitization: A semantic privacy-preserving framework for unstructured medical datasets,” Comput. Commun., vol. 161, pp. 160–171, Sep. 2020. doi: 10.1016/j.comcom.2020.07.032 |
| [140] |
L. Miao, W. Yang, R. Hu, L. Li, and L. Huang, “Against backdoor attacks in federated learning with differential privacy,” in Proc. IEEE Int. Conf. Acoustics, Speech and Signal Processing, Singapore, Singapore, 2022, pp. 2999–3003.
|
| [141] |
N. Gu, P. Fu, X. Liu, Z. Liu, Z. Lin, and W. Wang, “A gradient control method for backdoor attacks on parameter-efficient tuning,” in Proc. 61st Annu. Meeting of the Association for Computational Linguistics, Toronto, Canada, 2023, pp. 3508–3520.
|
| [142] |
“House bill Report HB 1121,” [Online]. Available: https://lawfilesext.leg.wa.gov/biennium/2025-26/Pdf/Bill%20Reports/House/1121%20HBR%20LAWS%2025.pdf.
|
| [143] |
Government of South Australia. DeepSeek banned from SA government. 2025. [Online]. Available: https://www.premier.sa.gov.au/media-releases/news-items/deepseek-banned-from-sa-government. Accessed on: Feb. 25, 2025.
|
| [144] |
V. Habib Lantyer, “How U.S. trade sanctions fueled Chinese innovation in AI: The DeepSeek case,” SSRN, 2025, DOI: 10.2139/ssrn.5112973. |
| [145] |
M. Novak, M. Joy, and D. Kermek, “Source-code similarity detection and detection tools used in academia: A systematic review,” ACM Trans. Comput. Educ., vol. 19, no. 3, p. 27, May 2019.
|
| [146] |
S. Goyal, P. Maini, Z. C. Lipton, A. Raghunathan, and J. Z. Kolter, “Scaling laws for data filtering–data curation cannot be compute agnostic,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 22702–22711.
|
| [147] |
I. E. Olatunji, J. Rauch, M. Katzensteiner, and M. Khosla, “A review of anonymization for healthcare data,” Big Data, vol. 12, no. 6, pp. 538–555, Dec. 2024. doi: 10.1089/big.2021.0169 |
| [148] |
N. Sun, J. Zhang, P. Rimba, S. Gao, L. Y. Zhang, and Y. Xiang, “Data-driven cybersecurity incident prediction: A survey,” IEEE Commun. Surv. Tutorials, vol. 21, no. 2, pp. 1744–1772, Apr.-Jun. 2019. doi: 10.1109/COMST.2018.2885561 |
| [149] |
B. B. Gupta, A. Gaurav, V. Arya, W. Alhalabi, D. Alsalman, and P. Vijayakumar, “Enhancing user prompt confidentiality in Large Language Models through advanced differential encryption,” Comput. Electr. Eng., vol. 116, p. 109215, 2024. doi: 10.1016/j.compeleceng.2024.109215 |
| [150] |
J. Piet, M. Alrashed, C. Sitawarin, S. Chen, Z. Wei, E. Sun, B. Alomair, and D. Wagner, “Jatmo: Prompt injection defense by task-specific finetuning,” in Proc. 29th European Symp. Research in Computer Security, Bydgoszcz, Poland, 2024, pp. 105–124.
|
| [151] |
Q. Wang, Z. Tang, and B. He, “From ChatGPT to DeepSeek: Can LLMs simulate humanity?” arXiv preprint arXiv: 2502.18210, 2025.
|
| [152] |
E. Loza de Siles, “Slavery. AI,” Wash. Lee J. Civ. Rights Soc. Just., vol. 30, no. 2, p. 4, Jun. 2024.
|
| [153] |
J. Xiao, Z. Li, X. Xie, E. Getzen, C. Fang, Q. Long, and W. J. Su, “On the algorithmic bias of aligning large language models with RLHF: Preference collapse and matching regularization,” arXiv preprint arXiv: 2405.16455, 2024.
|
| [154] |
G. Adomavicius, J. Bockstedt, S. P. Curley, J. Zhang, and S. Ransbotham, “The hidden side effects of recommendation systems,” MIT Sloan Manage. Rev., vol. 60, no. 2, pp. 1, Nov. 2018.
|
| [155] |
B. Perrigo, “Exclusive: OpenAI used Kenyan workers on less than $2 per hour to make ChatGPT less toxic,” 2023. [Online]. Available: https://time.com/6247678/openai-ChatGPT-kenya-workers/.
|
| [156] |
R. Tan, “Behind the AI boom, an army of overseas workers in ’digital sweatshops’,” The Washington Post, 2023. [Online]. Available: https://bestofai.com/article/behind-the-ai-boom-an-army-of-overseas-workers-in-digital-sweatshops.
|
| [157] |
L. Finlay, P. Hooton, and C. Wallace, “Big tech is ignoring the human cost behind the rise of ChatGPT,” The Australian Financial Review, 2023. [Online]. Available: https://www.afr.com/technology/big-tech-isignoring-the-human-cost-behind-the-rise-of-ChatGPT-20230210-p5cjll.
|
| [158] |
B. Draghi, Z. Wang, P. Myles, and A. Tucker, “Identifying and handling data bias within primary healthcare data using synthetic data generators,” Heliyon, vol. 10, p. 2, 2024.
|
| [159] |
R. Correa, K. Pahwa, B. Patel, C. M. Vachon, J. W. Gichoya, and I. Banerjee, “Efficient adversarial debiasing with concept activation vector—medical image case-studies,” J. Biomed. Inf., vol. 149, p. 104548, Jan. 2024. doi: 10.1016/j.jbi.2023.104548 |
| [160] |
U. Iqbal, T. Kohno, and F. Roesner, “LLM platform security: Applying a systematic evaluation framework to OpenAI’s ChatGPT plugins,” in Proc. 7th AAAI/ACM Conf. AI, Ethics, and Society, San Jose, USA, 2024, pp. 611–623.
|
| [161] |
Y. Liu, K. Zhang, Y. Li, Z. Yan, C. Gao, R. Chen, Z. Yuan, Y. Huang, H. Sun, J. Gao, L. He, and L. Sun, “Sora: A review on background, technology, limitations, and opportunities of large vision models,” arXiv preprint arXiv: 2402.17177, 2024.
|
| [162] |
R. Wu, B. Mildenhall, P. Henzler, K. Park, R. Gao, D. Watson, P. P. Srinivasan, D. Verbin, J. T. Barron, B. Poole, and A. Hołyński, “ReconFusion: 3D reconstruction with diffusion priors,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2024, pp. 21551–21561.
|
| [163] |
Y. Lin, R. Clark, and P. Torr, “DreamPolisher: Towards high-quality text-to-3D generation via geometric diffusion,” arXiv preprint arXiv: 2403.17237, 2024.
|
| [164] |
Z. Durante, Q. Huang, N. Wake, R. Gong, J. S. Park, B. Sarkar, R. Taori, Y. Noda, D. Terzopoulos, Y. Choi, K. Ikeuchi, H. Vo, L. Fei-Fei, and J. Gao, “Agent AI: Surveying the horizons of multimodal interaction,” arXiv preprint arXiv: 2401.03568, 2024.
|
| [165] |
Z. Deng, Y. Guo, C. Han, W. Ma, J. Xiong, S. Wen, and Y. Xiang, “AI agents under threat: A survey of key security challenges and future pathways,” ACM Comput. Surv., vol. 57, no. 7, p. 182, Feb. 2025. doi: 10.1145/3716628 |
| [166] |
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. Chatterji, A. Chen, K. Creel, J. Q. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, K. Ethayarajh, L. Fei-Fei, C. Finn, T. Gale, L. Gillespie, K. Goel, N. Goodman, S. Grossman, N. Guha, T. Hashimoto, P. Henderson, J. Hewitt, D. E. Ho, J. Hong, K. Hsu, J. Huang, T. Icard, S. Jain, D. Jurafsky, P. Kalluri, S. Karamcheti, G. Keeling, F. Khani, O. Khattab, P. W. Koh, M. Krass, R. Krishna, R. Kuditipudi, A. Kumar, F. Ladhak, M. Lee, T. Lee, J. Leskovec, I. Levent, X. L. Li, X. Li, T. Ma, A. Malik, C. D. Manning, S. Mirchandani, E. Mitchell, Z. Munyikwa, S. Nair, A. Narayan, D. Narayanan, B. Newman, A. Nie, J. C. Niebles, H. Nilforoshan, J. Nyarko, G. Ogut, L. Orr, I. Papadimitriou, J. S. Park, C. Piech, E. Portelance, C. Potts, A. Raghunathan, R. Reich, H. Ren, F. Rong, Y. Roohani, C. Ruiz, J. Ryan, C. Ré, D. Sadigh, S. Sagawa, K. Santhanam, A. Shih, K. Srinivasan, A. Tamkin, R. Taori, A. W. Thomas, F. Tramèr, R. E. Wang, W. Wang, B. Wu, J. Wu, Y. Wu, S. M. Xie, M. Yasunaga, J. You, M. Zaharia, M. Zhang, T. Zhang, X. Zhang, Y. Zhang, L. Zheng, K. Zhou, and P. Liang, “On the opportunities and risks of foundation models,” arXiv preprint arXiv: 2108.07258, 2021.
|
| [167] |
J. Duan, S. Yu, H. L. Tan, H. Zhu, and C. Tan, “A survey of embodied AI: From simulators to research tasks,” IEEE Trans. Emerg. Top. Comput. Intell., vol. 6, no. 2, pp. 230–244, Apr. 2022. doi: 10.1109/TETCI.2022.3141105 |
| [168] |
S. Patel, X. Yin, W. Huang, S. Garg, H. Nayyeri, L. Fei-Fei, S. Lazebnik, and Y. Li, “A real-to-sim-to-real approach to robotic manipulation with VLM-generated iterative keypoint rewards,” arXiv preprint arXiv: 2502.08643, 2025.
|
| [169] |
T. Wang, J. Fan, and P. Zheng, “An LLM-based vision and language cobot navigation approach for human-centric smart manufacturing,” J. Manuf. Syst., vol. 75, pp. 299–305, Aug. 2024. doi: 10.1016/j.jmsy.2024.04.020 |
| [170] |
T. Nguyen, C. Van Nguyen, V. D. Lai, H. Man, N. T. Ngo, F. Dernoncourt, R. A. Rossi, and T. H. Nguyen, “CulturaX: A cleaned, enormous, and multilingual dataset for large language models in 167 languages,” in Proc. Joint Int. Conf. Computational Linguistics, Language Resources and Evaluation, Torino, Italia, 2024, pp. 4226–4237.
|
| [171] |
D. Shi, T. Shen, Y. Huang, Z. Li, Y. Leng, R. Jin, C. Liu, X. Wu, Z. Guo, L. Yu, L. Shi, B. Jiang, and D. Xiong, “Large language model safety: A holistic survey,” arXiv preprint arXiv: 2412.17686, 2024.
|
| [172] |
X. Chen, C. Li, D. Wang, S. Wen, J. Zhang, S. Nepal, Y. Xiang, and K. Ren, “Android HIV: A study of repackaging malware for evading machine-learning detection,” IEEE Trans. Inf. Forensics Secur., vol. 15, pp. 987–1001, Jan. 2020. doi: 10.1109/TIFS.2019.2932228 |
| [173] |
W. Zhou, X. Zhu, Q.-L. Han, L. Li, X. Chen, S. Wen, and Y. Xiang, “The security of using large language models: A survey with emphasis on ChatGPT,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 1, pp. 1–26, Jan. 2025. doi: 10.1109/JAS.2024.124983 |
| [174] |
X. Zhu, W. Zhou, Q.-L. Han, W. Ma, S. Wen, and Y. Xiang, “When software security meets large language models: A survey,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 2, pp. 317–334, Feb. 2025. doi: 10.1109/JAS.2024.124971 |
| [175] |
C. Sheng, W. Zhou, Q. L. Han, W. Ma, X. Zhu, S. Wen, and Y. Xiang, “Network traffic fingerprinting for IIoT device identification: A survey,” IEEE Trans. Ind. Inf., 2025, DOI: 10.1109/TII.2025.3534441. |
| [176] |
X. Zhu, S. Wen, S. Camtepe, and Y. Xiang, “Fuzzing: A survey for roadmap,” ACM Comput. Surv., vol. 54, no. 11s, p. 230, Sep. 2022. doi: 10.1145/3512345 |
| [177] |
J. S. Butt, “Data, privacy, and the law: Safeguarding rights in the new millennium,” in Proc. 19th Int. Conf. European Integration-Realities and Perspectives, Galati, Romania, 2024, pp. 9–18.
|
| [178] |
L. Liu, O. De Vel, Q.-L. Han, J. Zhang, and Y. Xiang, “Detecting and preventing cyber insider threats: A survey,” IEEE Commun. Surv. Tutorials, vol. 20, no. 2, pp. 1397–1417, Apr.-Jun. 2018. doi: 10.1109/COMST.2018.2800740 |
| [179] |
D. Dhinakaran, S. M. U. Sankar, D. Selvaraj, and S. E. Raja, “Privacy-preserving data in IoT-based cloud systems: A comprehensive survey with AI integration,” arXiv preprint arXiv: 2401.00794, 2024.
|
| [180] |
J. Zhang, L. Pan, Q.-L. Han, C. Chen, S. Wen, and Y. Xiang, “Deep learning based attack detection for cyber-physical system cybersecurity: A survey,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 3, pp. 377–391, Mar. 2022. doi: 10.1109/JAS.2021.1004261 |
| [181] |
J. Qiu, J. Zhang, W. Luo, L. Pan, S. Nepal, and Y. Xiang, “A survey of android malware detection with deep neural models,” ACM Comput. Surv., vol. 53, no. 6, p. 126, Dec. 2020. doi: 10.1145/3417978 |
| [182] |
X. Feng, X. Zhu, Q.-L. Han, W. Zhou, S. Wen, and Y. Xiang, “Detecting vulnerability on IoT device firmware: A survey,” IEEE/CAA J. Autom. Sinica, vol. 10, no. 1, pp. 25–41, Jan. 2023. doi: 10.1109/JAS.2022.105860 |
| [183] |
T. Singh, H. Aditya, V. K. Madisetti, and A. Bahga, “Whispered tuning: Data privacy preservation in fine-tuning LLMs through differential privacy,” J. Software Eng. Appl., vol. 17, no. 1, pp. 1–22, Jan. 2024. doi: 10.4236/jsea.2024.171001 |
| [184] |
D. Rho, T. Kim, M. Park, J. W. Kim, H. Chae, E. K. Ryu, and J. H. Cheon, “Encryption-friendly LLM architecture,” in Proc. 13th Int. Conf. Learning Representations, 2025.
|
| [185] |
P. Voigt and A. Von dem Bussche, “The EU General Data Protection Regulation (GDPR): A Practical Guide,” Cham, Germany: Springer, 2017, pp. 10–5555.
|
| [186] |
R. Y. Wong, A. Chong, and R. C. Aspegren, “Privacy legislation as business risks: How GDPR and CCPA are represented in technology companies’ investment risk disclosures,” Proc. ACM on Hum.-Comput. Interact., vol. 7, no. CSCW1, pp. 82, Apr. 2023.
|
| [187] |
C.-C. Hsu, I.-Z. Wu, and S.-M. Liu, “Decoding AI complexity: SHAP textual explanations via LLM for improved model transparency,” in Proc. Int. Conf. Consumer Electronics-Taiwan, Taichung, China, 2024, pp. 197–198.
|
| [188] |
H. Zhao, H. Chen, F. Yang, N. Liu, H. Deng, H. Cai, S. Wang, D. Yin, and M. Du, “Explainability for large language models: A survey,” ACM Trans. Intell. Syst. Technol., vol. 15, no. 2, p. 20, Feb. 2024.
|
| [189] |
J. Ji, M. Liu, J. Dai, X. Pan, C. Zhang, C. Bian, B. Chen, R. Sun, Y. Wang, and Y. Yang, “BEAVERTAILS: Towards improved safety alignment of LLM via a human-preference dataset,” in Proc. 37th Int. Conf. Neural Information Processing Systems, New Orleans, USA, 2023, pp. 1072.
|
| [190] |
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases,” in Proc. 38th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2024, pp. 130185–130213.
|
| [191] |
B. Hannon, Y. Kumar, D. Gayle, J. J. Li, and P. Morreale, “Robust testing of AI language model resiliency with novel adversarial prompts,” Electronics, vol. 13, no. 5, p. 842, Feb. 2024. doi: 10.3390/electronics13050842 |
| [192] |
M. Chisnall, “Digital slavery, time for abolition?” Policy Stud., vol. 41, no. 5, pp. 488–506, Feb. 2020.
|




 DownLoad:
DownLoad:
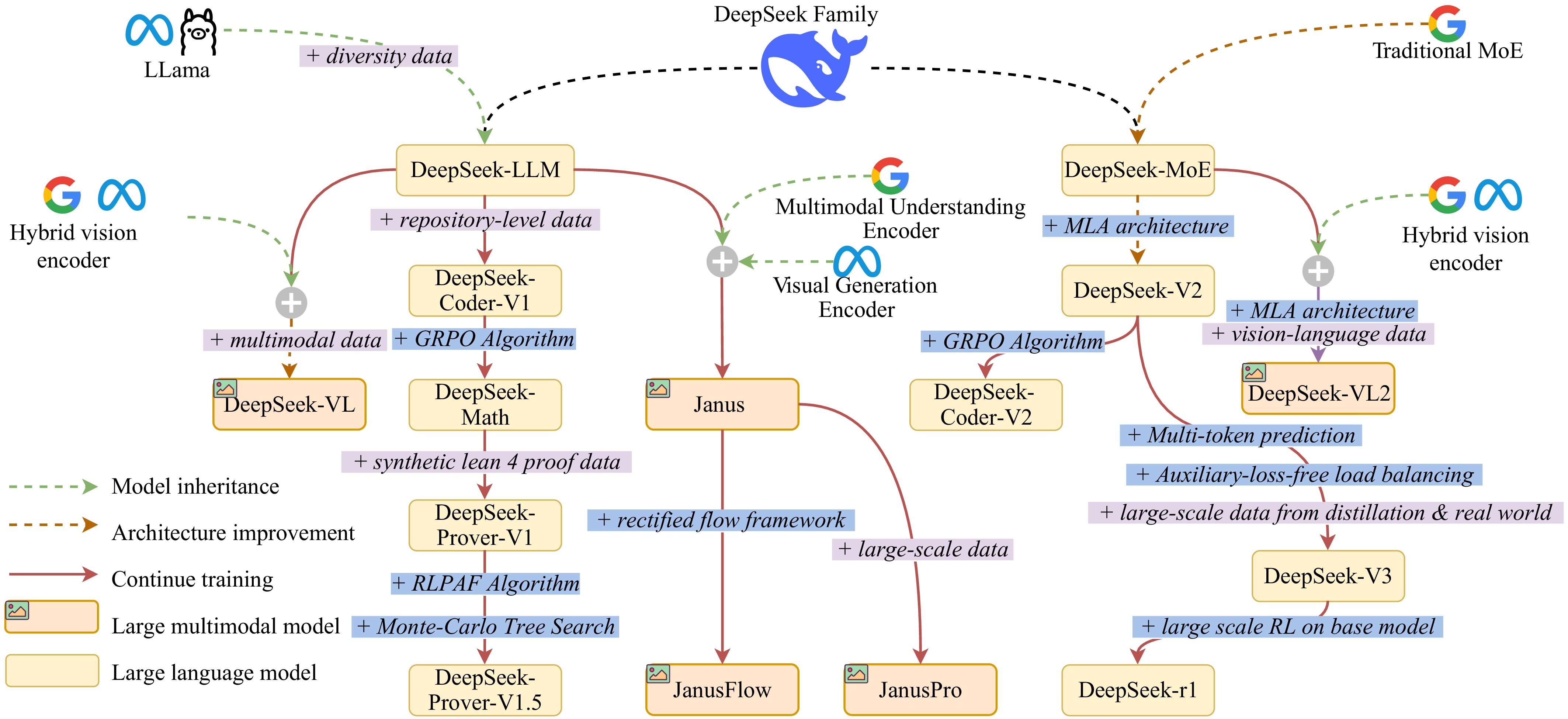
 DownLoad:
DownLoad:





 DownLoad:
DownLoad: