A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 11
Issue 4
Volume 11
Issue 4
IEEE/CAA Journal of Automatica Sinica
| Citation: | Y.-C. Li, R.-S. Jia, Y.-X. Hu, and H.-M. Sun, “A weakly-supervised crowd density estimation method based on two-stage linear feature calibration,” IEEE/CAA J. Autom. Sinica, vol. 11, no. 4, pp. 965–981, Apr. 2024. doi: 10.1109/JAS.2023.123960

|
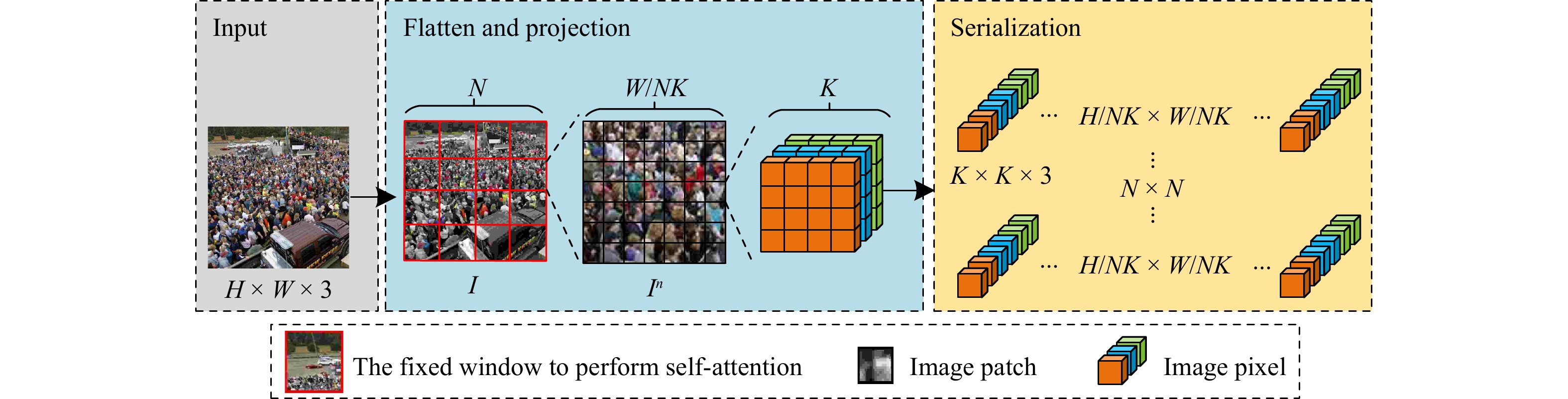
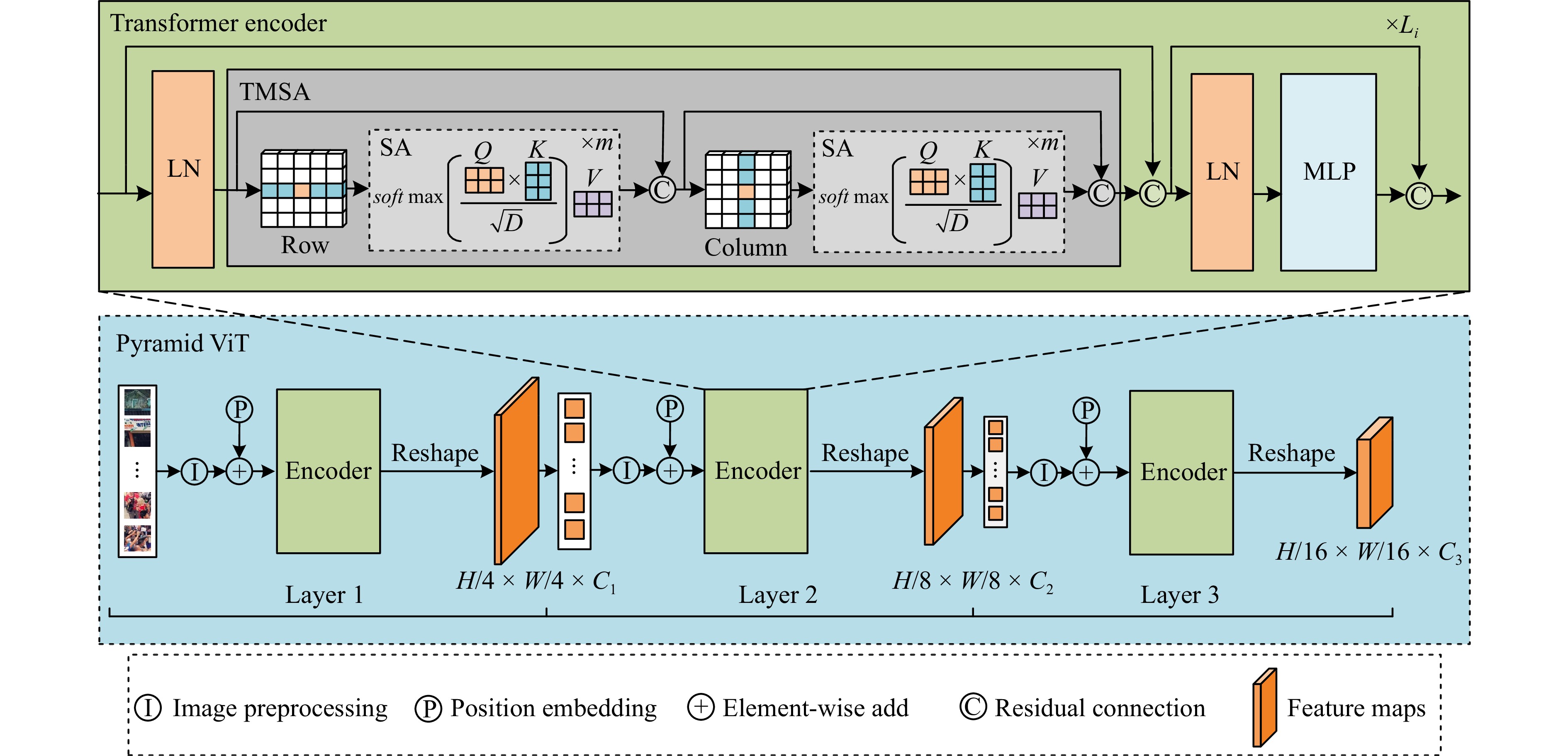
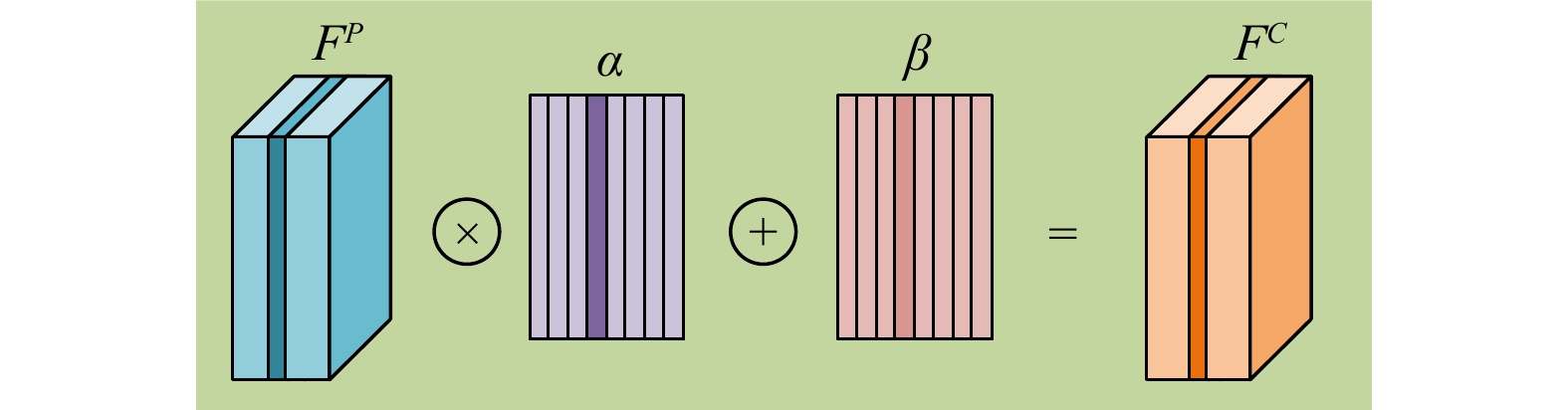
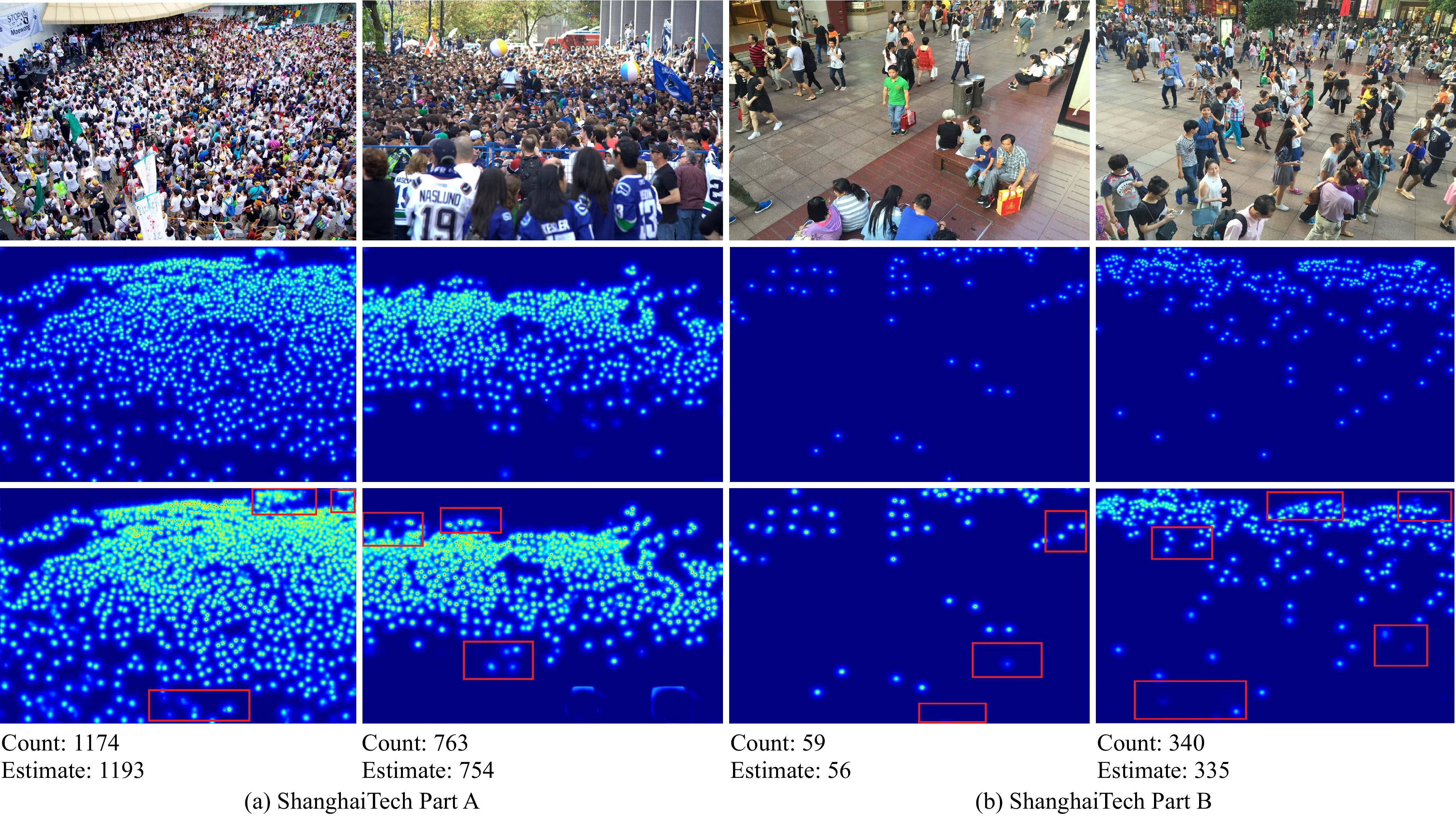
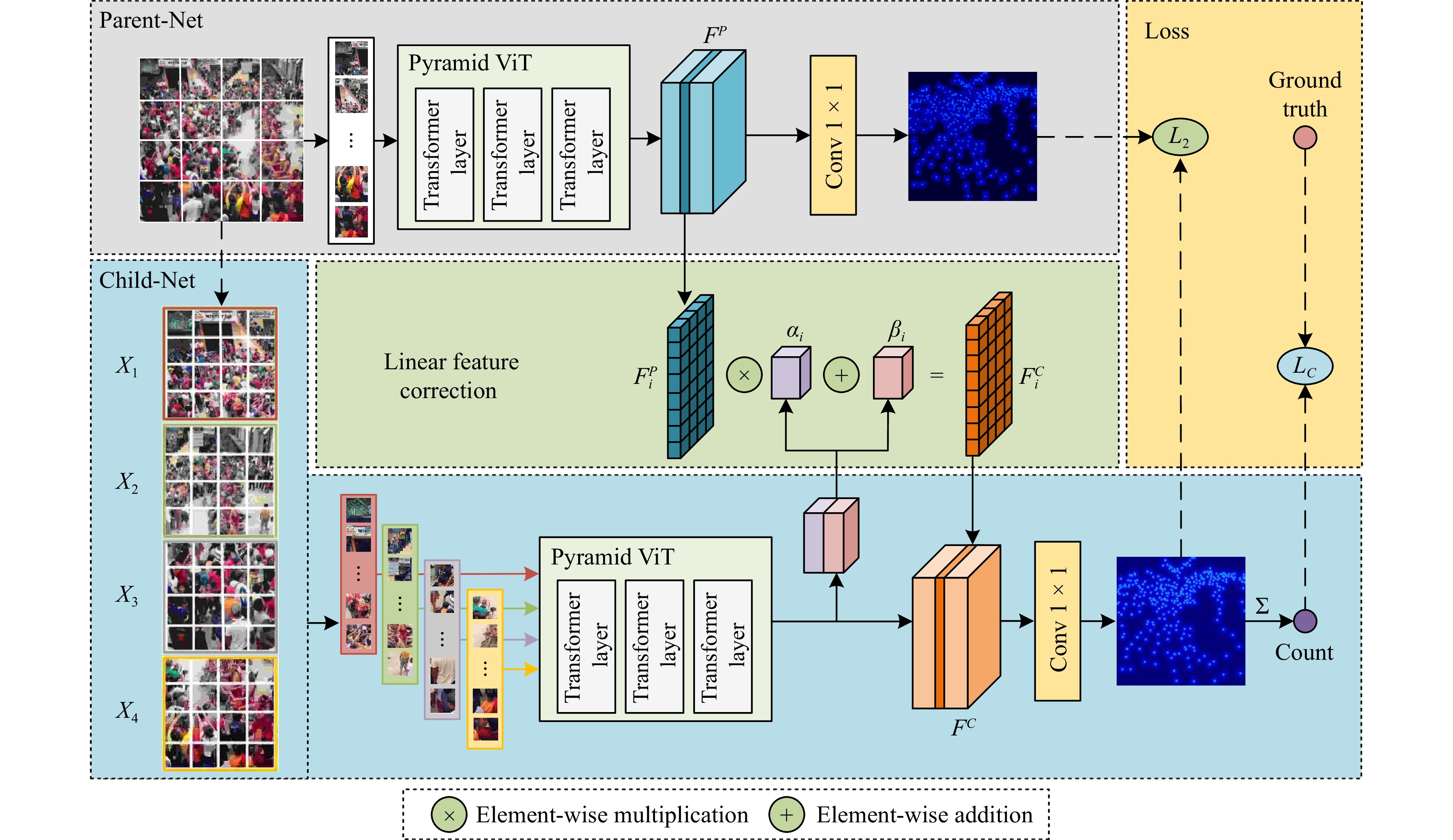
In a crowd density estimation dataset, the annotation of crowd locations is an extremely laborious task, and they are not taken into the evaluation metrics. In this paper, we aim to reduce the annotation cost of crowd datasets, and propose a crowd density estimation method based on weakly-supervised learning, in the absence of crowd position supervision information, which directly reduces the number of crowds by using the number of pedestrians in the image as the supervised information. For this purpose, we design a new training method, which exploits the correlation between global and local image features by incremental learning to train the network. Specifically, we design a parent-child network (PC-Net) focusing on the global and local image respectively, and propose a linear feature calibration structure to train the PC-Net simultaneously, and the child network learns feature transfer factors and feature bias weights, and uses the transfer factors and bias weights to linearly feature calibrate the features extracted from the Parent network, to improve the convergence of the network by using local features hidden in the crowd images. In addition, we use the pyramid vision transformer as the backbone of the PC-Net to extract crowd features at different levels, and design a global-local feature loss function (L2). We combine it with a crowd counting loss (LC) to enhance the sensitivity of the network to crowd features during the training process, which effectively improves the accuracy of crowd density estimation. The experimental results show that the PC-Net significantly reduces the gap between fully-supervised and weakly-supervised crowd density estimation, and outperforms the comparison methods on five datasets of ShanghaiTech Part A, ShanghaiTech Part B, UCF_CC_50, UCF_QNRF and JHU-CROWD++.

| [1] |
E. Walach and L. Wolf, “Learning to count with CNN boosting,” in Proc. 14th European Conf. Computer Vision, Amsterdam, The Netherlands, 2016, pp. 660–676.
|
| [2] |
C. Wang, H. Zhang, L. Yang, S. Liu, and X. Cao, “Deep people counting in extremely dense crowds,” in Proc. 23rd ACM Int. Conf. Multimedia, Brisbane, Australia, 2015, pp. 1299–130.
|
| [3] |
Y. Zhang, D. Zhou, S. Chen, S. Gao, and Y. Ma, “Single-image crowd counting via multi-column convolutional neural network,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Las Vegas, USA, 2016, pp. 589–597.
|
| [4] |
V. Sindagi and V. Patel, “Multi-level bottom-top and top-bottom feature fusion for crowd counting,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 1002–1012.
|
| [5] |
Y. Wang, S. Hu, G. Wang, C. Chen, and Z. Pan, “Multi-scale dilated convolution of convolutional neural network for crowd counting,” Multimed. Tools Appl., vol. 79, no. 1–2, pp. 1057–1073, Jan. 2020. doi: 10.1007/s11042-019-08208-6
|
| [6] |
V. A. Sindagi and V. M. Patel, “Generating high-quality crowd density maps using contextual pyramid CNNs,” in Proc. IEEE Int. Conf. Computer Vision, Venice, Italy, 2017, pp. 1879–1888.
|
| [7] |
D. Guo, K. Li, Z.-J. Zha, and M. Wang, “DADNet: Dilated-attention-deformable ConvNet for crowd counting,” in Proc. 27th ACM Int. Conf. Multimedia, Nice, France, 2019, pp. 1823–1832.
|
| [8] |
Y. Li, X. Zhang, and D. Chen, “CSRNet: Dilated convolutional neural networks for understanding the highly congested scenes,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018, pp. 1091–1100.
|
| [9] |
X. Cao, Z. Wang, Y. Zhao, and F. Su, “Scale aggregation network for accurate and efficient crowd counting,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 757–773.
|
| [10] |
X. Chen, Y. Bin, N. Sang, and C. Gao, “Scale pyramid network for crowd counting,” in Proc. IEEE Winter Conf. Applications Computer Vision, Waikoloa, USA, 2019, pp. 1941–1950.
|
| [11] |
L. Huang, S. Shen, L. Zhu, Q. Shi, and J. Zhang, “Context-aware multi-scale aggregation network for congested crowd counting,” Sensors, vol. 22, no. 9, p. 3233, Apr. 2022. doi: 10.3390/s22093233
|
| [12] |
X. Jiang, Z. Xiao, B. Zhang, X. Zhen, X. Cao, D. Doermann, and L. Shao, “Crowd counting and density estimation by trellis encoder-decoder networks,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 6126–6135.
|
| [13] |
Y.-C. Li, R.-S. Jia, Y.-X. Hu, D.-N. Han, and H.-M. Sun, “Crowd density estimation based on multi scale features fusion network with reverse attention mechanism,” Appl. Intell., vol. 52, no. 11, pp. 13097–13113, Sept. 2022. doi: 10.1007/s10489-022-03187-y
|
| [14] |
N. Liu, Y. Long, C. Zou, Q. Niu, L. Pan, and H. Wu, “ADCrowdNet: An attention-injective deformable convolutional network for crowd understanding,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 3220–3229.
|
| [15] |
A. Zhang, L. Yue, J. Shen, F. Zhu, X. Zhen, X. Cao, and L. Shao, “Attentional neural fields for crowd counting,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 5713–5722.
|
| [16] |
H. Chu, J. Tang, and H. Hu, “Attention guided feature pyramid network for crowd counting,” J. Vis. Commun. Image Represent., vol. 80, p. 103319, Oct. 2021. doi: 10.1016/j.jvcir.2021.103319
|
| [17] |
T. Lei, D. Zhang, R. Wang, S. Li, W. Zhang, and A. K. Nandi, “MFP-Net: Multi-scale feature pyramid network for crowd counting,” IET Image Process., vol. 15, no. 14, pp. 3522–3533, Dec. 2021. doi: 10.1049/ipr2.12230
|
| [18] |
S. Amirgholipour, W. Jia, L. Liu, X. Fan, D. Wang, and X. He, “PDANet: Pyramid density-aware attention based network for accurate crowd counting,” Neurocomputing, vol. 451, pp. 215–230, Sept. 2021. doi: 10.1016/j.neucom.2021.04.037
|
| [19] |
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16 × 16 words: Transformers for image recognition at scale,” in Proc. 9th Int. Conf. Learning Representations, 2021.
|
| [20] |
S. Yang, W. Guo, and Y. Ren, “CrowdFormer: An overlap patching vision transformer for top-down crowd counting,” in Proc. 31st Int. Joint Conf. Artificial Intelligence, Vienna, Austria, 2022, pp. 1545–1551.
|
| [21] |
D. Liang, X. Chen, W. Xu, Y. Zhou, and X. Bai, “Transcrowd: Weakly-supervised crowd counting with transformers,” Sci. China Inf. Sci., vol. 65, no. 6, p. 160104, Apr. 2022. doi: 10.1007/s11432-021-3445-y
|
| [22] |
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 548–558.
|
| [23] |
U. Sajid, X. Chen, H. Sajid, T. Kim, and G. Wang, “Audio-visual transformer based crowd counting,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 2249–2259.
|
| [24] |
G. Sun, Y. Liu, T. Probst, D. P. Paudel, N. Popovic, and L. Van Gool, “Boosting crowd counting with transformers,” arXiv preprint arXiv: 2105.10926, 2021.
|
| [25] |
P. T. Do, “Attention in crowd counting using the transformer and density map to improve counting result,” in Proc. 8th NAFOSTED Conf. Information and Computer Science, Hanoi, Vietnam, 2021, pp. 65–70.
|
| [26] |
X. Liu, J. van de Weijer, and A. D. Bagdanov, “Exploiting unlabeled data in CNNs by self-supervised learning to rank,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 8, pp. 1862–1878, Aug. 2019. doi: 10.1109/TPAMI.2019.2899857
|
| [27] |
Q. Wang, J. Gao, W. Lin, and Y. Yuan, “Learning from synthetic data for crowd counting in the wild,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 8190–8199.
|
| [28] |
G. Olmschenk, J. Chen, H. Tang, and Z. Zhu, “Dense crowd counting convolutional neural networks with minimal data using semi-supervised dual-goal generative adversarial networks,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition: Learning with Imperfect Data Workshop, 2019, pp. 21–28.
|
| [29] |
D. B. Sam, A. Agarwalla, J. Joseph, V. A. Sindagi, R. V. Babu, and V. M. Patel, “Completely self-supervised crowd counting via distribution matching,” in Proc. 17th European Conf. Computer Vision, Tel Aviv, Israel, 2022, pp. 186–204.
|
| [30] |
Z. Zhao, M. Shi, X. Zhao, and L. Li, “Active crowd counting with limited supervision,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 565–581.
|
| [31] |
Y. Liu, L. Liu, P. Wang, P. Zhang, and Y. Lei, “Semi-supervised crowd counting via self-training on surrogate tasks,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 242–259.
|
| [32] |
V. A. Sindagi, R. Yasarla, D. S. Babu, R. V. Babu, and V. M. Patel, “Learning to count in the crowd from limited labeled data,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 212–229.
|
| [33] |
Y. Lei, Y. Liu, P. Zhang, and L. Liu, “Towards using count-level weak supervision for crowd counting,” Pattern Recognit., vol. 109, p. 107616, Jan. 2021. doi: 10.1016/j.patcog.2020.107616
|
| [34] |
Y. Meng, H. Zhang, Y. Zhao, X. Yang, X. Qian, X. Huang, and Y. Zheng, “Spatial uncertainty-aware semi-supervised crowd counting,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 15529–15539.
|
| [35] |
S. Khaki, H. Pham, Y. Han, A. Kuhl, W. Kent, and L. Wang, “DeepCorn: A semi-supervised deep learning method for high-throughput image-based corn kernel counting and yield estimation,” Knowl. Based Syst., vol. 218, p. 106874, Apr. 2021. doi: 10.1016/j.knosys.2021.106874
|
| [36] |
D. B. Sam, N. N. Sajjan, H. Maurya, and R. V. Babu, “Almost unsupervised learning for dense crowd counting,” in Proc. 33rd AAAI Conf. Artificial Intelligence, Honolulu, USA, 2019, pp. 8868–8875.
|
| [37] |
M. von Borstel, M. Kandemir, P. Schmidt, M. K. Rao, K. Rajamani, and F. A. Hamprecht, “Gaussian process density counting from weak supervision,” in Proc. 14th European Conf. Computer Vision, Amsterdam, The Netherlands, 2016, pp. 365–380.
|
| [38] |
Z. Ma, X. Wei, X. Hong, and Y. Gong, “Bayesian loss for crowd count estimation with point supervision,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 6141–6150.
|
| [39] |
Y. Yang, G. Li, Z. Wu, L. Su, Q. Huang, and N. Sebe, “Weakly-supervised crowd counting learns from sorting rather than locations,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 1–17.
|
| [40] |
A. B. Chan, Z.-S. J. Liang, and N. Vasconcelos, “Privacy preserving crowd monitoring: Counting people without people models or tracking,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Anchorage, USA, 2008, 1–7.
|
| [41] |
B. Guo, Z. Wang, Z. Yu, Y. Wang, N. Y. Yen, R. Huang, and X. Zhou, “Mobile crowd sensing and computing: The review of an emerging human-powered sensing paradigm,” ACM Comput. Surv., vol. 48, no. 1, p. 7, Aug. 2015.
|
| [42] |
X. Sheng, J. Tang, X. Xiao, and G. Xue, “Leveraging GPS-less sensing scheduling for green mobile crowd sensing,” IEEE Internet Things J., vol. 1, no. 4, pp. 328–336, Aug. 2014. doi: 10.1109/JIOT.2014.2334271
|
| [43] |
C. Liu, X. Wen, and Y. Mu, “Recurrent attentive zooming for joint crowd counting and precise localization,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 1217–1226.
|
| [44] |
Z.-Q. Cheng, J.-X. Li, Q. Dai, X. Wu, and A. Hauptmann, “Learning spatial awareness to improve crowd counting,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 6151–6160.
|
| [45] |
V. S. Lempitsky and A. Zisserman, “Learning to count objects in images,” in Proc. 23rd Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2010, pp. 1324–1332.
|
| [46] |
L. Wen, D. Du, P. Zhu, Q. Hu, Q. Wang, L. Bo, and S. Lyu, “Drone-based joint density map estimation, localization and tracking with space-time multi-scale attention network,” arXiv preprint arXiv: 1912.01811, 2019.
|
| [47] |
Z. Zhuang, H. Tao, Y. Chen, V. Stojanovic, and W. Paszke, “An optimal iterative learning control approach for linear systems with nonuniform trial lengths under input constraints,” IEEE Trans. Syst. Man Cybern. Syst., vol. 53, no. 6, pp. 3461–3473, Jun. 2023. doi: 10.1109/TSMC.2022.3225381
|
| [48] |
X. Xin, Y. Tu, V. Stojanovic, H. Wang, K. Shi, S. He, and T. Pan, “Online reinforcement learning multiplayer non-zero sum games of continuous-time Markov jump linear systems,” Appl. Math. Comput., vol. 412, p. 126537, Jan. 2022.
|
| [49] |
C. Zhou, H. Tao, Y. Chen, V. Stojanovic, and W. Paszke, “Robust point-to-point iterative learning control for constrained systems: A minimum energy approach,” Int. J. Robust Nonlinear Control, vol. 32, no. 18, pp. 10139–10161, Dec. 2022. doi: 10.1002/rnc.6354
|
| [50] |
X. Song, N. Wu, S. Song, and V. Stojanovic, “Switching-like event-triggered state estimation for reaction–Diffusion neural networks against DoS attacks,” Neural Process. Lett., vol. 55, no. 7, pp. 8997–9018, Dec. 2023. doi: 10.1007/s11063-023-11189-1
|
| [51] |
W. Li, X. Luo, H. Yuan, and M. C. Zhou, “A momentum-accelerated Hessian-vector-based latent factor analysis model,” IEEE Trans. Serv. Comput., vol. 16, no. 2, pp. 830–844, Mar.–Apr. 2023. doi: 10.1109/TSC.2022.3177316
|
| [52] |
D. Wu, X. Luo, Y. He, and M. C. Zhou, “A prediction-sampling-based multilayer-structured latent factor model for accurate representation to high-dimensional and sparse data,” IEEE Trans. Neural Netw. Learn. Syst., 2022. DOI: 10.1109/TNNLS.2022.3200009
|
| [53] |
X. Luo, Y. Zhou, Z. Liu, L. Hu, and M. C. Zhou, “Generalized Nesterov’s acceleration-incorporated, non-negative and adaptive latent factor analysis,” IEEE Trans. Serv. Comput., vol. 15, no. 5, pp. 2809–2823, Sep.–Oct. 2022. doi: 10.1109/TSC.2021.3069108
|
| [54] |
D. Wu and X. Luo, “Robust latent factor analysis for precise representation of high-dimensional and sparse data,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 4, pp. 796–805, Apr. 2021. doi: 10.1109/JAS.2020.1003533
|
| [55] |
W. Zhao, M. Wang, Y. Liu, H. Lu, C. Xu, and L. Yao, “Generalizable crowd counting via diverse context style learning,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 8, pp. 5399–5410, Aug. 2022. doi: 10.1109/TCSVT.2022.3146459
|
| [56] |
F. Zhu, H. Yan, X. Chen, and T. Li, “Real-time crowd counting via lightweight scale-aware network,” Neurocomputing, vol. 472, pp. 54–67, Feb. 2022. doi: 10.1016/j.neucom.2021.11.099
|
| [57] |
J. T. Zhou, L. Zhang, J. Du, X. Peng, Z. Fang, Z. Xiao, and H. Zhu, “Locality-aware crowd counting,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 7, pp. 3602–3613, Jul. 2022.
|
| [58] |
C. Xu, D. Liang, Y. Xu, S. Bai, W. Zhan, X. Bai, and M. Tomizuka, “Autoscale: Learning to scale for crowd counting,” Int. J. Comput. Vis., vol. 130, no. 2, pp. 405–434, Feb. 2022. doi: 10.1007/s11263-021-01542-z
|
| [59] |
J. Zhang, “Knowledge learning with crowdsourcing: A brief review and systematic perspective,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 5, pp. 749–762, May 2022. doi: 10.1109/JAS.2022.105434
|
| [60] |
Z. Liu, N. Wu, Y. Qiao, and Z. Li, “Performance evaluation of public bus transportation by using DEA models and Shannon’s entropy: An example from a company in a large city of China,” IEEE/CAA J. Autom. Sinica, vol. 8, no. 4, pp. 779–795, Apr. 2021. doi: 10.1109/JAS.2020.1003405
|
| [61] |
Y. Zheng, Q. Li, C. Wang, X. Wang, and L. Hu, “Multi-source adaptive selection and fusion for pedestrian dead reckoning,” IEEE/CAA J. Autom. Sinica, vol. 9, no. 12, pp. 2174–2185, Dec. 2022. doi: 10.1109/JAS.2021.1004144
|
| [62] |
X. Deng, S. Chen, Y. Chen, and J.-F. Xu, “Multi-level convolutional transformer with adaptive ranking for semi-supervised crowd counting,” in Proc. 4th Int. Conf. Algorithms, Computing and Artificial Intelligence, Sanya, China, 2021, p. 2.
|
| [63] |
Y. Fang, B. Zhan, W. Cai, S. Gao, and B. Hu, “Locality-constrained spatial transformer network for video crowd counting,” in Proc. IEEE Int. Conf. Multimedia and Expo, Shanghai, China, 2019, pp. 814–819.
|
| [64] |
Y. Fang, S. Gao, J. Li, W. Luo, L. He, and B. Hu, “Multi-level feature fusion based locality-constrained spatial transformer network for video crowd counting,” Neurocomputing, vol. 392, pp. 98–107, Jun. 2020. doi: 10.1016/j.neucom.2020.01.087
|
| [65] |
Z. Wu, L. Liu, Y. Zhang, M. Mao, L. Lin, and G. Li, “Multimodal crowd counting with mutual attention transformers,” in Proc. IEEE Int. Conf. Multimedia and Expo, Taipei, China, 2022, pp. 1–6.
|
| [66] |
Q. Wang, T. Han, J. Gao, and Y. Yuan, “Neuron linear transformation: Modeling the domain shift for crowd counting,” IEEE Trans. Neural Netw. Learn. Syst., vol. 33, no. 8, pp. 3238–3250, Aug. 2022. doi: 10.1109/TNNLS.2021.3051371
|
| [67] |
D. Liang, W. Xu, Y. Zhu, and Zhou, Y, “Focal inverse distance transform maps for crowd localization,” IEEE Trans. Multimedia, vol. 25, pp. 6040–6052, 2023. doi: 10.1109/TMM.2022.3203870
|
| [68] |
H. Idrees, I. Saleemi, C. Seibert, and M. Shah, “Multi-source multi-scale counting in extremely dense crowd images,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, Portland, USA, 2013, pp. 2547–2554.
|
| [69] |
H. Idrees, M. Tayyab, K. Athrey, D. Zhang, S. Al-Maadeed, N. Rajpoot, and M. Shah, “Composition loss for counting, density map estimation and localization in dense crowds,” in Proc. 15th European Conf. Computer Vision, Munich, Germany, 2018, pp. 544–559.
|
| [70] |
V. A. Sindagi, R. Yasarla, and V. M. Patel, “JHU-CROWD++: Large-scale crowd counting dataset and a benchmark method,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 5, pp. 2594–2609, May 2022.
|
| [71] |
Z. Shi, P. Mettes, and C. Snoek, “Counting with focus for free,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Seoul, Korea (South), 2019, pp. 4199–4208.
|
| [72] |
J. Gao, Q. Wang, and X. Li, “PCC Net: Perspective crowd counting via spatial convolutional network,” IEEE Trans. Circuits Syst. Video Technol., vol. 30, no. 10, pp. 3486–3498, Oct. 2020. doi: 10.1109/TCSVT.2019.2919139
|
| [73] |
Y. Yang, G. Li, Z. Wu, L. Su, Q. Huang, and N. Sebe, “Reverse perspective network for perspective-aware object counting,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 4373–4382.
|
| [74] |
X. Jiang, L. Zhang, M. Xu, T. Zhang, P. Lv, B. Zhou, X. Yang, and Y. Pang, “Attention scaling for crowd counting,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Seattle, USA, 2020, pp. 4705–4714.
|
| [75] |
X. Liu, J. Yang, W. Ding, T. Wang, Z. Wang, and J. Xiong, “Adaptive mixture regression network with local counting map for crowd counting,” in Proc. 16th European Conf. Computer Vision, Glasgow, UK, 2020, pp. 241–257.
|
| [76] |
B. Wang, H. Liu, D. Samaras, and M. Hoai, “Distribution matching for crowd counting,” in Proc. 34th Int. Conf. Neural Information Processing Systems, Vancouver, Canada, 2020, p. 135.
|
| [77] |
J. Wan, Z. Liu, and A. B. Chan, “A generalized loss function for crowd counting and localization,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition, Nashville, USA, 2021, pp. 1974–1983.
|
| [78] |
Q. Wang, J. Gao, W. Lin, and Y. Yuan, “Pixel-wise crowd understanding via synthetic data,” Int. J. Comput. Vis., vol. 129, no. 1, pp. 225–245, Jan. 2021. doi: 10.1007/s11263-020-01365-4
|
| [79] |
Y. Liu, G. Cao, H. Shi, and Y. Hu, “LW-count: An effective lightweight encoding-decoding crowd counting network,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 10, pp. 6821–6834, Oct. 2022. doi: 10.1109/TCSVT.2022.3171235
|
| [80] |
J. Chen, K. Wang, W. Su, and Z. Wang, “SSR-HEF: Crowd counting with multiscale semantic refining and hard example focusing,” IEEE Trans. Industr. Inform., vol. 18, no. 10, pp. 6547–6557, Oct. 2022. doi: 10.1109/TII.2022.3160634
|
| [81] |
M. Wang, H. Cai, X.-F. Han, J. Zhou, and M. Gong, “STNet: Scale tree network with multi-level auxiliator for crowd counting,” IEEE Trans. Multimedia, vol. 25, pp. 2074–2084, 2023. doi: 10.1109/TMM.2022.3142398
|
| [82] |
X. Zhang, L. Han, W. Shan, X. Wang, S. Chen, C. Zhu, and B. Li, “A multi-scale feature fusion network with cascaded supervision for cross-scene crowd counting,” IEEE Trans. Instrum. Meas., vol. 72, p. 5007515, Feb. 2023.
|
| [83] |
Y. Chen, J. Yang, B. Chen, and S. Du, “Counting varying density crowds through density guided adaptive selection CNN and transformer estimation,” IEEE Trans. Circuits Syst. Video Technol., vol. 33, no. 3, pp. 1055–1068, Mar. 2023. doi: 10.1109/TCSVT.2022.3208714
|
| [84] |
V. K. Sharma, R. N. Mir, and C. Singh, “Scale-aware CNN for crowd density estimation and crowd behavior analysis,” Comput. Electr. Eng., vol. 106, p. 108569, Mar. 2023. doi: 10.1016/j.compeleceng.2022.108569
|
| [85] |
M.-H. Oh, P. Olsen, and K. N. Ramamurthy, “Crowd counting with decomposed uncertainty,” in Proc. 34th AAAI Conf. Artificial Intelligence, New York, USA, 2020, pp. 11799–11806.
|
| [86] |
B. Chen, Z. Yan, K. Li, P. Li, B. Wang, W. Zuo, and L. Zhang, “Variational attention: Propagating domain-specific knowledge for multi-domain learning in crowd counting,” in Proc. IEEE/CVF Int. Conf. Computer Vision, Montreal, Canada, 2021, pp. 16045–16055.
|
Figures(14) / Tables(6)






 DownLoad:
DownLoad: